프로젝트 리액터 코어 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
목차
- 9.1. Mutualizing Operator Usage
- 9.2. Hot Versus Cold
- 9.3. Broadcasting to Multiple Subscribers with
ConnectableFlux - 9.4. Three Sorts of Batching
- 9.5. Parallelizing Work with
ParallelFlux - 9.6. Replacing Default
Schedulers - 9.7. Using Global Hooks
- 9.8. Adding a Context to a Reactive Sequence
- 9.9. Dealing with Objects that Need Cleanup
- 9.10. Null Safety
이번 챕터는 아래 있는 리액터의 고급 기능과 그 개념을 다룬다:
- 연산자 호출 공통화하기
- Hot VS Cold
ConnectableFlux로 여러 구독자에게 브로드캐스팅하기- 배치 종류 세 가지
ParallelFlux로 병렬화하기- 디폴트
Scheduler바꾸기 - 글로벌 훅 사용하기
- 리액티브 시퀀스에 컨텍스트 추가하기
- Cleanup이 필요한 객체 다루기
- Null 안전성
9.1. Mutualizing Operator Usage
일반적인 클린 코드 관점에서 보면 코드를 재사용할 수 있으면 좋다. 리액터는 코드를 공통화해서 재사용할 수 있는 몇 가지 패턴을 제공한다. 이를 사용하면 자주 쓰는 연산자나 이 연산자 조합을 공통화할 수 있다. 즉, 자주 사용하는 연산자 체인을 연산자 “쿡북”으로 만들 수 있다.
9.1.1. Using the transform Operator
transform 연산자는 연산자 체인 일부를 하나의 함수로 캡슐화해 준다. 이 함수는 기존에 연결된 연산자 체인에 캡슐화한 연산자를 붙여준다. 이렇게 하면 시퀀스의 모든 구독자에 동일한 연산자를 적용하는데, 이는 기본적으로 직접 연산자를 체인에 추가하는 것과 동일하다. 예제는 아래 코드에 있다:
Function<Flux<String>, Flux<String>> filterAndMap =
f -> f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transform(filterAndMap)
.subscribe(d -> System.out.println("Subscriber to Transformed MapAndFilter: "+d));
다음 이미지는 transform 연산자가 흐름을 캡슐화하는 방식을 보여준다:
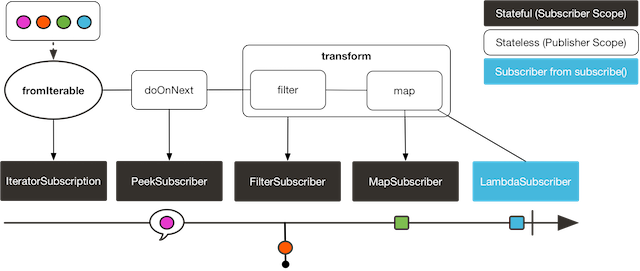
위 코드는 다음을 출력한다:
blue
Subscriber to Transformed MapAndFilter: BLUE
green
Subscriber to Transformed MapAndFilter: GREEN
orange
purple
Subscriber to Transformed MapAndFilter: PURPLE
9.1.2. Using the transformDeferred Operator
transformDeferred 연산자도 transform과 유사하게 연산자를 함수 하나로 캡슐화한다. 가장 큰 차이점은 구독자마다 따로 적용한다는 것이다. 이 말은, 실제로는 구독자마다 다른 연산자 체인을 만든다는 뜻이다 (어떤 상태를 유지함으로써). 예제는 아래 코드에 있다:
AtomicInteger ai = new AtomicInteger();
Function<Flux<String>, Flux<String>> filterAndMap = f -> {
if (ai.incrementAndGet() == 1) {
return f.filter(color -> !color.equals("orange"))
.map(String::toUpperCase);
}
return f.filter(color -> !color.equals("purple"))
.map(String::toUpperCase);
};
Flux<String> composedFlux =
Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.doOnNext(System.out::println)
.transformDeferred(filterAndMap);
composedFlux.subscribe(d -> System.out.println("Subscriber 1 to Composed MapAndFilter :"+d));
composedFlux.subscribe(d -> System.out.println("Subscriber 2 to Composed MapAndFilter: "+d));
다음 이미지는 transformDeferred 연산자가 구독자마다 따로 변환하는 방식을 보여준다:
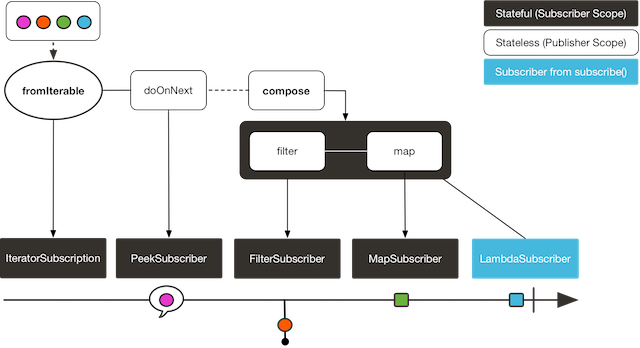
위 코드는 다음을 출력한다:
blue
Subscriber 1 to Composed MapAndFilter :BLUE
green
Subscriber 1 to Composed MapAndFilter :GREEN
orange
purple
Subscriber 1 to Composed MapAndFilter :PURPLE
blue
Subscriber 2 to Composed MapAndFilter: BLUE
green
Subscriber 2 to Composed MapAndFilter: GREEN
orange
Subscriber 2 to Composed MapAndFilter: ORANGE
purple
9.2. Hot Versus Cold
지금까지는 모든 Flux (혹은 Mono)가 동일하다고 간주했다: 모두 데이터의 비동기 시퀀스를 나타내며, 구독하기 전까지는 아무 일도 일어나지 않는다.
하지만 실제로는 publisher는 크게 두 가지로 나뉜다: hot과 cold.
앞의 예제 다룬 publiser는 cold에 속한다. 구독자마다 새 데이터를 만든다. 구독하지 않으면 데이터를 생성하지 않는다.
HTTP 요청을 생각해 보자. 구독자가 생길 때마다 HTTP 호출을 실행하지만, 아무도 결과에 관심이 없다면 HTTP 요청을 보내지 않는다.
반면 hot publisher는 구독자 수에 구애받지 않는다. 데이터 생산을 곧바로 시작하며, Subscriber가 언제 생기더라도 (이 경우엔 구독자는 구독 이후 방출한 새 데이터만 볼 수 있다) 계속 데이터 생산을 이어간다. 사실 hot publisher는, 구독하기 전에 무언가가 일어난다.
리액터에서 몇 안 되는 hot 연산자 중 하나는 just다: 단순히 체인에 연결될 때 값을 수집해 놓고 이후 구독하는 구독자에게 재전송한다. HTTP 호출에 다시 비유해보면, 수집한 데이터는 HTTP 호출 결과이고, 네트워크 호출은 just를 초기화할 때 딱 한 번만 발생한다.
just를 cold publisher로 변환하려면 defer를 사용하면 된다. 이는 HTTP 요청을 구독 시간으로 연기해 준다 (그리고 구독자가 생길 때마다 별도로 네트워크 호출을 실행한다).
리액터의 다른 hot publisher 대부분은
Processor를 상속하고 있다.
두 가지 예제를 살펴보자. 먼저 첫 번째 예제다:
Flux<String> source = Flux.fromIterable(Arrays.asList("blue", "green", "orange", "purple"))
.map(String::toUpperCase);
source.subscribe(d -> System.out.println("Subscriber 1: "+d));
source.subscribe(d -> System.out.println("Subscriber 2: "+d));
이 코드는 다음을 출력한다:
Subscriber 1: BLUE
Subscriber 1: GREEN
Subscriber 1: ORANGE
Subscriber 1: PURPLE
Subscriber 2: BLUE
Subscriber 2: GREEN
Subscriber 2: ORANGE
Subscriber 2: PURPLE
다음은 시퀀스를 재생산하는 것을 도식화한 그림이다:
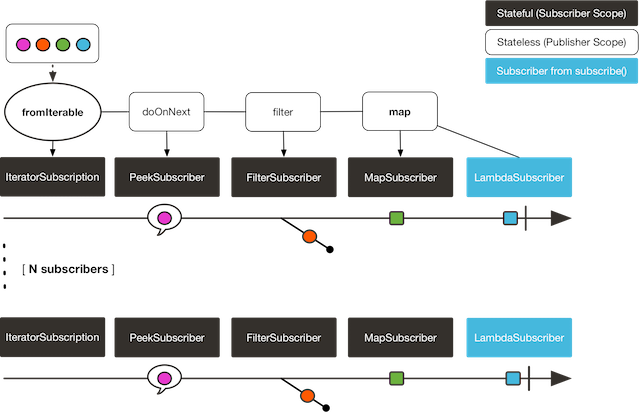
두 구독자 모두 Flux에 정의된 연산자를 실행시키기 때문에 네 가지 색깔을 전부 받는다.
위 예제를 아래 있는 두 번째 예제와 비교해 보자:
DirectProcessor<String> hotSource = DirectProcessor.create();
Flux<String> hotFlux = hotSource.map(String::toUpperCase);
hotFlux.subscribe(d -> System.out.println("Subscriber 1 to Hot Source: "+d));
hotSource.onNext("blue");
hotSource.onNext("green");
hotFlux.subscribe(d -> System.out.println("Subscriber 2 to Hot Source: "+d));
hotSource.onNext("orange");
hotSource.onNext("purple");
hotSource.onComplete();
두 번째 예제는 다음을 출력한다:
Subscriber 1 to Hot Source: BLUE
Subscriber 1 to Hot Source: GREEN
Subscriber 1 to Hot Source: ORANGE
Subscriber 2 to Hot Source: ORANGE
Subscriber 1 to Hot Source: PURPLE
Subscriber 2 to Hot Source: PURPLE
다음 이미지는 구독이 브로드캐스트되는 방식을 보여준다:
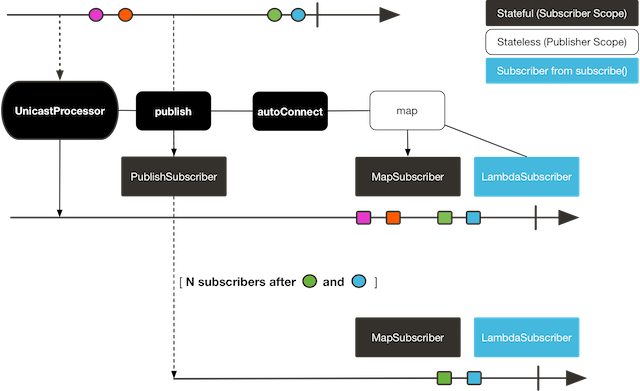
1번 구독자는 네 가지 색깔을 모두 전달받는다. 앞선 색깔 두 개를 생산한 이후에 구독한 두 번째 구독자는 남은 두 색깔만 받는다. 따라서 ORANGE와 PURPLE이 두 번씩 출력됐다. 이 Flux에 사용한 연산자는 구독한 시점과는 상관없이 실행된다.
9.3. Broadcasting to Multiple Subscribers with ConnectableFlux
가끔은 단순히 구독자가 구독할 때까지 일부 처리를 지연시키기보다, 미리 정해둔 시점에 구독과 데이터 생성을 트리거하고 싶을 수도 있다.
그렇기 때문에 ConnectableFlux가 있는 것이다. publish, replay 이 두 패턴으로 ConnectableFlux를 리턴하는 Flux API를 다룰 수 있다.
publish는 동적으로 여러 구독자가 보낸 demand를 소스로 전달함으로써 backpressure를 준수하려고 한다. 특히, 구독자 중 하나라도 demand가0으로 펜딩되고 있다면, publish는 소스에 요청을 중단한다.replay는 첫 번째 구독에서 받은 데이터를 설정한 제한값까지(시간과 버퍼 사이즈) 버퍼링한다. 이후 다른 구독자에게는 이 데이터를 재전송한다.
ConnectableFlux는 다운스트림과 소스 중간에서 구독을 관리할 수 있는 추가적인 메소드를 제공한다. 일부 메소드는 아래에서 설명한다:
connect()는Flux를 원하는 만큼 구독했을 때 수동으로 호출할 수 있다. 이는 업스트림 소스 구독을 트리거한다.autoConnect(n)는n개의 구독이 만들어지면 자동으로 같은 일을 해준다.refCount(n)는 들어오는 구독을 추적할 수 있을 뿐 아니라, 구독을 취소했을 때도 감지할 수 있다. 추적하는 구독자가 충분하지 않으면, 소스는 “연결 해제”되고 나중에 추가 구독자가 나타나면 이 소스를 새로 구독한다.refCount(int, Duration)는 “유예 기간”을 추가한다. 추적하는 구독자가 너무 적어지면, 새 구독자를 받아 이 연결 임계치를 넘길 수 있게, 소스를 연결 해제하기 전Duration동안 기다린다.
다음 예제를 살펴보자:
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
ConnectableFlux<Integer> co = source.publish();
co.subscribe(System.out::println, e -> {}, () -> {});
co.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("done subscribing");
Thread.sleep(500);
System.out.println("will now connect");
co.connect();
위 코드는 다음을 출력한다:
done subscribing
will now connect
subscribed to source
1
1
2
2
3
3
다음 코드는 autoConnect를 사용한다:
Flux<Integer> source = Flux.range(1, 3)
.doOnSubscribe(s -> System.out.println("subscribed to source"));
Flux<Integer> autoCo = source.publish().autoConnect(2);
autoCo.subscribe(System.out::println, e -> {}, () -> {});
System.out.println("subscribed first");
Thread.sleep(500);
System.out.println("subscribing second");
autoCo.subscribe(System.out::println, e -> {}, () -> {});
위 코드는 다음을 출력한다:
subscribed first
subscribing second
subscribed to source
1
1
2
2
3
3
9.4. Three Sorts of Batching
데이터가 많아서 배치로 분류하고 싶다면 리액터의 세 가지 광범위한 솔루션 grouping, windowing, buffering 중 하나를 사용해라. 이 셋은 모두 Flux<T>를 집계해서 재분배하기 때문에 개념적으로는 유사하다. Grouping과 windowing은 Flux<Flux<T>>를 만들고 buffering은 Collection<T>으로 집계한다.
9.4.1. Grouping with Flux<GroupedFlux<T>>
Grouping은 소스 Flux<T>를 각각의 키와 일치하는 배치 여러 개로 나누는 것을 말한다.
Grouping에 해당하는 집계 연산자는 groupBy다.
각 그룹은 GroupedFlux<T>로 표현하며, key() 메소드를 호출하면 키를 얻을 수 있다.
그룹 컨텐츠가 연속되어야 한다는 법은 없다. 소스에 있는 요소가 새 키를 만들면, 이 키에 해당하는 그룹이 열리고 키와 일치하는 요소는 결국 이 그룹에 들어간다 (동시에 여러 그룹이 열릴 수도 있다).
즉, 그룹은 다음과 같은 법칙을 따른다:
- 항상 분리돼 있다 (소스의 모든 아이템은 키 하나와 그룹 하나에만 속한다).
- 기존 시퀀스에선 떨어져 있던 아이템이 있을 수도 있다.
- 절대 비어있을 수 없다.
다음 예제는 짝수인지 홀수인지에 따라 그룹을 나눈다:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.groupBy(i -> i % 2 == 0 ? "even" : "odd")
.concatMap(g -> g.defaultIfEmpty(-1) //if empty groups, show them
.map(String::valueOf) //map to string
.startWith(g.key())) //start with the group's key
)
.expectNext("odd", "1", "3", "5", "11", "13")
.expectNext("even", "2", "4", "6", "12")
.verifyComplete();
Grouping은 그룹이 적거나 중간 정도일 때 가장 적합하다. 부득이하게 그룹도 컨슘해야 하기 때문에 (
flatMap등으로)groupBy는 계속해서 업스트림으로부터 데이터를 조회하고 그룹을 더해간다. 가끔 카디널리티가 큰 동시에 이 그룹을 컨슘하는flatMap의 동시성이 지나치게 낮을 땐 멈춘 것처럼 보일 수 있다.
9.4.2. Windowing with Flux<Flux<T>>
Windowing은 소스 Flux<T>를 윈도우로 나누는 것으로, 크기나 시간 또는 predicates, Publisher로 범위를 정의한다.
관련 연산자는 window, windowTimeout, windowUntil, windowWhile, windowWhen이다.
들어오는 키에 따라 무작위로 오버랩될 수 있는 groupBy와는 달리, 윈도우는 (대부분) 순차적으로 열린다.
하지만 일부 오버로딩 메소드는 윈도우를 오버랩할 수 있다. 예를 들어 window(int maxSize, int skip)에서 maxSize 파라미터는 윈도우를 닫은 이후의 아이템 수고, skip 파라미터는 새 윈도우를 열고 나서의 아이템 수다. 따라서 maxSize가 skip보다 크면 이전 윈도우를 닫기 전에 새 윈도우가 열리고 이 둘은 오버랩된다.
다음 예제는 윈도우를 오버랩하는 예제다:
StepVerifier.create(
Flux.range(1, 10)
.window(5, 3) //overlapping windows
.concatMap(g -> g.defaultIfEmpty(-1)) //show empty windows as -1
)
.expectNext(1, 2, 3, 4, 5)
.expectNext(4, 5, 6, 7, 8)
.expectNext(7, 8, 9, 10)
.expectNext(10)
.verifyComplete();
반대로 설정하면 (
maxSize<skip), 소스의 일부 아이템은 버려지고 어떤 윈도우에도 속하지 않는다.
windowUntil과 windowWhile을 통해 predicate로 윈도우를 정의하는 경우, predicate과 일치하지 않는 이후 아이템은 밑에 예제에서 보이는 것처럼 비어있는 윈도우를 만든다:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.windowWhile(i -> i % 2 == 0)
.concatMap(g -> g.defaultIfEmpty(-1))
)
.expectNext(-1, -1, -1) //respectively triggered by odd 1 3 5
.expectNext(2, 4, 6) // triggered by 11
.expectNext(12) // triggered by 13
// however, no empty completion window is emitted (would contain extra matching elements)
.verifyComplete();
9.4.3. Buffering with Flux<List<T>>
Buffering은 windowing과 유사하지만 한 가지가 다르다. 윈도우 (각각 Flux<T>를 가진) 대신 버퍼 (Collection<T> 형태 — 디폴트는 List<T>)를 방출한다.
buffering을 위한 연산자는 windowing과 거의 동일하다: buffer, bufferTimeout, bufferUntil, bufferWhile, bufferWhen.
windowing 연산자가 윈도우를 열 때, buffering 연산자는 새 컬렉션을 만들고 아이템을 더해가기 시작한다. 윈도우가 닫히는 곳에서는 buffering 연산자는 컬렉션을 방출한다.
아래 예제에서 확인할 수 있듯, buffering도 아이템을 버리거나 버퍼를 오버랩할 수 있다:
StepVerifier.create(
Flux.range(1, 10)
.buffer(5, 3) //overlapping buffers
)
.expectNext(Arrays.asList(1, 2, 3, 4, 5))
.expectNext(Arrays.asList(4, 5, 6, 7, 8))
.expectNext(Arrays.asList(7, 8, 9, 10))
.expectNext(Collections.singletonList(10))
.verifyComplete();
bufferUntil, bufferWhile은 windowing과는 다르게 비어 있는 버퍼를 방출하지 않는다:
StepVerifier.create(
Flux.just(1, 3, 5, 2, 4, 6, 11, 12, 13)
.bufferWhile(i -> i % 2 == 0)
)
.expectNext(Arrays.asList(2, 4, 6)) // triggered by 11
.expectNext(Collections.singletonList(12)) // triggered by 13
.verifyComplete();
9.5. Parallelizing Work with ParallelFlux
멀티 코어 아키텍처가 일상이 된 요즘에는 쉽게 병렬화할 수 있는 게 중요해졌다. 리액터는 병렬화 처리에 최적화된 연산자를 제공하는 특별한 타입, ParallelFlux를 제공한다.
어떤 Flux든지 parallel() 연산자를 사용하면 ParallelFlux를 얻을 수 있다. 이 자체로는 작업을 병렬화해주지 않는다. 그대신 작업 부하를 “레일(rail)”로 나눈다 (디폴트는 CPU 코어 수만큼).
건네받은 ParallelFlux에게 각 레일을 실행할 위치 (그리고 더 나아가 레일을 병렬로 실행할 위치)를 알려주려면 runOn(Scheduler)를 사용해야 한다. 병렬 처리를 위한 전용 Scheduler가 있다는 점을 알아 두자: Schedulers.parallel().
다음 두 예제를 비교해 보자:
Flux.range(1, 10)
.parallel(2) // (1)
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
(1) CPU 코어 수에 의존하는 대신 레일 수를 직접 지정한다.
Flux.range(1, 10)
.parallel(2)
.runOn(Schedulers.parallel())
.subscribe(i -> System.out.println(Thread.currentThread().getName() + " -> " + i));
첫 번째 예제는 다음을 출력한다:
main -> 1
main -> 2
main -> 3
main -> 4
main -> 5
main -> 6
main -> 7
main -> 8
main -> 9
main -> 10
두 번째 예제는 정확하게 두 스레드로 병렬화하고 다음을 출력한다:
parallel-1 -> 1
parallel-2 -> 2
parallel-1 -> 3
parallel-2 -> 4
parallel-1 -> 5
parallel-2 -> 6
parallel-1 -> 7
parallel-1 -> 9
parallel-2 -> 8
parallel-2 -> 10
시퀀스를 병렬로 처리하고 나서, 나머지 연산자 체인은 “일반” Flux로 돌아가 순차적으로 처리하고 싶다면 ParallelFlux의 sequential()을 호출하면 된다.
ParallelFlux를 Subscriber로 subscribe하면 sequential()이 적용되지만, subscribe의 다른 람다 기반 메소드를 사용하면 그렇지 않다는 것에 주의하라.
subscribe(Consumer<T>)는 모든 레일을 실행하는 반면, subscribe(Subscriber<T>)는 모든 레일을 머지한다는 것도 주의하자. subscribe() 메소드에 람다가 있으면, 레일 수만큼 각 람다를 실행한다.
groups() 메소드를 사용하면 각 레일 또는 “그룹”을 Flux<GroupedFlux<T>>로 접근할 수 있으며, composeGroup() 메소드로 다른 연산자를 추가할 수도 있다.
9.6. Replacing Default Schedulers
Threading and Schedulers 섹션에서 살펴본 것처럼, 리액터 코어는 몇 가지 Scheduler 구현체를 제공한다. 원한다면 언제든지 new* 팩토리 메소드를 사용해서 새 인스턴스를 만들 수 있지만, 각 Scheduler는 제마다의 디폴트 싱글톤 인스턴스를 가지고 있으며, 팩토리 메소드에서 직접 접근할 수 있다 (Schedulers.boundedElastic() vs Schedulers.newBoundedElastic(…) 등).
이 디폴트 인스턴스는, Scheduler가 필요한 연산자에 스케줄러를 지정하지 않았을 때도 사용된다. 예를 들어 Flux#delayElements(Duration)은 Schedulers.parallel() 인스턴스를 사용한다.
하지만 어떨 때는 일일이 Scheduler를 파라미터로 넘기는 대신, 이 디폴트 인스턴스를 횡단 관심사로 분리해서 다른 것으로 바꾸고 싶을 수 있다. 예를 들어 디버깅을 위해 실제 스케줄러를 래핑하고 스케줄링된 모든 태스크에 걸린 시간을 측정할 수 있다. 다시 말해, 디폴트 Scheduler를 바꾼다는 것이다.
디폴트 스케줄러는 Schedulers.Factory 클래스에서 변경할 수 있다. 기본적으로 Factory 클래스에 있는 메소드는 메소드 이름과 유사한 모든 표준 Scheduler를 만든다. 해당 메소드를 커스텀 구현체로 재정의하면 된다.
이 팩토리는 커스텀 메소드 decorateExecutorService를 추가로 제공한다. 이 메소드는 ScheduledExecutorService가 지원하는 모든 리액터 코어 Scheduler를 만들 때 실행된다 (Schedulers.newParallel()를 호출해서 만드는 등 디폴트 인스턴스가 아닐 때에도).
이를 통해 사용할 ScheduledExecutorService를 튜닝할 수 있다: 디폴트는 Supplier로 표현하며, 설정하는 Scheduler 타입에 따라 이 supplier를 완전히 우회해서 원하는 인스턴스를 리턴하거나, get()으로 디폴트 인스턴스를 가져와 래핑할 수도 있다.
요구사항에 맞는
Factory를 생성했다면 반드시Schedulers.setFactory(Factory)를 호출해야 적용된다.
마지막으로 Scheduler에는 커스텀할 수 있는 훅이 하나 더 있다: onHandleError. 이 훅은 Scheduler에 제출된 Runnable 태스크가 Exception을 던질 때마다 실행된다 (태스크를 실행하는 Thread에 UncaughtExceptionHandler가 설정돼 있다면, 핸들러와 훅 둘 다 실행한다).
9.7. Using Global Hooks
리액터는 다양한 상황에 리액터 연산자에서 실행할 또 다른 콜백을 설정할 수 있다. 이 콜백은 모두 Hooks 클래스로 설정하며, 세 카테고리로 나뉜다:
9.7.1. Dropping Hooks
Dropping 훅은 연산자의 소스가 리액티브 스트림 스펙을 지키지 않았을 때 실행한다. 이런 종류의 에러는 일반적인 실행 경로를 벗어난다 (즉, onError를 통해 전파할 수 없다).
전형적으로 onCompleted를 호출한 이후에 Publisher가 onNext를 호출하는 경우가 그렇다. 이때 onNext 값은 드랍된다. 관련 없는 onError 신호도 마찬가지다.
onNextDropped, onErrorDropped 훅을 사용하면 버려지는 신호를 컨슘할 글로벌 Consumer를 설정할 수 있다. 예를 들어 로그를 남긴 다음 필요하다면 관련 리소스를 정리할 수 있다 (남은 리액티브 체인에서도 절대 사용하지 않기 때문).
로(row) 하나에 훅을 두 번 설정하면 덮어 써지는 대신 그대로 더해진다 (additive). 즉, 제공한 모든 컨슈머를 실행한다. 훅은 Hooks.resetOn*Dropped() 메소드로 완전히 리셋시킬 수 있다.
9.7.2. Internal Error Hook
또 다른 훅 onOperatorError는 연산자의 onNext, onError, onComplete 메소드를 실행하는 동안 예상치 못한 Exception을 만났을 때 실행한다.
앞에서 본 훅과는 달리 일반적인 실행 경로에 속한다. 대표적인 예는 map 연산자에 Exception을 던지는 map 함수를 사용하는 경우다 (0으로 나누는 등). 이때는 평소처럼 onError 채널로 전달된다.
먼저 Exception을 onOperatorError로 전달한다. 훅을 통해 에러를 살펴본 뒤 (필요하다면 값을 증가시켜서) Exception을 바꿀 수 있다. 물론 로그를 남기고 기존 Exception을 리턴하는 것도 가능하다.
onOperatorError를 여러 번 설정하는 것도 가능하다. BiFunction을 식별할 String을 지정할 수 있으며, 다른 키를 사용해서 여러 번 호출하면 모든 훅을 연쇄적으로 실행한다. 반면 같은 키를 두 번 사용하면 이전에 설정한 함수를 덮어쓴다.
따라서 훅은 완전히 리셋할 수도 있고 (Hooks.resetOnOperatorError()), 특정 key만 리셋할 수도 있다 (Hooks.resetOnOperatorError(String)).
9.7.3. Assembly Hooks
Assembly 훅은 연산자의 생명 주기와 직결된다. 연산자 체인에 조립될 때 (즉 초기화할 때) 실행한다. onEachOperator를 사용하면 연산자 체인에 조립될 때, 다른 Publisher를 리턴해서 동적으로 각 연산자를 변경할 수 있다. onLastOperator도 유사하지만, subscribe를 호출하기 전 마지막 연산자에서만 실행된다.
횡단 관심사를 구현한 Subscriber로 모든 연산자를 장식하고 싶다면, Operators#lift* 메소드가 지원하는 다양한 리액터 Publisher 타입과 (Flux, Mono, ParallelFlux, GroupedFlux, ConnectableFlux) Fuseable 버전을 살펴봐라.
onOperatorError처럼 assembly 훅도 여러 개를 누적할 수 있으며 키로 식별한다. 부분적으로나 완전히 리셋하는 것도 가능하다.
9.7.4. Hook Presets
Hooks 유틸리티 클래스는 훅 프리셋을 제공한다. 훅을 직접 만드는 대신 아래 메소드 중 적당한 것을 호출해서 기본 동작을 바꿀 수 있다:
onNextDroppedFail(): 이전에는onNextDropped에서Exceptions.failWithCancel()예외를 던졌다. 지금 디폴트 동작은 값을 드랍하고 DEBUG 레벨 로그를 남기는 것이다. 이전처럼 예외를 던지려면onNextDroppedFail()을 사용해라.onOperatorDebug(): 이 메소드는 디버그 모드를 활성화한다. 이는onOperatorError훅을 연결하기 때문에resetOnOperatorError()를 호출하면 이 훅도 리셋된다.resetOnOperatorDebug()를 호출하면 내부적으로 특정 키를 사용하기 때문에 독립적으로 리셋시킬 수 있다.
9.8. Adding a Context to a Reactive Sequence
명령형 프로그래밍에서 리액티브 프로그래밍으로 사고방식을 전환할 때 만나는 기술적인 어려움 중 하나는 스레드 처리 방식에 있다.
리액티브 프로그래밍에선 Thread가 거의 동시에 (정확하겐 논블로킹 잠금 단계에서) 비동기 시퀀스를 처리하기 때문에, 익숙하기보단 오히려 그 정반대일 것이다. 실행 중에 자주, 그것도 쉽게 스레드 간 전환이 이루어진다.
이 때문에 ThreadLocal같이 더 “안정적인” 스레드 모델에 익숙한 개발자에겐 특히 더 어렵다. 이런 모델은 데이터를 스레드와 연결시켜 생각하게 만들기 때문에, 리액티브 컨텍스트 안에서 사용하긴 어렵다. 결과적으로 ThreadLocal에 의존하는 라이브러리는 리액터와 사용하면, 잘해도 결국 새로운 이슈를 직면하게 된다. 최악의 경우 잘못 동작하거나 심지어 실패할 수도 있다. 대표적으로 Logback의 MDC를 사용해서 관련 ID를 저장하고 함께 로깅하는 경우가 그렇다.
ThreadLocal을 해결하기 위해 보통 시도하는 방법은 시퀀스에 문맥 상의 데이터(C)를 비지니스 데이터(T)와 함께 사용하는 것이다 (예를 들어 Tuple2<T, C>). 사용하는 메소드와 Flux 시그니처에 관련 없는 관심사를 (컨텍스트 데이터) 노출하기 때문에 딱히 좋은 방법은 아니다.
리액터 3.1.0부터 다소 ThreadLocal과 비슷하지만, Thread대신 Flux나 Mono에 적용할 수 있는 고급 기능을 제공한다. 이 기능은 Context라 부른다.
다음 예제는 Context를 읽고 쓰는 사례를 보여준다:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "World"));
StepVerifier.create(r)
.expectNext("Hello World")
.verifyComplete();
아래 섹션에서 Context와 그 사용법을 읽고 나면 위 예제를 이해할 수 있을 것이다.
이는 일반 사용자보단 라이브러리 개발자를 타겟으로 둔 고급 기능이다. 이 기능을 사용하려면
Subscription의 생명 주기를 잘 이해하고 있어야 하며, 구독을 책임지는 라이브러리를 대상으로 만든 기능이다.
9.8.1. The Context API
Context 인터페이스를 보면 Map이 연상될 것이다. 키-값 쌍을 저장하며, 저장한 값은 키로 조회할 수 있다. 더 구체적으로는:
- 키와 값은 모두
Object타입이므로,Context인스턴스는 라이브러리와 소스마다 달라지는 모든 타입을 담을 수 있다. Context는 불변이다 (immutable).- 키-값 쌍을 저장할 때 사용하는
put(Object key, Object value)는 새Context인스턴스를 반환한다.putAll(Context)를 사용하면 두 컨텍스트를 새 컨텍스트로 머지할 수도 있다. - 키 존재 여부는
hasKey(Object key)로 확인할 수 있다. getOrDefault(Object key, T defaultValue)는 키에 해당하는 값을 가져오며 (T로 캐스팅),Context인스턴스에 이 키에 해당하는 값이 없으면 디폴트 값을 돌려준다.getOrEmpty(Object key)는Optional<T>을 반환한다 (Context인스턴스에 저장된 값이 있으면T로 캐스팅한다).delete(Object key)는 키에 해당하는 값을 삭제하며, 새Context를 반환한다.
Context를 만들 때, 스태틱 메소드Context.of을 사용하면 최대 다섯 개까지 키-값을 저장하고 있는Context인스턴스를 만들 수 있다.Object인스턴스를 2, 4, 6, 8, 10개 받는 메소드가 있으며, 각Object인스턴스 쌍은Context에 추가할 키-값 쌍이다.아니면
Context.empty()로 비어 있는Context를 만들 수도 있다.
9.8.2. Tying a Context to a Flux and Writing
Context를 제대로 활용하려면, 특정 시퀀스에 연결해서 체인에 있는 모든 연산자에서 접근할 수 있어야 한다. 주의할 점은, Context는 리액터에서 제공하기 때문에, Context에 접근하는 연산자는 리액터의 네이티브 연산자만 사용해야 한다.
사실 Context는 체인에 있는 각 Subscriber에 연결된다. Subscription 전파 메커니즘을 사용하기 때문에, 최종 subscribe에서부터 시작해서 체인 위로 전달되어 연산자에서도 접근할 수 있는 것이다.
Context를 전달하려면 구독 시점에 subscriberContext 연산자를 사용해야 한다.
subscriberContext(Context)는 제공한 Context와 다운스트림에서 받은 (Context는 체인 밑에서부터 위로 전파된다는 점을 기억하라) Context를 머지한다. 내부적으로는 putAll을 호출해서 업스트림에 새 Context를 전달한다.
subscriberContext(Function<Context, Context>)를 사용하면 좀 더 세밀하게 제어할 수 있다. 이 메소드를 사용하면, 다운스트림에서 받은Context에 원하는 값을 추가하거나 삭제해서 새Context를 리턴할 수 있다. 추천하는 방식은 아니지만, 원한다면 완전히 다른 인스턴스를 리턴하는 것도 가능하다 (Context에 의존하는 다른 외부 라이브러리에 영향을 줄 수 있다).
9.8.3. Reading a Context
Context를 전달하고 나면 데이터를 조회할 수 있다. Context에 정보를 집어넣는 건 대부분 엔드 사용자가 하는 일이지만, 정보 활용에 대한 책임은 보통 클라이언트 코드의 업스트림에 있는 서드 파티 라이브러리가 가지고 있다.
컨텍스트 정보를 읽을 땐 스태틱 메소드 Mono.subscriberContext()를 사용한다.
9.8.4. Simple Context Examples
이 섹션의 예제를 보고 나면 Context를 사용할 때 주의해야 할 점을 더 잘 이해할 수 있다.
먼저 도입부에서 보여줬던 간단한 예제로 돌아가서 좀 더 설명해 보겠다:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext() // (2)
.map( ctx -> s + " " + ctx.get(key))) // (3)
.subscriberContext(ctx -> ctx.put(key, "World")); // (1)
StepVerifier.create(r)
.expectNext("Hello World") // (4)
.verifyComplete();
(1) subscriberContext(Function)을 호출해 Context에 "message"라는 키 아래 "World"를 넣는 것으로 연산자 체인을 종료한다.
(2) 소스 아이템에 flatMap을 적용할 때 Mono.subscriberContext()로 Context를 얻어 온다.
(3) 그다음 map을 사용해서 "message"에 해당하는 키를 추출하고 기존 단어와 연결한다.
(4) 그 결과 Mono<String>은 "Hello World"를 방출한다.
위에 표시한 숫자와 선언 순서가 일치하지 않는 것은 실수가 아니다. 실행 순서를 나타낸 것이다.
subscriberContext는 체인 마지막에 있지만 가장 먼저 실행된다 (구독 시점이란 특성과 구독 신호는 아래에서 위로 흐른다는 사실 때문에).
연산자 체인에서
Context에 데이터를 담는 순서와 읽는 순서는 중요하다. 다음 예제에서 알 수 있듯이,Context는 불변이며,Context내 정보는 위에 있는 연산자에서만 볼 수 있다:
String key = "message";
Mono<String> r = Mono.just("Hello")
.subscriberContext(ctx -> ctx.put(key, "World")) // (1)
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.getOrDefault(key, "Stranger"))); // (2)
StepVerifier.create(r)
.expectNext("Hello Stranger") // (3)
.verifyComplete();
(1) Context를 체인 너무 위쪽에 사용했다.
(2) 결과적으로 flatMap은 키 값에 해당하는 값에 접근할 수 없다. 대신 디폴트 값을 사용한다.
(3) 따라서 Mono<String>은 "Hello Stranger"를 방출한다.
다음 예제를 통해서도 Context는 불변이며, Mono.subscriberContext()를 호출하면 어떻게 항상 호출하면서 설정한 Context를 리턴하는지를 알 수 있다:
String key = "message";
Mono<String> r = Mono.subscriberContext() // (1)
.map( ctx -> ctx.put(key, "Hello")) // (2)
.flatMap( ctx -> Mono.subscriberContext()) // (3)
.map( ctx -> ctx.getOrDefault(key,"Default")); // (4)
StepVerifier.create(r)
.expectNext("Default") // (5)
.verifyComplete();
(1) Context를 얻어 온다
(2) map에서 컨텍스트 변경을 시도한다
(3) flatmap에서 Context를 다시 얻는다
(4) Context에 변경하려고 했던 키를 조회한다
(5) 이 키 값은 절대 "Hello"로 세팅되지 않는다.
유사하게 Context에 동일한 키를 여러 번 쓴다면, 순서에 따라 달라질 수 있다. 다음 예제에서 알 수 있듯이, 연산자에서 Context를 읽을 때는 아래에 있는 가장 가까운 값을 건네받는다:
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key)))
.subscriberContext(ctx -> ctx.put(key, "Reactor")) // (1)
.subscriberContext(ctx -> ctx.put(key, "World")); // (2)
StepVerifier.create(r)
.expectNext("Hello Reactor") // (3)
.verifyComplete();
(1) "message" 키 값을 쓴다.
(2) 여기서도 "message" 키 값을 쓴다.
(3) map은 가장 가까운 곳에서 (바로 아래) 설정한 값을 전달받는다: "Reactor".
위 예제에선 구독할 때 Context에 "World"가 추가된다. 그다음 구독 신호가 위로 이동하면서 또 한 번 값을 쓰게 된다. 이때 "Reactor"를 가지고 있는 두 번째 불변 Context를 생성한다. 그다음 데이터 플로우가 시작된다. flatMap에선 가장 가까운 Context, 즉 "Reactor"를 가지고 있는 두 번째 Context를 조회한다.
Context가 데이터 신호와 함께 전파되는지 궁금할 것이다. 만약 그렇다면, 컨텍스트 값을 두 번 쓰면서 그 중간에 flatMap을 한 번 더 사용하면, 위에 있는 Context 값을 사용할 수도 있다. 하지만 아래 예제에서 보이는 것처럼, 실제로는 그렇지 않다.
String key = "message";
Mono<String> r = Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))) // (3)
.subscriberContext(ctx -> ctx.put(key, "Reactor")) // (2)
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))) // (4)
.subscriberContext(ctx -> ctx.put(key, "World")); // (1)
StepVerifier.create(r)
.expectNext("Hello Reactor World") // (5)
.verifyComplete();
(1) 여기서 처음으로 값을 쓴다.
(2) 두 번째로 값을 쓴다.
(3) 첫 번째 flatMap은 두 번째로 썼던 컨텍스트를 조회한다.
(4) 두 번째 flatMap은 첫 번째 결과에, 첫 번째로 썼던 컨텍스트 값을 연결한다.
(5) Mono는 "Hello Reactor World"를 방출한다.
그 이유는 Context는 Subscriber와 연관 있으며, 각 연산자에선 접근할 Context를 다운스트림 Subscriber에 요청하기 때문이다.
마지막으로 살펴볼 사례는 flatMap 안쪽에서도 Context에 값을 쓰는 케이스다:
String key = "message";
Mono<String> r =
Mono.just("Hello")
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))
)
.flatMap( s -> Mono.subscriberContext()
.map( ctx -> s + " " + ctx.get(key))
.subscriberContext(ctx -> ctx.put(key, "Reactor")) // (1)
)
.subscriberContext(ctx -> ctx.put(key, "World")); // (2)
StepVerifier.create(r)
.expectNext("Hello World Reactor")
.verifyComplete();
(1) 여기 subscriberContext는 flatMap 바깥에는 아무 영향도 주지 않는다.
(2) 여기 subscriberContext는 메인 시퀀스의 Context에 영향을 준다.
위 예제에서 최종적으로 방출하는 값은 “Hello Reactor World”가 아니라 "Hello World Reactor"다. "Reactor"를 쓰는 subscriberContext는 두 번째 flatMap 내부 시퀀스에만 적용되기 때문이다. 결과적으로 메인 시퀀스로 전파되지 않으며, 첫 번째 flatMap에서는 이 값을 볼 수 없다. 전파와 불변이라는 특성 때문에 Context는 flatMap처럼 중간 내부 시퀀스를 만드는 연산자와는 분리된다.
9.8.5. Full Example
이제 Context에서 정보를 조회하는 좀 더 현실적인 라이브러리 예시를 살펴보자: 건네받은 Mono<String>을 데이터 소스로 사용해 PUT 요청을 보내는 리액티브 HTTP 클라이언트. 요청 헤더에 관련 ID를 추가하기 위해 컨텍스트에서 특정 키 값을 조회할 것이다.
사용자 관점에서는 작성하는 코드는 다음과 같다:
doPut("www.example.com", Mono.just("Walter"))
관련 ID를 전파려면 다음과 같이 작성할 것이다:
doPut("www.example.com", Mono.just("Walter"))
.subscriberContext(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
사용자는 subscriberContext를 사용해서 HTTP_CORRELATION_ID 키-값 쌍을 가진 Context를 만든다. 이 연산자의 업스트림은 HTTP 클라이언트 라이브러리가 리턴하는 Mono<Tuple2<Integer, String>>이다 (HTTP 응답을 단순화했다). 따라서 실제로 사용자 코드에서 라이브러리 코드로 정보를 전달한다.
다음은 컨텍스트를 읽어 ID를 찾으면 “요청에 추가하는” 라이브러리 관점의 목 코드다:
static final String HTTP_CORRELATION_ID = "reactive.http.library.correlationId";
Mono<Tuple2<Integer, String>> doPut(String url, Mono<String> data) {
Mono<Tuple2<String, Optional<Object>>> dataAndContext =
data.zipWith(Mono.subscriberContext() // (1)
.map(c -> c.getOrEmpty(HTTP_CORRELATION_ID))); // (2)
return dataAndContext
.<String>handle((dac, sink) -> {
if (dac.getT2().isPresent()) { // (3)
sink.next("PUT <" + dac.getT1() + "> sent to " + url + " with header X-Correlation-ID = " + dac.getT2().get());
}
else {
sink.next("PUT <" + dac.getT1() + "> sent to " + url);
}
sink.complete();
})
.map(msg -> Tuples.of(200, msg));
}
(1) Mono.subscriberContext()로 Context를 얻는다.
(2) ID 키에 해당하는 값을 Optional로 추출한다.
(3) 컨텍스트에 키가 존재하면 헤더의 ID로 사용한다.
이 라이브러리 코드는 데이터 Mono를 Mono.subscriberContext()와 합친다. 이는 Tuple2<String, Context>로 합쳐지며, 컨텍스트에는 다운스트림에서 보낸 HTTP_CORRELATION_ID 엔트리가 들어있다 (구독자에 직접 연결된 것처럼).
그다음 map으로 키에 해당하는 값을 Optional<String>으로 추출하고, 엔트리가 있으면 X-Correlation-ID 헤더 값에 전달한다. 마지막은 handle에서 시연한다.
ID 사용을 검증하는 전체 테스트 코드는 다음과 같이 작성할 수 있다:
@Test
public void contextForLibraryReactivePut() {
Mono<String> put = doPut("www.example.com", Mono.just("Walter"))
.subscriberContext(Context.of(HTTP_CORRELATION_ID, "2-j3r9afaf92j-afkaf"))
.filter(t -> t.getT1() < 300)
.map(Tuple2::getT2);
StepVerifier.create(put)
.expectNext("PUT <Walter> sent to www.example.com with header X-Correlation-ID = 2-j3r9afaf92j-afkaf")
.verifyComplete();
}
9.9. Dealing with Objects that Need Cleanup
매우 특이 케이스긴 하지만, 어플리케이션에서 사용하는 객체를 더 이상 사용하지 않는다면 어떤 방식으로든 cleanup해줘야 할 때가 있다. 참조를 카운팅하고 있는 객체나 힙 바깥에서 관리하는 객체 등의 고급 시나리오에 해당한다. 네티의 ByteBuf가 이 둘에 해당하는 대표적인 예시이다.
이런 객체를 제대로 cleanup하려면 글로벌 훅뿐 아니라 (Using Global Hooks 참고), Flux 별로도 고려해볼 필요가 있다:
doOnDiscardFlux/Mono연산자onOperatorError훅onNextDropped훅- 연산자별 핸들러
각 훅은 모든 cleanup 시나리오를 다 고려해서 만들어지지 않았으며, 사용자는 (예를 들어) onOperatorError에 특정 에러 처리 로직과 cleanup 로직을 함께 구현하고 싶을 수도 있기 때문이다.
일부 연산자는 cleanup이 필요한 객체에 적합하지 않다는 것에 주의하라. 예를 들어 bufferWhen은 오버랩된 버퍼를 만들 수 있으며, 앞에서 사용한 discard “로컬 훅”이 첫 번째 버퍼는 버려지는 것으로 보고, 두 번째 버퍼와 겹치는 아이템을 유효한데도 cleanup해버릴 수 있다.
cleanup이 목적이라면 모든 연산자는 멱등성을 보장해야 한다. 같은 객체에 여러 번 적용하는 경우가 그렇다. 클래스 레벨
instanceOf을 체크하는doOnDiscard연산자와는 달리, 글로벌 훅은 어떤Object도 될 수 있는 인스턴스를 처리한다. 이는 사용자가 어떤 인스턴스를 cleanup하고 하지 않을지를 구현하는 방식에 달려있다.
9.9.1. The doOnDiscard Operator or Local Hook
사용자 코드에서 접근할 수 없는 객체를 cleanup하기 위한 훅이다. 일반적인 플로우에서 cleanup할 때 사용한다 (아이템을 너무 많이 푸쉬하는 등 비정상적인 소스는 onNextDropped로 처리한다).
연산자를 통해 활성화되며, 주어진 Flux나 Mono에만 적용되기 때문에 로컬 훅이라고 할 수 있다.
업스트림의 아이템을 필터링하는 연산자를 사용한다면 이는 더 명백해진다. 이 아이템은 다음 연산자에 (혹은 최종 구독자에게) 전달되지 않지만, 정상적인 실행 경로라고 볼 수 있다. 따라서 필터링한 아이템도 doOnDiscard 훅에 전달된다. 다음과 같은 경우에 doOnDiscard를 사용할 수 있다:
filter: 필터 조건에 일치하지 않은 아이템은 “폐기”할 것으로 간주한다.skip: 건너뛴 아이템을 폐기한다.buffer(maxSize, skip)withmaxSize < skip: “폐기할 버퍼” — 버퍼 사이에 있는 아이템을 폐기한다.
doOnDiscard는 필터링 연산자만 가능한 것은 아니며, 내부적으로 backpressure 용으로 데이터 큐를 사용하는 연산자에서도 사용할 수 있다. 더 구체적으로 말하면, 대부분 취소할 때가 중요하다. 소스에서 데이터를 미리 가져와서 이후에 구독자 demand에 따라 데이터를 보내는 연산자는, 취소했을 때 아직 방출하지 않은 데이터를 가지고 있을 수 있다. 이런 연산자는 취소할 때 doOnDiscard 훅을 사용해서 내부 backpressure Queue를 비운다.
doOnDiscard(Class, Consumer)를 호출할 때마다 덮어쓰지 않고 더해지지만 (additive), 업스트림 연산자에만 적용된다.
9.9.2. The onOperatorError hook
onOperatorError는 에러를 선회하는 방식으로 수정하기 위한 훅이다 (AOP의 catch-and-rethrow와 유사하다).
onNext 신호를 처리하는 동안 에러가 발생하면 방출하고 있던 아이템을 onOperatorError로 전달한다.
cleanup이 필요한 아이템이라면 onOperatorError에 이를 구현하되, 가능하면 오류 재작성 코드 위에 작성하라.
9.9.3. The onNextDropped Hook
Publisher가 비정상일 땐, 연산자에서 아이템을 받을 타이밍이 아닐 때도 아이템을 보낼 수도 있다 (전형적으로 onError나 onComplete 신호 이후에). 이런 경우엔 이 아이템을 “drop”한다. — 즉, onNextDropped 훅으로 전달한다. 이때 아이템을 cleanup해야 한다면 onNextDropped 훅을 구현해야 한다.
9.9.4. Operator-specific Handlers
연산 중에 버퍼를 사용하거나 값을 수집하는 일부 연산자는, 수집한 데이터가 다운스트림으로 전파되지 않았을 때를 대비하는 핸들러가 있다. 이런 연산자를 cleanup이 필요한 객체와 함께 사용한다면 핸들러에서 cleanup을 수행해야 한다.
예를 들어 distinct는 아이템이 유일한지 아닌지 판단하기 위해 컬렉션을 사용하며, 연산자를 종료할 때 (또는 취소되면) 콜백을 실행해서 이 컬렉션을 비운다. 디폴트 컬렉션은 HashSet이며, cleanup 콜백은 HashSet::clear다. 하지만 사용하는 객체의 참조를 카운트하고 있다면, clear()를 호출하기 전 각 아이템을 놓아줄 수 있는(release) 핸들러로 변경하고 싶을 수 있다.
9.10. Null Safety
자바의 타입 시스템에서는 널을 안전하게 표현할 수 있는 방법이 없지만, 이제 리액터는 스프링 프레임워크 5와 유사하게 API의 널 가능 여부를 선언할 수 있는 어노테이션을 제공한다.
리액터에서 이 어노테이션을 사용하지만, 모든 리액터 기반 자바 프로젝트에서도 똑같이 null-safe API를 선언할 수 있다. 메소드 내부에서 사용하는 타입에 대한 널 체크는 이 기능 범위를 벗어난다.
이 어노테이션은 JSR 305 어노테이션을 선언하고 있기 때문에 (IntelliJ IDEA 등의 툴에서 지원하는, 현재는 추가 개발이 진행되지 않는 JSR), 자바 개발자는 런타임 NullPointerException을 방지하기 위한 null-safety 관련 경고를 볼 수 있다. JSR 305 메타 어노테이션 덕분에 툴 벤더는 리액터 어노테이션 전용 하드 코딩 없이, 일반적인 방식으로 null safety를 지원할 수 있다.
코틀린 1.1.5+에선 클래스패스에 JSR 305 의존성을 추가할 필요가 없으며, 권장하지도 않는다.
자체적으로 null safety를 지원하는 코틀린과도 사용할 수 있다. 자세한 내용은 전용 섹션을 참고하라.
다음은 reactor.util.annotation 패키지에서 제공하는 어노테이션이다:
@NonNull: 특정 파라미터나 리턴 값, 필드가null일 수 없음을 나타낸다. (@NonNullApi를 사용하면 파라미터나 리턴 값에는 생략해도 된다)@Nullable: 파라미터나, 리턴 값, 필드가null일 수 있음을 나타낸다.@NonNullApi: 패키지 레벨 어노테이션으로, 파라미터와 리턴 값의 기본 동작은 non-null임을 나타낸다.
제네릭 타입 인자, 가변 인자, 배열 요소는 아직 Nullability를 지원하지 않는다. 최신 정보는 issue #878을 참고하라.
“Advanced Features and Concepts” 수정 제안하기
Next :Appendix A Which operator do I need
리액터의 연산자 선택 가이드를 한글로 번역했습니다.
전체 목차는 여기에 있습니다.