프로젝트 리액터 코어 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
목차
- 4.1.
Flux, an Asynchronous Sequence of 0-N Items - 4.2.
Mono, an Asynchronous 0-1 Result - 4.3. Simple Ways to Create a Flux or Mono and Subscribe to It
- 4.4. Programmatically creating a sequence
- 4.5. Threading and Schedulers
- 4.6. Handling Errors
- 4.7. Processors
reactor-core는 리액터 프로젝트의 핵심 아티팩트로, 리액티브 스트림 스펙을 기본으로 자바 8을 타겟팅한 리액티브 라이브러리다.
리액터를 사용하면 Publisher를 구현하고 있는 리액티브 타입을 (Flux, Mono) 다양하게 구성할 수 있으며, 풍부한 연산자를 함께 제공한다. Flux 객체는 0~N개의 요소가 있는 리액티브 시퀀스를, Mono 객체는 결과가 단일 값 또는 빈 값 (0~1)일 때를 나타낸다.
이 둘은 비동기 처리에 대략적인 카디널리티 정보를 담는 식으로 타입을 구분한다. 예를 들어 HTTP 요청은 응답을 하나만 생성하기 때문에 굳이 count 연산을 실행할 필요가 없다. 이런 HTTP 호출 결과를 Mono<HttpResponse>로 표현하면 아이템이 0~1개일 때 사용할만한 연산자만 제공하기 때문에 Flux<HttpResponse>로 표현하는 것보다 더 낫다.
최대 카디널리티를 바꿔 주는 연산자로 타입을 변환할 수도 있다. 예를 들어 Flux엔 count 연산자가 있는데, Mono<Long>을 리턴한다.
4.1. Flux, an Asynchronous Sequence of 0-N Items
다음은 Flux가 아이템을 변환하는 방법을 도식화한 그림이다:
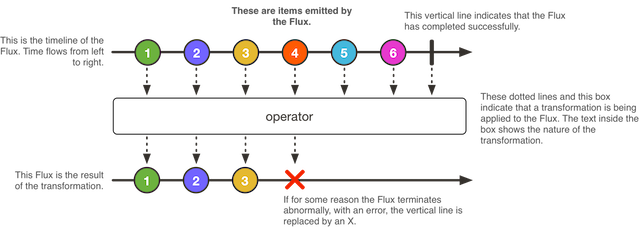
Flux<T>는 0개부터 N개까지의 아이템을 생산하는 비동기 시퀀스를 나타내는 표준 Publisher<T>로, 완료나 에러 신호로 종료된다. 리액티브 스트림 스펙에 따르면, 시퀀스를 종료시키는 신호는 다운스트림에 있는 구독자의 onNext, onComplete, onError 메소드 호출로 이어진다.
Flux는 범용적인 리액티브 타입으로, 다양한 신호를 전달할 수 있다. 종료 이벤트를 포함한 모든 이벤트는 선택 사항이다: onNext 이벤트 없이 onComplete 이벤트만 있으면 비어 있는 유한한 시퀀스를 의미하지만, onComplete를 제거하면 비어 있는 무한 시퀀스를 나타낸다 (취소 관련 테스트할 때를 빼면 딱히 유용하진 않음). 마찬가지로 무한 시퀀스는 꼭 비어있어야 한다는 법은 없다. 예를 들어, Flux.interval(Duration)은 일정한 시간 값을 방출하는 무한한 Flux<Long>을 생산한다.
4.2. Mono, an Asynchronous 0-1 Result
다음은 Mono가 아이템을 변환하는 방법을 도식화한 그림이다:
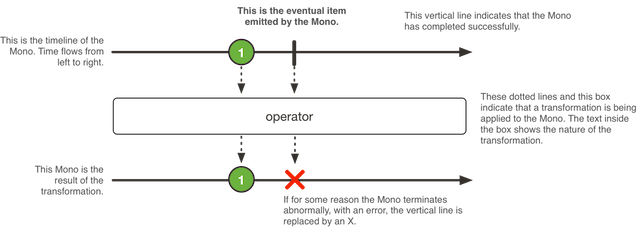
Mono<T>는 최대 1개의 아이템 생산에 특화된 Publisher<T>로, onComplete 또는 onError 신호로 종료된다 (선택적).
Flux가 지원하는 모든 연산자를 다 제공하진 않지만, 일부 연산자를 사용하면 (특히 Mono와 다른 Publisher를 합쳐주는) Flux로 전환할 수 있다. 예를 들어 Mono#then(Mono)는 다른 Mono를 반환하지만 Mono#concatWith(Publisher)는 Flux를 반환한다.
Mono로 값은 필요 없고 완료 개념만 있으면 되는(Runnable과 유사) 비동기 처리도 표현할 수 있다. 비어있는 Mono<Void>를 사용해 만들면 된다.
4.3. Simple Ways to Create a Flux or Mono and Subscribe to It
Flux와 Mono를 시작하는 가장 쉬운 방법은 팩토리 메소드 중 하나로 각 클래스를 생성하는 것이다.
예를 들어, String의 시퀀스는 아래처럼 단순히 나열하거나 또는 컬렉션에 담은 채로 Flux를 만들 수 있다:
Flux<String> seq1 = Flux.just("foo", "bar", "foobar");
List<String> iterable = Arrays.asList("foo", "bar", "foobar");
Flux<String> seq2 = Flux.fromIterable(iterable);
팩토리 메소드를 사용하는 다른 방법은 아래 예제를 참고하라:
Mono<String> noData = Mono.empty(); // (1)
Mono<String> data = Mono.just("foo");
Flux<Integer> numbersFromFiveToSeven = Flux.range(5, 3); // (2)
(1) 팩토리 메소드는 값이 없어도 제네릭 타입이 필요하다는 점에 주의하라.
(2) 첫 번째 파라미터는 시작 값이고 두 번째 파라미터는 생산할 아이템 수다.
Flux와 Mono를 구독할 땐 자바 8 람다를 사용한다. .subscribe()는 아래 메소드 시그니처에서 보이는 것처럼, 람다를 다양한 형태로 받기 때문에 여러 가지 콜백을 조합할 수 있다.
Example 10. Lambda-based subscribe variants for Flux
subscribe(); // (1)
subscribe(Consumer<? super T> consumer); // (2)
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer); // (3)
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer); // (4)
subscribe(Consumer<? super T> consumer,
Consumer<? super Throwable> errorConsumer,
Runnable completeConsumer,
Consumer<? super Subscription> subscriptionConsumer); // (5)
(1) 구독하고 시퀀스를 트리거한다.
(2) 생산된 각 데이터에 무언가를 한다.
(3) 데이터 처리도 하고 에러에도 반응하다.
(4) 데이터와 에러를 처리하면서, 시퀀스가 성공적으로 완료됐을 때 특정 코드를 실행한다.
(5) 데이터, 에러도 처리하고, 성공적으로 완료했을 때도 뭔가를 처리하면서, 이 subscribe 호출로 생성되는 Subscription을 가지고 무언가를 한다.
이 메소드들은 구독에 대한 참조를 리턴하기 때문에 더 이상 데이터가 필요 없을 때 구독을 취소할 수 있다. 구독을 취소하면 소스는 데이터 생산을 중단하고 생산한 모든 리소스를 제거해야 한다. 리액터에선 범용
Disposable인터페이스로 이 cancel-and-clean-up 동작을 표현한다.
4.3.1. subscribe Method Examples
이번 섹션에서는 다섯 가지 subscribe 메소드를 사용하는 최소한의 예제만 제시한다. 아래는 인자를 받지 않는 기본 메소드를 사용하는 예제다:
Flux<Integer> ints = Flux.range(1, 3); // (1)
ints.subscribe(); // (2)
(1) 구독자가 생기면 값 3개를 생산하는 Flux를 세팅한다.
(2) 가장 단순한 방법으로 구독한다.
위 코드를 실행하면 결과물을 눈으로 확인할 수는 없지만, 문제없이 동작한다. Flux는 값 3개를 생산한다. 람다를 넘기면 이 값을 조회할 수 있다. 다음 예제는 subscribe 메소드를 사용해서 값을 보여주는 한 가지 방법을 보여준다:
Flux<Integer> ints = Flux.range(1, 3); // (1)
ints.subscribe(i -> System.out.println(i)); // (2)
(1) 구독자가 생기면 값 3개를 생산하는 Flux를 세팅한다.
(2) 값을 출력하는 구독자로 구독한다.
위 코드를 실행하면 다음을 출력한다:
1
2
3
이제, 다른 입력을 받는 메소드를 설명하기 위해 다음과 같이 의도적으로 에러를 발생시킬 것이다:
Flux<Integer> ints = Flux.range(1, 4) // (1)
.map(i -> { // (2)
if (i <= 3) return i; // (3)
throw new RuntimeException("Got to 4"); // (4)
});
ints.subscribe(i -> System.out.println(i), // (5)
error -> System.err.println("Error: " + error));
(1) 구독자가 생기면 값 4개를 생산하는 Flux를 세팅한다.
(2) 값을 다른 방식으로 처리하기 위해 map을 사용한다.
(3) 값 대부분은 그대로 리턴한다.
(4) 값 하나에서만 강제로 에러를 발생시킨다.
(5) 에러 핸들러를 가지고 있는 구독자로 구독한다.
여기엔 기존 데이터를 위한 람다 표현식과, 에러 처리를 위한 람다 표현식 두 개가 있다. 위 코드는 다음을 출력한다:
1
2
3
Error: java.lang.RuntimeException: Got to 4
이어서 설명할 subscribe 메소드는 에러 핸들러와 완료 이벤트 핸들러를 둘 다 받는다:
Flux<Integer> ints = Flux.range(1, 4); // (1)
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> System.out.println("Done")); // (2)
(1) 구독자가 생기면 값 4개를 생산하는 Flux를 세팅한다.
(2) 완료 이벤트 핸들러를 가지고 있는 구독자로 구독한다.
에러 신호와 완료 신호는 모두 종료 이벤트이며, 상호 배타적이다 (둘 다 받을 수는 없다). 완료 컨슈머가 잘 동작하려면 에러가 발생하지 않도록 주의해야 한다.
완료 콜백은 입력이 없기 때문에 빈 괄호로 표현한다: Runnable 인터페이스의 run 메소드와 동일하다. 위 코드는 다음을 출력한다:
1
2
3
4
Done
마지막으로 다룰 subscribe 메소드는 Consumer<Subscription>을 받는다.
이 메소드는
Subscription으로 무언가를 해야 한다는 뜻이다 (request(long)을 실행하거나cancel()로 구독을 취소하거나). 그렇지 않으면Flux는 멈춰 있다.
다음은 이 마지막 subscribe 메소드를 사용하는 예제다:
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> System.out.println("Done"),
sub -> sub.request(10)); // (1)
(1) 구독을 시작하면 Subscription을 건네받는다. 데이터 소스로부터 최대 10개까지 받겠다는 신호를 보낸다 (실제론 값 4개를 방출하고 완료한다).
4.3.2. Cancelling a subscribe() with Its Disposable
람다 기반 subscribe() 메소드는 모두 Disposable 타입을 리턴한다. 여기서 Disposable 인터페이스는 dispose() 메소드 호출로 구독을 취소할 수 있음을 의미한다.
Flux, Mono 관점에서 취소는 소스가 데이터 생산을 중단해야 한다는 신호다. 단, 즉각적인 중단을 보장하진 않는다: 데이터 소스가 취소 명령을 받기 전에 데이터를 생산하고 완료 처리할 수도 있다.
Disposables 클래스에는 Disposable 관련 유틸리티가 있다. 이 중 Disposables.swap()은 Disposable 래퍼를 생성해서 기존 Disposable을 자동으로 취소하고 다른 걸로 바꿀 수 있다. 예를 들어 사용자가 UI 버튼을 클릭하면 요청을 취소하고 새 요청으로 대체하고 싶은 경우에 유용하게 쓸 수 있다. 래퍼를 폐기하면 자체적으로 close한다. 이렇게 하면 현재 구현체와 이후에 대체하는 모든 구현체를 폐기한다.
Disposables.composite(…)도 꽤 흥미롭다. composite은 여러 Disposable을 수집해서 (예를 들어 서비스 호출과 관련해서 처리 중인 여러 요청들) 나중에 한 번에 폐기할 수 있다. 이 composite의 dispose() 메소드를 호출하고 나면 다른 Disposable을 추가할 때마다 즉시 폐기한다.
4.3.3. An Alternative to Lambdas: BaseSubscriber
subscribe 메소드에 람다를 직접 조합하는 방식 대신, 필요한 모든 것을 갖추고 있는 좀 더 일반적인 Subscriber를 넘길 수도 있다. Subscriber를 좀 더 쉽게 작성할 수 있도록, 확장 가능한 BaseSubscriber 클래스를 제공한다.
BaseSubscriber(혹은 하위 클래스)의 인스턴스는 일회용이기 때문에, 다른Publisher를 구독하면 이전Publisher구독을 취소한다. 인스턴스를 두 번 사용하면,Subscriber의onNext메소드는 병렬로 호출해선 안된다는 리액티브 스트림 규칙에 어긋나기 때문이다. 따라서 익명 구현체는Publisher#subscribe(Subscriber)호출하면서 직접 선언할 때만 사용하는 게 좋다.
이제 이 중 하나를 구현해보자. 이 구현체를 SampleSubscriber라고 부르겠다. 다음 예제는 Flux에 연결하는 방법을 보여준다:
SampleSubscriber<Integer> ss = new SampleSubscriber<Integer>();
Flux<Integer> ints = Flux.range(1, 4);
ints.subscribe(i -> System.out.println(i),
error -> System.err.println("Error " + error),
() -> {System.out.println("Done");},
s -> s.request(10));
ints.subscribe(ss);
다음은 BaseSubscriber를 최소한으로 구현한 SampleSubscriber 정의다:
package io.projectreactor.samples;
import org.reactivestreams.Subscription;
import reactor.core.publisher.BaseSubscriber;
public class SampleSubscriber<T> extends BaseSubscriber<T> {
public void hookOnSubscribe(Subscription subscription) {
System.out.println("Subscribed");
request(1);
}
public void hookOnNext(T value) {
System.out.println(value);
request(1);
}
}
SampleSubscriber 클래스는 리액터에서 Subscriber를 직접 정의할 때 권장하는 추상 클래스 BaseSubscriber를 상속하고 있다. 이 클래스는 구독자 행동을 재정의할 수 있는 훅을 제공한다. 기본적으로 무한대로 요청을 트리거하며, 이는 subscribe()와 완전히 동일하다. 요청할 양을 커스텀하고 싶으면 BaseSubscriber를 상속하는 게 훨씬 더 유용하다.
요청량을 커스텀하려면 최소한 위 예제처럼 hookOnSubscribe(Subscription subscription)과 hookOnNext(T value)를 구현해야 한다. 여기서는 hookOnSubscribe 메소드에서 첫 번째 요청을 만들기 전 표준 출력으로 상태를 출력한다. 그다음 hookOnNext 메소드에선 상태를 출력하고 한 번에 하나씩 요청을 추가로 보낸다.
이 SampleSubscriber는 다음을 출력한다:
Subscribed
1
2
3
4
BaseSubscriber는 cancle() 메소드뿐 아니라 언바운드 모드로(request(Long.MAX_VALUE)와 동일함) 전환할 수 있는 requestUnbounded() 메소드도 제공한다.
그 외 다른 훅은 hookOnComplete, hookOnError, hookOnCancel, hookFinally(시퀀스가 종료되면 종료 타입을 나타내는 SignalType 파라미터와 함께 항상 호출되는)가 있다.
분명 대부분은
hookOnError,hookOnCancel,hookOnComplete메소드를 구현하고 싶을 것이다.hookFinally메소드도 구현해야 할 수 있다.SampleSubscribe는 유한한 요청을 처리하기 위한Subscriber의 최소한의 구현체일 뿐이다.
4.3.4. On Backpressure and Ways to Reshape Requests
컨슈머 압력을 소스로 다시 전파하는 backpressure를, 리액터에선 업스트림 연산자로 request를 보내는 식으로 구현했다. 현재의 모든 요청을 합쳐서 종종 현재 “demand” 또는 “pending request”라고 부른다. Demand는 언바운드 요청을 나타내는 Long.MAX_VALUE로 제한한다 (“가능한 빨리 생산하라”는 뜻 — 기본적으로 backpressure를 비활성화한다).
첫 요청은 구독하는 타이밍에 구독자 쪽에서 보내는데, 모든 데이터를 직접적으로 즉시 구독하면 Long.MAX_VALUE의 언바운드 요청을 트리거링한다:
subscribe()및 람다 기반 오버로딩 메소드 대부분 (Consumer<Subscription>를 받는 메소드는 예외)block(),blockFirst(),blockLast()toIterable()나toStream()으로 순회
기존 요청을 커스텀하는 가장 쉬운 방법은 다음 예제처럼 BaseSubscriber의 hookOnSubscribe 메소드를 재정의해서 subscribe하는 것이다:
Flux.range(1, 10)
.doOnRequest(r -> System.out.println("request of " + r))
.subscribe(new BaseSubscriber<Integer>() {
@Override
public void hookOnSubscribe(Subscription subscription) {
request(1);
}
@Override
public void hookOnNext(Integer integer) {
System.out.println("Cancelling after having received " + integer);
cancel();
}
});
위 코드는 다음을 출력한다:
request of 1
Cancelling after having received 1
요청을 조작한다면, 최소한 시퀀스를 진행할 수 있을 만큼 demand를 생산해야 함에 주의하라. 그렇지 않으면 Flux가 오도 가도 못하는 상황이 벌어질 수 있다. 이러한 이유로
BaseSubscriber의hookOnSubscribe는 언바운드 요청을 기본으로 하고 있다. 이 훅을 재정의한다면 보통 최소한 한 번은request를 호출해야 한다.
Operators that Change the Demand from Downstream
구독할 때 표현한 demand는 업스트림 체인에서 연산자로 재구성될 수 있다는 점에 주의하라. 대표적으로 buffer(N) 연산자가 그렇다: request(2)를 받으면, 꽉 찬 버퍼 2개를 요구한 것으로 해석한다. 결과적으로 버퍼는 N개의 요소가 있어야 꽉 찬 것으로 간주하기 때문에 buffer 연산자는 이 요청을 2 x N으로 재구성한다.
일부 연산자는 prefetch라는 int 값을 입력 파라미터로 받도록 오버라이딩돼 있는 것을 알아챘을 수도 있다. 이는 다운스트림 요청을 수정하는 또 다른 양상의 연산자다. 보통 내부 시퀀스를 처리하고 들어오는 각 요소로 Publisher를 만드는 연산자들이 그렇다 (flatMap 등).
이 내부 시퀀스에서 만드는 첫 번째 요청은 Prefetch로 수정할 수 있다. 명시하지 않으면 연산자 대부분은 demand 32로 시작한다.
일반적으로 이런 연산자는 보충 최적화(replenishing optimization)를 구현하고 있다: 연산자가 prefetch 요청의 75%를 완료하고 나면, 다시 업스트림에 75%를 요청한다. 즉, 처리해 나가면서 최적화하기 때문에 앞으로의 요청을 미리 예측할 수 있다.
마지막으로 limitRate, limitRequest 연산자로 직접 요청을 튜닝할 수 있다.
limitRate(N)은 다운스트림 요청을 분할해서 업스트림엔 더 작은 배치로 전파한다. 예를 들어, limitRate(10)에 100을 요청하면, 업스트림으로 10 요청을 최대 10개 전파한다. 이때 limitRate은 앞서 다룬 보충 최적화를 실제로 구현하고 있다.
limitRate(highTide, lowTide)는 보충할 양을 (이 메소드에선 lowTide로 표현함) 조정할 수도 있다. lowTide를 0으로 보내면 보충 전략으로 배치 양을 조정하는 대신, 정확히 highTide 만큼 요청하는 배치를 만든다.
반면 limitRequest(N)은 다운스트림 요청을 최대 total demand 만큼으로 제한한다. 이는 요청을 N까지 추가한다. 단일 request에서 total demand가 N을 넘기지 않으면, 이 요청은 전부 업스트림으로 전파된다. 데이터 소스가 그만큼 데이터를 방출하고 나면 limitRequest는 시퀀스가 완료된 것으로 간주하고, 다운스트림으로 onComplete를 보내 데이터 소스를 취소한다.
4.4. Programmatically creating a sequence
이 섹션에선 이벤트를 (onNext, onError, onComplete) 프로그래밍 방식으로 정의하고 Flux나 Mono를 만드는 방법을 소개한다. 이 메소드는 모두 이벤트를 트리거할 수 있는 API를 노출하고 있으며, 이를 싱크(sink)라고 부른다. 사실 싱크는 몇 가지 변형이 있는데, 곧 살펴볼 것이다.
4.4.1. Synchronous generate
코드에서 Flux를 만드는 가장 쉬운 방법은 generator 함수를 인자로 받는 generate 메소드를 사용하는 것이다.
이는 동기 및 일대일 방출을 위한 것인데, 즉, 싱크는 SynchronousSink이며, next() 메소드는 콜백을 호출할 때마다 최대 한 번만 호출할 수 있다는 뜻이다. 추가로 error(Throwable)나 complete()를 호출할 수 있지만, 필수는 아니다.
아마 가장 유용한 건 상태를 유지할 수 있는 메소드일 것이다. 상태를 유지하면 싱크를 사용할 때 참조해서 다음에 무엇을 방출할지 결정할 수 있다. 이때 generator 함수는 BiFunction<S, SynchronousSink<T>, S>가 되고 <S>는 상태 객체 타입이다. 초기 상태를 Supplier<S>로 제공해야 하며, generator 함수는 이제 각 단계마다 새로운 상태를 반환한다.
예를 들어, int 값을 상태로 사용할 수 있다:
Example 11. Example of state-based generate
Flux<String> flux = Flux.generate(
() -> 0, // (1)
(state, sink) -> {
sink.next("3 x " + state + " = " + 3*state); // (2)
if (state == 10) sink.complete(); // (3)
return state + 1; // (4)
});
(1) 최초 상태로 0을 제공한다.
(2) 상태를 보고 방출할 데이터를 결정한다 (상태 값은 3의 곱셈표에서 행 번호를 의미한다고 볼 수 있다).
(3) 언제 중단할지 결정할 때도 상태를 사용한다.
(4) 다음 실행에서 사용할 새 상태 값을 반환한다 (시퀀스가 종료되지 않았다면).
위 코드는 다음과 같은 순서로 3의 곱셈표를 만든다:
3 x 0 = 0
3 x 1 = 3
3 x 2 = 6
3 x 3 = 9
3 x 4 = 12
3 x 5 = 15
3 x 6 = 18
3 x 7 = 21
3 x 8 = 24
3 x 9 = 27
3 x 10 = 30
상태를 변경할 수 있는(mutable) 다른 <S> 값을 사용해도 된다. 예를 들어 위 예제는 AtomicLong 하나를 상태로 사용해서 각 단계마다 상태를 바꾸는 식으로 재작성할 수 있다:
Example 12. Mutable state variant
Flux<String> flux = Flux.generate(
AtomicLong::new, // (1)
(state, sink) -> {
long i = state.getAndIncrement(); // (2)
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state; // (3)
});
(1) 이번에는 상태를 변경할 수 있는 객체를 상태 값으로 생성한다.
(2) 여기에서 상태를 변경한다.
(3) 새 상태 값으로 동일한 인스턴스를 반환한다.
상태 객체가 반환해야 할 리소스가 있다면
generate(Supplier<S>, BiFunction, Consumer<S>)메소드를 사용해서 지난 상태 인스턴스를 정리해라.
다음 예제는 Consumer를 받는 generate 메소드를 사용한다:
Flux<String> flux = Flux.generate(
AtomicLong::new,
(state, sink) -> { // (1)
long i = state.getAndIncrement(); // (2)
sink.next("3 x " + i + " = " + 3*i);
if (i == 10) sink.complete();
return state; // (3)
}, (state) -> System.out.println("state: " + state)); // (4)
(1) 다시 한 번 상태를 변경할 수 있는 객체를 상태 값으로 생성한다.
(2) 여기서 상태를 변경한다.
(3) 동일한 인스턴스를 새 상태 값으로 반환한다.
(4) Consumer 람다가 출력한 마지막 상태 값(11)을 확인한다.
상태 값이 처리가 끝났을 때 별도 작업이 필요한 데이터베이스 커넥션이나 다른 리소스를 가지고 있다면, Consumer 람다로 커넥션을 닫거나 다른 태스크를 처리하면 된다.
4.4.2. Asynchronous and Multi-threaded: create
create를 사용하면 각 단계마다 값을 여러 개 생산하는 Flux를 만들 수 있으며, 심지어 멀티 스레드로도 가능하다.
이 메소드는 next, error, complete 메소드를 가지고 있는 FluxSink를 노출하고 있다. generate와는 다르게 별도 상태 기반 메소드는 없다. 대신 콜백에서 멀티 스레드 기반 이벤트를 트리거할 수 있다.
create는 리스너 기반 비동기 API 등 기존 API를 리액티브 세계로 연결할 수 있어 매우 유용하다.
create는 비동기 API와 함께 사용할 수 있다고 해서, 코드를 병렬화해 주거나 비동기로 만들어 주지는 않는다.create람다 내에서 블로킹하면 교착 상태나 이와 유사한 부작용을 경험할 것이다.subscribeOn을 사용하더라도,create람다에서 오랫동안 블로킹하고 있으면 (sink.next(t)를 호출하는 무한 루프 등) 파이프라인이 잠겨 버릴 수 있다: 요청을 수행해야 할 스레드에서 루프를 실행하고 있기 때문에 요청을 수행할 수 없다. 이때는subscribeOn(Scheduler, false)메소드를 사용해라:create는requestOnSeparateThread = false면Scheduler스레드를 사용하고, 기존 스레드에서request를 수행하기 때문에 데이터 흐름을 멈추지 않는다.
리스너 기반 API를 사용한다고 가정해 보자. 데이터를 청크 단위로 처리하며, MyEventListener 인터페이스에 보이는 것처럼 두 가지 이벤트가 있다: (1) 데이터 청크가 준비됐다는 이벤트, (2) 처리가 완료됐다는 이벤트 (이벤트 종료):
interface MyEventListener<T> {
void onDataChunk(List<T> chunk);
void processComplete();
}
create로 이 API를 Flux<T>로 연결할 수 있다:
Flux<String> bridge = Flux.create(sink -> {
myEventProcessor.register( // (4)
new MyEventListener<String>() { // (1)
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); // (2)
}
}
public void processComplete() {
sink.complete(); // (3)
}
});
});
(1) MyEventListener API를 연결한다.
(2) 청크에 있는 각 요소는 Flux의 요소가 된다.
(3) processComplete 이벤트를 onComplete로 전환한다.
(4) 언제 myEventProcessor를 실행하더라도 이 모든 것은 비동기로 이루어진다.
추가로 create는 비동기 API를 연결하고 backpressure를 관리할 수 있기 때문에, OverflowStrategy를 지정하면 backpressure 동작 방식을 세분화할 수 있다:
IGNORE는 다운스트림 backpressure 요청을 완전히 무시한다. 다운스트림 큐가 가득 차면IllegalStateException이 발생한다.ERROR는 다운스트림을 유지할 수 없으면IllegalStateException으로 신호를 보낸다.DROP은 다운스트림이 데이터를 받을 준비가 되지 않았다면 모든 신호를 제거한다.LATEST는 다운스트림이 업스트림의 최신 신호만 받도록 만든다.BUFFER는 (디폴트) 다운스트림을 유지할 수 없으면 모든 신호를 버퍼링한다. (무한으로 버퍼링하기 때문에OutOfMemoryError가 발생할 수도 있다).
Mono도create로 생성할 수 있다. Mono의 create 메소드는MonoSink를 받기 때문에, 값을 여러 개 생산할 수는 없다. 값을 하나 만들고 나면 모든 신호는 무시된다.
4.4.3. Asynchronous but single-threaded: push
push는 generate와 create 사이의 중간 쯤이라고 볼 수 있는데, 단일 생산자 이벤트 처리에 적합하다. create와 유사하게 비동기를 지원하며, create가 지원하는 오버플로우 전략 중 하나로 backpressure를 관리할 수 있다. 그러나 데이터를 생산하는 하나의 스레드에서만 next, complete, error를 한 번에 하나씩 실행할 수 있다.
Flux<String> bridge = Flux.push(sink -> {
myEventProcessor.register(
new SingleThreadEventListener<String>() { // (1)
public void onDataChunk(List<String> chunk) {
for(String s : chunk) {
sink.next(s); // (2)
}
}
public void processComplete() {
sink.complete(); // (3)
}
public void processError(Throwable e) {
sink.error(e); // (4)
}
});
});
(1) SingleThreadEventListener API를 연결한다.
(2) 단일 리스너 스레드에서 next를 사용해 싱크로 이벤트를 푸시한다.
(3) 리스너와 동일한 스레드에서 complete 이벤트를 발생시킨다.
(4) error 이벤트도 역시 리스너와 동일한 스레드에서 발생시킨다.
A hybrid push/pull model
create 같은 리액터 연산자 대부분은 하이브리드 push/pull 모델을 따른다. 이 말은 대부분 비동기로 처리하더라도 (push 모델을 제안하더라도), 요청과 관련해서 일부 컴포넌트가 pull을 사용한다는 뜻이다.
컨슈머는 데이터 소스로 pull을 하는데, 이는 최초 요청 전까진 아무 데이터도 생산하지 않는다는 뜻이다. 소스는 데이터가 준비되면 컨슈머로 push하지만 요청받은 범위 내로만 푸쉬한다.
주목할 점은, push()와 create() 모두 onRequest 컨슈머를 설정해서 요청량을 관리하고 펜딩된 요청이 있을 때만 싱크를 통해 데이터를 푸쉬하도록 할 수 있다.
Flux<String> bridge = Flux.create(sink -> {
myMessageProcessor.register(
new MyMessageListener<String>() {
public void onMessage(List<String> messages) {
for(String s : messages) {
sink.next(s); // (3)
}
}
});
sink.onRequest(n -> {
List<String> messages = myMessageProcessor.getHistory(n); // (1)
for(String s : message) {
sink.next(s); // (2)
}
});
});
(1) 요청을 만들 때 메세지를 폴링한다.
(2) 즉시 사용할 수 있는 메세지가 있다면 싱크로 푸쉬한다.
(3) 이후 비동기로 도착할 나머지 메세지도 전달한다.
Cleaning up after push() or create()
onDispose, onCancel, 이 두 콜백은 취소나 종료 시에 필요한 cleanup을 담당한다. onDispose는 Flux가 완료되거나, 에러가 발생하거나, 혹은 취소했을 때 cleanup 용도로 사용할 수 있다. onCancel은 취소 시 onDispose보다 먼저 필요한 조치를 수행할 수 있다.
Flux<String> bridge = Flux.create(sink -> {
sink.onRequest(n -> channel.poll(n))
.onCancel(() -> channel.cancel()) // (1)
.onDispose(() -> channel.close()) // (2)
});
(1) 취소 신호를 받으면 먼저 onCancel을 실행한다.
(2) 완료, 에러, 취소 신호를 받으면 onDispose를 실행한다.
4.4.4. Handle
handle 메소드는 약간 다르다: 인스턴스 메소드로, 공통 연산자처럼 기존 소스에 연결할 수 있다. 이 연산자는 Mono와 Flux에 모두 존재한다.
SynchronousSink를 사용하고, 한 번에 값 하나씩만 생성할 수 있다는 점을 보면 generate에 가깝다. 하지만 handle은 각 소스에 있는 아이템 중 임의의 값만 생성하거나 일부 아이템을 스킵하는 식으로 활용할 수 있다. 그렇기 때문에 map과 filter의 조합이라고도 볼 수 있다. 다음은 handle 메소드 시그니처다:
Flux<R> handle(BiConsumer<T, SynchronousSink<R>>);
예제 하나를 살펴보자. 리액티브 스트림 정의에 따르면 시퀀스에 null 값은 허용하지 않는다. map을 실행할 때 기존 메소드를 map 함수로 사용하고 싶은데, 기존 메소드가 null을 리턴할 수도 있다면 어떻게 해야 할까?
예를 들어 다음과 같은 메소드도 문제없이 정수 데이터를 생산하는 소스로 적용할 수 있다:
public String alphabet(int letterNumber) {
if (letterNumber < 1 || letterNumber > 26) {
return null;
}
int letterIndexAscii = 'A' + letterNumber - 1;
return "" + (char) letterIndexAscii;
}
handle로 널 값을 모두 제거할 수 있다:
Example 13. Using handle for a “map and eliminate nulls” scenario
Flux<String> alphabet = Flux.just(-1, 30, 13, 9, 20)
.handle((i, sink) -> {
String letter = alphabet(i); // (1)
if (letter != null) // (2)
sink.next(letter); // (3)
});
alphabet.subscribe(System.out::println);
(1) 문자를 매핑한다.
(2) ”map 함수”가 null을 리턴한다면…
(3) sink.next를 호출하지 않음으로써 필터링할 수 있다.
이는 다음을 출력한다:
M
I
T
4.5. Threading and Schedulers
리액터는 RxJava처럼 동시성에 구애받지 않는다고 말할 수 있다. 즉, 특정 동시성 모델을 강요하지 않는다. 오히려, 개발자가 통제할 수 있다. 하지만 그렇다고 해서 동시성 이슈를 해결해 주는 라이브러리를 사용할 수 없는 것은 아니다.
반드시 전용 Thread에서만 Flux나 Mono를 얻어야 한다는 법은 없다. 그보단 연산자 대부분 이전 연산자를 실행했던 Thread에서 작업을 이어 나간다. 지정하지 않았다면 맨 위에 있는 연산자 자체는 (데이터 소스) subscribe()를 호출한 Thread에서 실행한다. 다음 예제는 새 스레드에서 Mono를 실행한다:
public static void main(String[] args) throws InterruptedException {
final Mono<String> mono = Mono.just("hello "); // (1)
Thread t = new Thread(() -> mono
.map(msg -> msg + "thread ")
.subscribe(v -> // (2)
System.out.println(v + Thread.currentThread().getName()) // (3)
)
)
t.start();
t.join();
}
(1) main 스레드에서 Mono<String>을 수집한다.
(2) 그러나 구독은 Thread-0 스레드에서 한다.
(3) 결과적으로 map과 onNext 콜백 모두 Thread-0에서 실행된다.
위 코드는 다음을 출력한다:
hello thread Thread-0
리액터에서 코드 실행 모델과 실행 위치는 어떤 Scheduler를 사용했느냐에 따라 달라진다. Scheduler는 ExecutorService와 유사하게 스케줄링을 담당하지만, 자체 추상화를 통해 시간을 좀 더 컨트롤할 수 있고, 더 다양하게 구현할 수 있다 (테스트를 위한 가상 시간, trampolining, 또는 즉각적인 스케줄링 등).
아래와 같은 Schedulers 클래스의 스태틱 메소드로 실행 컨텍스트에 접근할 수 있다:
- 실행 컨텍스트가 없음 (
Schedulers.immediate()): 처리 시간에 제출한Runnable을 즉시 실행한다. 사실상 현재Thread에서 실행한다 (“널 객체” 혹은 아무 일도 하지 않는Scheduler라고 볼 수 있다). - 재사용할 수 있는 단일 스레드 (
Schedulers.single()). 이 메소드는 스케줄러를 폐기하기 전까지 여러 번 호출해도 매번 동일한 스레드를 재사용한다는 점에 주의해라. 호출할 때마다 전용 스레드를 사용하고 싶다면 매번Schedulers.newSingle()을 호출하라. - Unbounded elastic 스레드 풀 (
Schedulers.elastic()). 이 메소드는 backpressure 이슈를 감추고 너무 많은 스레드를 사용하는 경향이 있어서 (아래 참고),Schedulers.boundedElastic()가 나온 이후론 잘 사용하지 않는다. - Bounded elastic 스레드 풀 (
Schedulers.boundedElastic()). 이전의elastic()처럼 필요하면 새 워커 풀을 만들고, 여유 있는 스레드가 있으면 재사용한다. 또한 너무 오랫동안 (디폴트는 60초) 놀고 있는 워커 풀이 있다면 폐기한다. 풀에 생성할 수 있는 스레드 수를 제한한다는 점은 (디폴트는 CPU 코어수 x 10) 이전의elastic()과 다르다. 한도에 도달한 이후 제출한 태스크는 100,000개까지 큐에 담고, 스레드에 여유가 생기면 다시 스케줄링한다 (지연 스케줄링을 사용하면, 스레드가 이용 가능해진 이후부터 지연 시간을 계산한다). 블로킹 I/O가 필요하다면 더 나은 선택일 것이다.Schedulers.boundedElastic()을 사용하면 손쉽게 블로킹 프로세스에 별도 스레드를 할당해서 다른 리소스를 묶어두지 않을 수 있다. How Do I Wrap a Synchronous, Blocking Call?을 참고하되, 너무 많은 스레드를 사용해 시스템에 무리를 주지 않도록 주의하라. - 병렬 작업을 튜닝할 수 있는 워커의 고정 풀 (
Schedulers.parallel()). CPU 코어 수 만큼 워커를 생성한다.
추가적으로, Schedulers.fromExecutorService(ExecutorService)를 사용하면 기존의 모든 ExecutorService로 Scheduler를 생성할 수 있다. (Executor로도 생성할 수 있지만, 권장하지는 않는다.)
newXXX 메소드를 사용하면 다양한 스케줄러 인스턴스를 만들 수 있다. 예를 들어 Schedulers.newParallel(yourScheduleName)는 yourScheduleName이라는 이름의 새 병렬 스케줄러를 생성한다.
레거시 블로킹 코드가 반드시 필요하다면
boundedElastic이 도움이 될 수 있지만,single과parallel은 그렇지 않다. 결과적으로 리액터 블로킹 API를 사용하게 되고 (디폴트 single, parallel 스케줄러 안에 있는block(),blockFirst(),blockLast().toIterable(),toStream()으로 순회하는 경우도 마찬가지다), 이는IllegalStateException을 던진다.커스텀
Schedulers에서도NonBlocking마커 인터페이스를 구현한Thread를 생성하면 “논블로킹 only”로 마킹할 수 있다.
일부 연산자는 Schedulers 중 하나를 디폴트로 사용한다 (그리고 일반적으로 다른 스케줄러를 사용할 수 있는 옵션을 제공한다). 예를 들어, Flux.interval(Duration.ofMillis(300)) 팩토리 메소드를 호출하면 300ms 마다 데이터를 생산하는 Flux<Long>을 만든다. 이는 디폴트로 Schedulers.parallel()에 의해 활성화된다. 다음 코드는 스케줄러를 Schedulers.single()과 유사한 새 인스턴스로 변경한다:
Flux.interval(Duration.ofMillis(300), Schedulers.newSingle("test"))
리액터는 리액티브 체인에서 실행 컨텍스트 (또는 Scheduler)를 전환할 수 있는 publishOn과 subscribeOn을 제공한다. 둘 다 Scheduler를 받아 실행 컨텍스트를 해당 스케줄러로 전환할 수 있다. 단, publishOn은 체인 어디에 위치하느냐가 중요하지만, subscribeOn 위치는 중요하지 않다. 이 차이점을 이해하려면 먼저 구독 할 때까진 아무 일도 일어나지 않는다는 것을 떠올릴 수 있어야 한다.
리액터에서 연산자를 연결할 땐, 필요에 따라 Flux와 Mono 구현체를 다른 구현체로 감쌀 수도 있다. 구독하고 나면 첫 번째 생산자(publisher) 뒤로 (체인 위쪽) Subscriber 객체 체인이 만들어진다. 사실 이를 직접 확인하긴 어렵다. 직접 볼 수 있는 것은 바깥쪽에 있는 Flux (혹은 Mono)와 Subscription 정도지만, 이 중간 계층 연산자의 구독자에서 실제 작업이 일어난다.
이를 이해했다면, 이제 publishOn과 subscribeOn 연산자를 더 자세히 살펴보자:
4.5.1. The publishOn Method
publishOn은 다른 연산자와 마찬가지로 구독자 체인 중간에 적용된다. 해당 Scheduler의 워커에서 콜백을 실행하는 동안 업스트림에서 신호를 받아 다운스트림으로 재생산한다. 결과적으로, 다음과 같이 이어지는 연산자를 실행하는 위치가 달라질 수 있다 (체인에서 다른 publishOn을 만날 때까지):
- 실행 컨텍스트를
Scheduler가 고른Thread로 변경한다 - 리액티브 스트림 정의에 따라
onNext는 순차적으로 호출하기 때문에 단일 스레드를 사용한다 - 특정
Schuduler로 실행하지 않았다면publishOn이후의 연산자는 동일한 스레드에서 이어서 실행한다
다음은 publishOn 메소드를 사용하는 예제다:
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4); // (1)
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) // (2)
.publishOn(s) // (3)
.map(i -> "value " + i); // (4)
new Thread(() -> flux.subscribe(System.out::println)); // (5)
(1) Thread 인스턴스 4개를 지원하는 Scheduler를 생성한다.
(2) 첫 번째 map은 (5)에서 생성한 익명 스레드에서 실행한다.
(3) publishOn은 (1)에서 생성한 스레드 중 하나로 전체 시퀀스를 전환한다.
(4) 두 번째 map은 (1)에서 생성한 스레드 중 하나에서 실행한다.
(5) 이 익명 Thread에서 구독이 일어난다. 출력은 마지막 컨텍스트, publishOn 중 하나에서 일어난다.
4.5.2. The subscribeOn Method
subscribeOn이 구독 프로세스에 적용되는 시점은 역방향 체인이 구성될 때다. 결과적으로 subscribeOn을 체인 어디에 두든지 관계없이, 항상 데이터 소스를 방출하는 컨텍스트에 영향을 미친다. 하지만 publishOn을 호출하면 이후 동작에는 영향을 주지 않는다 — 이후 체인에서 실행 컨텍스트를 한 번 더 전환한다.
- 연산자의 전체 체인이 구독하는
Thread를 변경한다 Scheduler에서 스레드를 하나 고른다
실제로는 체인의 가장 앞에 있는
subscribeOn호출만 고려한다.
다음은 subscribeOn 메소드를 사용하는 예제다:
Scheduler s = Schedulers.newParallel("parallel-scheduler", 4); // (1)
final Flux<String> flux = Flux
.range(1, 2)
.map(i -> 10 + i) // (2)
.subscribeOn(s) // (3)
.map(i -> "value " + i); // (4)
new Thread(() -> flux.subscribe(System.out::println)); // (5)
(1) Thread 인스턴스 4개를 지원하는 Scheduler를 생성한다.
(2) 첫 번째 map은 이 스레드 4개 중 하나에서 실행한다…
(3) …subscribeOn이 (5)에서 구독하는 즉시 전체 시퀀스를 전환하기 때문이다.
(4) 두 번째 map도 동일한 스레드에서 실행한다.
(5) 이 익명 Thread에서 최초 구독이 일어나지만, subscribeOn이 스케줄러 스레드 4개 중 하나로 즉시 변경한다.
4.6. Handling Errors
에러를 처리할 수 있는 연산자를 빠르게 훑어보고 싶다면 상황별 연산자 결정 트리를 참고하라.
리액티브 스트림에서 에러는 종료 이벤트다. 에러가 발생하는 즉시 시퀀스를 종료하고, 연산자 체인 아래 있는 마지막 스텝, 즉 정의한 Subscriber의 onError 메소드에 에러를 전파한다.
이런 에러도 어플리케이션 단에서 처리해야 한다. 예를 들어 UI에서 에러 알림을 보여주거나, REST 엔드포인트로 의미 있는 에러 메세지를 전달할 수 있다. 따라서 항상 구독자의 onError 메소드를 정의해야 한다.
정의하지 않으면
onError는UnsupportedOperationException을 던진다. 이런 예외는Exceptions.isErrorCallbackNotImplemented메소드로 알아내 분류할 수 있다.
또한 리액터는 에러 처리 연산자를 제공하기 때문에, 체인 중간에 다른 방식으로도 에러를 처리할 수 있다. 다음 예제는 그 방법을 보여준다:
Flux.just(1, 2, 0)
.map(i -> "100 / " + i + " = " + (100 / i)) //this triggers an error with 0
.onErrorReturn("Divided by zero :("); // error handling example
오류 처리 연산자를 익히기 전에 먼저, 리액티브 시퀀스에서 발생하는 모든 에러는 종료 이벤트라는 점을 명심해야 한다. 에러 처리 연산자를 사용하더라도, 기존 시퀀스를 유지할 수는 없다.
onError신호는 오히려 새로운 시퀀스(fallback)를 시작한다. 즉, 종료된 시퀀스의 업스트림을 대체한다.
이제 에러를 처리하는 방법을 하나씩 살펴보자. 필요하다면 명령형 프로그래밍의 try 패턴과 비교해볼 것이다.
4.6.1. Error Handling Operators
아마도 try-catch 블록으로 에러를 처리하는 것엔 익숙할 것이다. 가장 많이 사용하는 패턴은 다음과 같다:
- 캐치한 다음 디폴트 스태틱 값을 리턴한다.
- 캐치한 다음 fallback 메소드를 실행한다.
- 캐치한 다음 동적으로 fallback 값을 계산한다.
- 캐치해서
BusinessException으로 감싸 다시 던진다. - 캐치해서 에러 메세지를 로깅하고 다시 던진다.
finally블록으로 리소스를 정리하거나 자바 7의 “try-with-resource” 구조를 사용한다.
리액터의 에러 처리 연산자로도 모든 패턴을 구현할 수 있다. 해당 연산자를 살펴보기 전에 앞서 리액티브 체인과 try-catch 블록을 비교해 보려 한다.
구독할 때 체인 끝에 사용하는 onError 콜백은 catch 블록과 유사하다. 다음 예제처럼, Exception이 발생하면 catch로 실행을 건너뛴다.
Flux<String> s = Flux.range(1, 10)
.map(v -> doSomethingDangerous(v)) // (1)
.map(v -> doSecondTransform(v)); // (2)
s.subscribe(value -> System.out.println("RECEIVED " + value), // (3)
error -> System.err.println("CAUGHT " + error) // (4)
);
(1) 예외를 발생시킬 수 있는 변환을 수행한다.
(2) 문제없이 실행했다면 두 번째 변환을 수행한다.
(3) 변환한 값들을 각각 출력한다.
(4) 에러가 발생했다면 시퀀스를 종료하고 에러 메세지를 표시한다.
앞의 예제는 개념적으로 아래 try-catch 블록과 유사하다:
try {
for (int i = 1; i < 11; i++) {
String v1 = doSomethingDangerous(i); // (1)
String v2 = doSecondTransform(v1); // (2)
System.out.println("RECEIVED " + v2);
}
} catch (Throwable t) {
System.err.println("CAUGHT " + t); // (3)
}
(1) 여기서 예외가 발생한다면…
(2) …반복문의 나머지 코드는 건너뛰고…
(3) …바로 이곳으로 넘어간다.
이제 비교는 해 봤고, 다른 에러 처리 방식과 그에 상응하는 연산자를 더 살펴보도록 하자.
Static Fallback Value
“캐치한 다음 디폴트 스태틱 값을 리턴한다”는 onErrorReturn과 동일하다:
try {
return doSomethingDangerous(10);
}
catch (Throwable error) {
return "RECOVERED";
}
다음은 리액터로 만든 동일한 예제다:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn("RECOVERED");
다음 예제처럼 예외에 Predicate를 적용해서 복구 여부를 결정할 수도 있다:
Flux.just(10)
.map(this::doSomethingDangerous)
.onErrorReturn(e -> e.getMessage().equals("boom10"), "recovered10"); // (1)
(1) 예외 메세지가 boom10일 때만 복구한다
Fallback Method
원하는 디폴트 값이 여러 개고, 데이터를 처리할 다른 방법이 (좀 더 안전한) 있다면 onErrorResume을 사용할 수 있다. 이는 “캐치한 다음 fallback 메소드를 실행한다”와 동일하다.
예를 들어, 신뢰할 수 없는 외부 서비스에서 데이터를 가져오는 명목상의 프로세스가 있어서, 최신성은 좀 떨어지지만 신뢰할 수 있는 동일 데이터를 로컬 캐시에 저장해야 한다면, 다음과 같이 작성하면 된다:
String v1;
try {
v1 = callExternalService("key1");
}
catch (Throwable error) {
v1 = getFromCache("key1");
}
String v2;
try {
v2 = callExternalService("key2");
}
catch (Throwable error) {
v2 = getFromCache("key2");
}
다음은 리액터로 만든 동일한 예제다:
Flux.just("key1", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(e -> getFromCache(k))
);
(1) 키마다 각각 비동기로 외부 서비스를 호출한다.
(2) 외부 서비스 호출에 실패하면, 동일한 키를 캐시에서 조회하는 것으로 대응한다. 에러를 발생시킨 e가 무엇인지는 관계없이 항상 동일한 fallback을 사용한다는 점에 유의하라.
onErrorResume도 onErrorReturn처럼 예외 클래스나 Predicate 기준으로 fallback할 예외를 필터링할 수 있는 메소드가 있다. Function도 인자로 받기 때문에 발생한 에러에 따라 전환할 fallback 시퀀스를 다르게 가져갈 수도 있다. 다음은 이 방법을 사용한 예제다:
Flux.just("timeout1", "unknown", "key2")
.flatMap(k -> callExternalService(k)
.onErrorResume(error -> { // (1)
if (error instanceof TimeoutException) // (2)
return getFromCache(k);
else if (error instanceof UnknownKeyException) // (3)
return registerNewEntry(k, "DEFAULT");
else
return Flux.error(error); // (4)
})
);
(1) funtion을 통해 로직을 동적으로 결정한다.
(2) 데이터 소스에서 타임아웃이 발생하면 로컬 캐시를 뒤진다.
(3) 데이터 소스에서 알 수 없는 키라고 판단하면 새 엔트리를 생성한다.
(4) 그 외에는 “다시 던진다”.
Dynamic Fallback Value
데이터를 처리할 다른 (더 안전한) 방법이 없는 경우에도 전달받은 예외로 fallback 값을 계산할 수 있다. 이는 “캐치한 다음 동적으로 fallback 값을 계산한다”와 동일하다.
예를 들어, 리턴 타입 (MyWrapper) 전용 예외 처리를 위한 메소드가 있다면 (Future.complete(T success)와 Future.completeExceptionally(Throwable error)를 생각해 보라), 그 메소드를 초기화해 예외를 전달할 수 있다.
명령형 프로그래밍은 다음과 같이 작성할 것이다:
try {
Value v = erroringMethod();
return MyWrapper.fromValue(v);
}
catch (Throwable error) {
return MyWrapper.fromError(error);
}
리액티브에서도 onErrorResume과 약간의 보일러플레이트만 있으면 다음과 같이 동일한 fallback 솔루션을 적용할 수 있다:
erroringFlux.onErrorResume(error -> Mono.just( // (1)
MyWrapper.fromError(error) // (2)
));
(1) 에러는 MyWrapper으로 표현하기 때문에 onErrorResume에선 Mono<MyWrapper>가 필요하다. 이를 위해 단순히 Mono.just()를 사용한다.
(2) 예외를 사용해서 값을 계산해야 하는데, 여기서 MyWrapper 팩토리 메소드로 예외를 감싸 값을 만든다.
Catch and Rethrow
“캐치해서 BusinessException으로 감싸 다시 던진다”는, 명령형 프로그래밍 세상에선 다음과 같이 작성한다:
try {
return callExternalService(k);
}
catch (Throwable error) {
throw new BusinessException("oops, SLA exceeded", error);
}
“fallback 메소드” 예제의 flatMap 가장 안쪽에 있는 코드를 보면 리액티브 방식으로 같은 코드를 구현하기 위한 힌트를 얻을 수 있다:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorResume(original -> Flux.error(
new BusinessException("oops, SLA exceeded", original))
);
onErrorMap을 사용하면 좀 더 직관적으로 동일한 효과를 만들 수 있다:
Flux.just("timeout1")
.flatMap(k -> callExternalService(k))
.onErrorMap(original -> new BusinessException("oops, SLA exceeded", original));
Log or React on the Side
에러를 계속 전파하면서 시퀀스를 수정하지 않는 다른 일을 하고 싶다면 (로깅 등), doOnError 연산자를 사용하라. 다음 예제에서 볼 수 있듯, 이는 “캐치해서 에러 메세지를 로깅하고 다시 던진다”와 동일한 패턴이다:
try {
return callExternalService(k);
}
catch (RuntimeException error) {
//make a record of the error
log("uh oh, falling back, service failed for key " + k);
throw error;
}
doOnError 연산자는 doOn으로 시작하는 다른 연산자들과 마찬가지로, “부수 효과”를 껴 넣을 수 있다. 이를 활용하면 시퀀스를 수정하지는 않으면서, 시퀀스 이벤트 안에서 원하는 부수 효과를 일으킬 수 있다.
위에서 본 명령형 코드처럼, 다음 예제도 에러를 계속 전파시키지만 최소한 외부 서비스 호출에 실패했다는 로그를 남길 수 있다:
LongAdder failureStat = new LongAdder();
Flux<String> flux =
Flux.just("unknown")
.flatMap(k -> callExternalService(k) // (1)
.doOnError(e -> {
failureStat.increment();
log("uh oh, falling back, service failed for key " + k); // (2)
})
// (3)
);
(1) 외부 서비스 호출에 실패한다면…
(2) …로그를 남기고 통계 값에 부수 효과를 일으킨다…
(3) …여기에 에러를 복구하는 연산자를 사용하지 않는다면, 이후엔 에러와 함께 시퀀스를 종료한다.
두 번째 부수 효과로 통계 카운터 값을 증가시키는 것도 상상해볼 수 있다.
Using Resources and the Finally Block
마지막으로 “finally 블록”이나 “자바 7의 try-with-resource 구조” 패턴을 사용해 리소스를 정리하는 명령형 프로그래밍과 비교해볼 것이다. 둘 다 아래 예제에 있다:
Example 14. Imperative use of finally
Stats stats = new Stats();
stats.startTimer();
try {
doSomethingDangerous();
}
finally {
stats.stopTimerAndRecordTiming();
}
Example 15. Imperative use of try-with-resource
try (SomeAutoCloseable disposableInstance = new SomeAutoCloseable()) {
return disposableInstance.toString();
}
두 방식 모두 리액터로도 가능하다: doFinally, using.
doFinally로는 시퀀스를 종료하거나 (onComplete 또는 onError) 취소될 때마다 원하는 부수 효과를 실행시킬 수 있다. 종료 타입에 대한 힌트도 얻을 수 있다. 다음은 doFinally를 사용하는 예제다:
Reactive finally: doFinally()
Stats stats = new Stats();
LongAdder statsCancel = new LongAdder();
Flux<String> flux =
Flux.just("foo", "bar")
.doOnSubscribe(s -> stats.startTimer())
.doFinally(type -> { // (1)
stats.stopTimerAndRecordTiming(); // (2)
if (type == SignalType.CANCEL) // (3)
statsCancel.increment();
})
.take(1); // (4)
(1) doFinally에선 종료 타입을 나타내는 SignalType을 consume한다.
(2) finally 블록과 유사하게 시간을 기록한다.
(3) 여기선 취소가 발생했을 때만 통계 값을 증가시킨다.
(4) take(1)으로 아이템 하나를 방출한 뒤 취소한다.
반면 using은 Flux 처리가 완료되면 Flux를 생산한 리소스로 어떤 처리를 해야 할 때 사용한다. 다음 예에서는 “try-with-resource”에서 사용한 AutoCloseable 인터페이스 대신 Disposable을 사용한다.
Example 16. The Disposable resource
AtomicBoolean isDisposed = new AtomicBoolean();
Disposable disposableInstance = new Disposable() {
@Override
public void dispose() {
isDisposed.set(true); // (4)
}
@Override
public String toString() {
return "DISPOSABLE";
}
};
이제 “try-with-resource”를 리액티브로 바꿔보자:
Example 17. Reactive try-with-resource: using()
Flux<String> flux =
Flux.using(
() -> disposableInstance, // (1)
disposable -> Flux.just(disposable.toString()), // (2)
Disposable::dispose // (3)
);
(1) 첫 번째 람다에서 리소스를 생성한다. 여기선 Disposable 목 객체를 리턴한다.
(2) 두 번째 람다는 리소스를 처리해서 Flux<t>를 리턴한다.
(3) 세 번째 람다는 리소스를 정리하며, (2)의 Flux가 종료되거나 취소됐을 때 호출한다.
(4) 구독 후 시퀀스를 실행하면 isDisposed의 AtomicBoolean 값은 true가 된다.
Demonstrating the Terminal Aspect of onError
Flux.interval을 사용하면, 이 연산자들은 전부 에러가 발생하면 기존 업스트림 시퀀스를 종료한다는 것을 확인해 볼 수 있다. interval 연산자는 x 만큼의 시간이 지날 때마다 Long 값을 증가시킨다. 다음은 interval 연산자를 사용하는 예제다:
Flux<String> flux =
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.onErrorReturn("Uh oh");
flux.subscribe(System.out::println);
Thread.sleep(2100); // (1)
(1) interval은 기본적으로 timer Scheduler에서 실행한다는 점에 주의하라. 이 예제를 main 클래스에서 실행한다면, 어플리케이션이 값을 생산하지 않은 체로 즉시 종료되지 않도록 여기서 sleep을 호출해야 한다.
위 예제는 250ms마다 아래 값들을 출력한다:
tick 0
tick 1
tick 2
Uh oh
1초를 더 실행한다고 해도 interval은 더 이상 값을 만들지 않는다. 에러로 인해 시퀀스는 종료된다.
Retrying
에러 처리와 관련해서 또 다른 연산자가 있는데, 위에서 다룬 케이스에서도 사용할 수 있다. retry는 이름에서도 알 수 있듯이 에러를 생산한 시퀀스를 재시도해볼 수 있는 연산자다.
단, 이는 업스트림 Flux를 재구독한다는 점을 명심하라. 이는 완전히 다른 시퀀스이며, 기존 시퀀스는 종료시킨다. 이를 확인해 보기 위해 앞의 예제를 다시 가져와 onErrorReturn을 사용하는 대신 retry(1)으로 한 번 재시도해보겠다. 다음 예제를 보라:
Flux.interval(Duration.ofMillis(250))
.map(input -> {
if (input < 3) return "tick " + input;
throw new RuntimeException("boom");
})
.retry(1)
.elapsed() // (1)
.subscribe(System.out::println, System.err::println); // (2)
Thread.sleep(2100); // (3)
(1) elapsed로 데이터와 이전 데이터를 방출한 이후 소요된 시간을 한군데 묶는다.
(2) onError 신호도 확인할 수 있다.
(3) 4개씩 두 번 값을 생산할 수 있을 만큼 시간을 준다.
위 코드는 다음을 출력한다:
259,tick 0
249,tick 1
251,tick 2
506,tick 0 // (1)
248,tick 1
253,tick 2
java.lang.RuntimeException: boom
(1) interval은 0부터 다시 시작한다. 네 번째 출력은 예외가 발생하고 재시도했기 때문에 250ms가 추가로 더 소요됐다.
위 예제에서 보이듯 retry(1)은 단순히 기존 interval을 한 번 더 구독하기 때문에 0부터 다시 시작한다. 두 번째 시도에서도 동일한 예외가 발생하기 때문에 결국은 다운스트림으로 에러를 전파한다.
retry는 “companion” Flux를 사용해서 실패 시 재시도 여부를 지정할 수 있는 다른 버전도 있다 (retryWhen). companion Flux는 이 연산자에서 생성하지만, 사용자가 재시도할 조건을 커스텀할 수 있다.
이 Companion Flux는 Flux<RetrySignal>로, retryWhen의 유일한 파라미터 Retry 전략/함수를 건네받는다. 이 함수를 정의해 새로운 Publisher<?>를 리턴하라. Retry는 추상 클래스지만, 간단한 람다로 companion을 변형해 주는 팩토리 메소드를 제공한다 (Retry.from(Function)).
재시도 사이클은 다음처럼 진행된다:
- 에러가 발생할 때마다 (재시도 가능성이 있는), 사용자 함수로 장식한 companion
Flux로RetrySignal이 전달된다. 이때Flux로 지금까지의 모든 재시도 내역을 한눈에 볼 수 있다. 이RetrySignal로 발생한 에러와 메타 데이터에 접근할 수 있다. - companion
Flux에서 값을 방출하면 재시도한다. - companion
Flux가 완료되면, 에러는 삼켜지고 재시도 사이클은 중단되며, 그 결과 시퀀스도 완료된다. - companion
Flux가 에러를 생산하면 (e), 재시도 사이클은 중단하고 결과 시퀀스는e에러로 끝난다.
앞서 나온 케이스와는 다르다는 점을 이해해야 한다. 단순히 companion을 완료시키면 사실상 에러는 삼켜진다. 다음처럼 retryWhen을 사용해 retry(3)과 동일하게 구성하는 경우를 생각해 보자:
Flux<String> flux = Flux
.<String>error(new IllegalArgumentException()) // (1)
.doOnError(System.out::println) // (2)
.retryWhen(Retry.from(companion -> // (3)
companion.take(3))); // (4)
(1) 계속해서 에러를 생산해 재시도를 유도한다.
(2) 재시도 전 doOnError에서 모든 에러를 로깅한다.
(3) Retry는 매우 간단한 Function 람다를 받는다.
(4) 에러 세 번째까지는 재시도하고 (take(3)) 이후는 그만두게 설정한다.
사실 위 예제는 비어있는 Flux를 만들지만, 성공적으로 완료된다. 동일한 Flux에 retry(3)을 호출하면 마지막 에러에서 종료되기 때문에, retryWhen 예제는 정확하게 말하면 retry(3)과 동일하진 않다.
똑같이 동작하게 만들려면 몇 가지 트릭이 필요하다:
AtomicInteger errorCount = new AtomicInteger();
Flux<String> flux =
Flux.<String>error(new IllegalArgumentException())
.doOnError(e -> errorCount.incrementAndGet())
.retryWhen(Retry.from(companion -> // (1)
companion.map(rs -> { // (2)
if (rs.totalRetries() < 3) return rs.totalRetries(); // (3)
else throw Exceptions.propagate(rs.failure()); // (4)
})
));
(1) 클래스를 제공하는 대신 Function 람다를 사용해서 Retry를 커스텀한다.
(2) companion은 지금까지의 재시도 횟수와 마지막 실패 정보를 가지고 있는 RetrySignal을 발생시킨다.
(3) 세 번 재시도할 수 있도록 인덱스 값이 3보다 작으면 값을 리턴해 방출시킨다 (여기선 단순히 인덱스를 리턴한다).
(4) 시퀀스를 에러로 끝내기 위해 세 번 재시도한 다음에는 기존 예외를 던진다.
Retry에서 제공하는 빌더를 사용하면 좀 더 유연한 방식으로 동일한 작업을 수행할 수 있으며, 재시도 전략도 더 정교하게 조정할 수 있다. 예를 들어errorFlux.retryWhen(Retry.max(3));.
FAQ에 있는 것처럼, 유사한 코드로 “exponential backoff and retry” 패턴을 구현할 수도 있다.
코어에서 제공하는 두 Retry 헬퍼, RetrySpec과 RetryBackoffSpec으로 다음과 같은 고급 커스텀도 가능하다:
- 재시도를 트리거할 수 있는 예외에
filter(Predicate)을 설정한다 - 이렇게 설정된 기존 필터를
modifyErrorFilter(Function)으로 수정한다 - 재시도가 유효하다면, 재시도를 트리거할 때 로깅 같은 부수 효과를 함께 트리거한다 (지연 전후의 backoff 등) (
doBeforeRetry()와doAfterRetry()) - 재시도를 트리거할 때 비동기
Mono<Void>를 트리거해서 기존 지연에 비동기 동작을 더해 트리거를 더 지연시킨다 (doBeforeRetryAsync와doAfterRetryAsync) onRetryExhaustedThrow(BiFunction)으로 재시도 최대 횟수에 도달했을 때 발생시킬 예외를 커스텀한다. 디폴트로Exceptions.retryExhausted(…)를 사용하며,Exceptions.isRetryExhausted(Throwable)로 구별할 수 있다.- 일시적인 에러 처리를 활성화한다 (아래 참고)
Retry 스펙에서 일시적인 에러를 처리할 땐 RetrySignal#totalRetriesInARow()를 사용해서, 재시도 여부를 확인하고 재시도 지연 시간을 계산하기 위해 onNext가 발생할 때마다 인덱스를 0으로 재설정한다. 다시 구독한 데이터 소스가 실패 없이 데이터를 생성하면, 그 전에 실패한 경우는 최대 재시도 횟수에 포함시키지 않는다. exponential backoff 전략에서 이는, 다음 시도에선 더 오래 기다리는 대신 최소 Duration backoff 값을 사용한다는 뜻이다. 이 방식은 오래 사용하는 리소스가 산발적으로 에러를 내뿜어서 (또는 일시적인 오류) 각각 다른 방식으로 backoff을 시도해야 하는 경우에 특히 유용하다.
AtomicInteger errorCount = new AtomicInteger(); // (1)
AtomicInteger transientHelper = new AtomicInteger();
Flux<Integer> transientFlux = Flux.<Integer>generate(sink -> {
int i = transientHelper.getAndIncrement();
if (i == 10) { // (2)
sink.next(i);
sink.complete();
}
else if (i % 3 == 0) { // (3)
sink.next(i);
}
else {
sink.error(new IllegalStateException("Transient error at " + i)); // (4)
}
})
.doOnError(e -> errorCount.incrementAndGet());
transientFlux.retryWhen(Retry.max(2).transientErrors(true)) // (5)
.blockLast();
assertThat(errorCount).hasValue(6); // (6)
(1) 재시도한 순서대로 에러 횟수를 카운팅한다.
(2) generate에서 에러를 다량 발생시키는 데이터 소스를 생성한다. 카운터가 10이 되면 성공적으로 완료시킨다.
(3) transientHelper의 atomic 값이 3의 배수면 onNext를 발생시키겨서 한 텀을 종료한다.
(4) 그 외엔 onError를 발생시킨다. 세 번 중에 두 번이기 때문에, onError 두 번 다음 onNext 한 번이다.
(5) 이 데이터 소스에는 retryWhen을 사용해서 최대 2번 재시도 하되, transientErrors 모드로 설정한다.
(6) errorCount에 에러 6이 등록되고 나서, 시퀀스는 마지막으로 onNext(10)를 만나 종료된다.
transientErrors(true)를 사용하지 않으면 2로 설정한 최대 재시도 횟수는 두 번째 에러에서 채워지고, 시퀀스는 onNext(3)을 마지막으로 실패한다.
4.6.2. Handling Exceptions in Operators or Functions
일반적으로 모든 연산자는 자체에 예외를 발생시킬 수 있는 코드가 있거나 유사하게 실패할 수 있는 사용자 정의 콜백을 호출할 수 있기 때문에, 모두 저마다의 에러 처리 양식을 가지고 있다.
일반적으로 unchecked exception은 항상 onError를 통해 전파된다. 예를 들어, 다음 코드처럼 map 함수 안에서 RuntimeException을 던지면 onError 이벤트로 해석된다:
Flux.just("foo")
.map(s -> { throw new IllegalArgumentException(s); })
.subscribe(v -> System.out.println("GOT VALUE"),
e -> System.out.println("ERROR: " + e));
위 코드는 다음을 출력한다:
ERROR: java.lang.IllegalArgumentException: foo
hook을 사용하면
Exception을onError로 전달하기 전에 튜닝할 수 있다.
하지만 리액터에서는 항상 치명적인 에러로 간주해야 하는 예외를 따로 정의하고 있다 (OutOfMemoryError 같은). Exceptions.throwIfFatal 메소드를 참고하라. 이 에러는 리액터에서 더 이상 연산을 이어갈 수 없으며 전파되기보단 예외를 던진다는 뜻이다.
내부적으로 unchecked exception도 전파할 수 없는 경우가 있을 수 있는데 (주로 구독과 요청 단계에서), 동시성 경합으로
onError나onComplete조건을 두 번 이끄는 경우가 그렇다. 동시성 경합이 발생하면 전파할 수 없는 에러는 “버려진다”. 이런 경우도 커스텀한 훅을 사용하면 어느 정도는 관리할 수 있다. Dropping Hooks를 참고하라.
아마 checked exception에 대해서도 알고 싶을 것이다.
예를 들어 throws exception을 선언한 메소드를 호출해야 한다면 여전히 try-catch 블록으로 예외를 처리해야 한다. 그렇지만 몇 가지 옵션이 있다:
- 예외를 캐치해서 복구한다. 시퀀스는 정상적으로 이어간다.
- 예외를 캐치해서 unchecked exception으로 감싸 다시 던진다 (시퀀스를 중단한다).
Exceptions유틸리티 클래스가 도움이 될 것이다 (바로 뒤에서 설명한다). Flux를 리턴해야 한다면 (예를 들어flatMap안이라면), 에러를 생산하는Flux로 예외를 감싸라 (return Flux.error(checkedException)). (역시 시퀀스는 종료된다.)
리액터는 checked exception일 때만 예외를 감쌀 수 있는 Exceptions 유틸리티 클래스를 제공한다:
- 필요하다면
Exceptions.propagate메소드로 예외를 감싸라. 이 메소드는 먼저throwIfFatal을 호출해 보고RuntimeException이라면 감싸지 않는다. - 감싸기 전에 있던 기존 예외가 필요하면
Exceptions.unwrap메소드를 사용해라 (리액터 관련 예외 계층 구조에서 루트 원인으로 거슬러 올라간다).
IOException을 발생시킬 수 있는 변환 메소드를 map에 사용하는 예제를 생각해 보자:
public String convert(int i) throws IOException {
if (i > 3) {
throw new IOException("boom " + i);
}
return "OK " + i;
}
이제 이 메소드를 map에서 사용한다고 가정하자. 이번엔 명시적으로 예외를 캐치해야 하며, map 함수는 이 예외를 다시 던질 수 없다. 따라서 다음과 같이 map의 onError 메소드로 RuntimeException을 전파시킨다:
Flux<String> converted = Flux
.range(1, 10)
.map(i -> {
try { return convert(i); }
catch (IOException e) { throw Exceptions.propagate(e); }
});
나중에 이 Flux를 구독하고서 에러를 처리할 때 (UI 등에서), IOException을 가지고 특별한 작업을 수행해야 한다면 원래의 예외로 되돌릴 수 있다. 그 방법은 다음 예제에 있다:
converted.subscribe(
v -> System.out.println("RECEIVED: " + v),
e -> {
if (Exceptions.unwrap(e) instanceof IOException) {
System.out.println("Something bad happened with I/O");
} else {
System.out.println("Something bad happened");
}
}
);
4.7. Processors
프로세서는 Publisher이면서 동시에 Subscriber이기도 한 특별한 Publisher다. 이 말은 Processor를 subscribe할 수도 있고 (일반적으로 Flux를 구현하고 있다), 시퀀스에 수동으로 데이터를 주입하는 메소드나 시퀀스를 종료시키는 메소드를 호출할 수도 있다는 뜻이다.
프로세서는 몇 가지 종류가 있어서 시맨틱스가 조금씩 다르다. 프로세서를 살펴보기에 앞서 먼저 스스로에게 다음 질문을 해 볼 필요가 있다:
4.7.1. Do I Need a Processor?
웬만하면 Processor를 사용하지 않는 게 좋다. 올바르게 사용하기도 어렵고 코너 케이스가 발생하기 쉽다.
지금 해결해야 할 문제에 Processor가 적합하다고 생각된다면, 다음 두 가지 대안은 시도해 보았는지 먼저 검토해 봐라:
- 연산자나 연산자 조합으로 구현할 수 있는가? (Which operator do I need? 참고.)
- 대신 “generator” 연산자를 사용할 순 없는가? (일반적으로 이 연산자들은 리액티브하지 않은 API를 연결하기 위한 것이므로
Processor개념과 유사한 “sink”를 제공한다. 따라서 시퀀스에 데이터를 수동으로 넣거나 종료시킬 수 있다).
위 대안을 검토해 보았는데도 Processor가 필요하다고 생각된다면 Overview of Available Processors 섹션을 참고해 다양한 구현체에 대해 알아봐라.
4.7.2. Safely Produce from Multiple Threads by Using the Sink Facade
리액터 Processor를 직접 사용하는 것보다 sink()를 한 번 호출해서 Processor의 Sink를 획득하는 게 더 좋은 방법이다.
FluxProcessor 싱크는 멀티 스레드를 사용하는 producer를 안전하게 제어해 주며, 멀티 스레드로 동시에 데이터를 생성하는 어플리케이션에서도 사용할 수 있다. 예를 들어 다음처럼 UnicastProcessor로 thread-safe한 직렬화된 싱크를 만들 수 있다:
UnicastProcessor<Integer> processor = UnicastProcessor.create();
FluxSink<Integer> sink = processor.sink(overflowStrategy);
여러 producer 스레드는 다음 코드로 동시에 직렬화된 싱크에서 데이터를 생성할 수 있다:
sink.next(n);
FluxSink가Processor의 멀티 스레드 수동 데이터 공급에 적합하다고는 하지만, 구독자 접근법과 싱크 접근법을 같이 쓸 순 없다:FluxProcessor를 소스Publisher를 구독하도록 만들거나FluxSink로 수동으로 데이터를 공급해야 한다.
next로 인한 오버 플로우는 Processor와 관련 설정에 따라 두 가지 방법으로 처리된다:
- unbounded 프로세서는 자체에서 드랍 또는 버퍼링해서 오버플로우를 처리한다.
- bounded 프로세서는 막아버리거나,
IGNORE전략에선 선회하고, 또는sink에 명시된 다른overflowStrategy를 따른다.
4.7.3. Overview of Available Processors
리액터 코어가 제공하는 Processor는 몇 가지 유형으로 나뉜다. 모든 프로세서 시맨틱스가 동일한 것은 아니지만, 대략적으로 세 가지 카테고리로 나뉜다. 다음은 프로세서 세 종류에 대한 간략한 설명이다:
- direct (
DirectProcessor,UnicastProcessor): 이 프로세서는 직접적인 유저 액션으로만 데이터를 푸쉬할 수 있다 (Sink메소드를 직접 호출). - synchronous (
EmitterProcessor,ReplayProcessor): 이 프로세서는 유저 인터랙션으로도 데이터를 푸쉬할 수 있고, 업스트림Publisher를 구독하고 동기로 데이터를 비움으로써(drain) 데이터를 푸쉬할 수도 있다.
이벤트를 여러 스레드로 보내는 방법 중 하나는
EmitterProcessor와publishOn(Scheduler)을 사용하는 것이다. 이 조합으로, reactor-extra 3.3.0에서 제거된,Unsafe연산자를 사용하던 이전TopicProcessor를 대신할 수도 있다.
Direct Processor
Direct Processor는 0개 이상의 Subscriber에게 신호를 보낼 수 있는 프로세서다. DirectProcessor#create() 스태틱 팩토리 메소드로 생성하며, 인스턴스를 만들기가 가장 쉽다. 반면에 backpressure를 처리하지 못한다는 제약이 있다. 결과적으로 DirectProcessor는 요소 N개를 푸쉬했는데 구독자 중 하나라도 N개 미만을 요청했다면, 구독자에게 IllegalStateException 신호를 보낸다.
Processor가 종료되면 (일반적으로 싱크의 error(Throwable) 또는 complete() 메소드 호출로), 다른 구독자로 구독할 수는 있지만, 구독하는 즉시 종료 신호만 반복한다.
Unicast Processor
Unicast Processor는 내부 버퍼로 backpressure를 처리할 수 있다. 대신 Subscriber는 최대 한 개만 가능하다.
UnicastProcessor는 direct 프로세서보다 옵션이 몇 가지 더 있기 때문에 create 스태틱 팩토리 메소드도 몇 가지 더 존재한다. 예를 들어, 기본적으로는 언바운드다: Subscriber가 아직 데이터를 요청하지 않은 상태에서 푸쉬하는 모든 데이터는 전부 버퍼에 담는다.
커스텀 Queue 구현체를 사용하면 create 팩토리 메소드에서 내부 버퍼링을 변경할 수 있다. 큐에 제한이 생기면, 프로세서는 버퍼가 가득 차고 다운스트림 요청을 충분히 받지 않은 경우 데이터 푸쉬를 거부할 수 있다.
이 bounded 모드에선 콜백으로 프로세서를 빌드해서, 거절한 요소마다 콜백을 실행해 cleanup할 수 있다.
Emitter Processor
emitter Processor는 여러 구독자에게 값을 보내면서 각 구독자의 backpressure 신호를 준수할 수 있다. 또한 Publisher를 구독해서 동시에 신호를 릴레이할 수도 있다.
초기에 구독자가 없을 때에도 설정한 bufferSize까지 데이터 푸쉬를 허용한다. 이후에도 데이터를 소비해가는 Subsriber가 없다면 프로세서가 비워질 때까지 onNext 블록을 호출한다 (이때까지만 동시에 가능하다).
따라서 첫 번째로 구독하는 Subscriber는 최대 bufferSize 만큼의 요소를 전달받는다. 그러나 이후에는 다른 추가 구독자에게 더 이상 신호를 재전송하지 않는다. 이러한 구독자는 구독 이후에 프로세서가 푸쉬한 신호만 받는다. 내부 버퍼는 여전히 backpressure 목적으로 사용한다.
기본적으로 모든 구독자가 취소하면 (기본적으로 모두 구독을 중단했음을 의미), 내부 버퍼를 비우고 새 구독자를 받지 않는다. 이 동작은 create 스태틱 팩토리 메소드에 autoCancel 파라미터를 넘겨 변경할 수 있다.
Replay Processor
replay Processor는 sink()로 직접 생성한 데이터와 업스트림 Publisher에서 받은 데이터를 모두 캐시하고 이후 구독자에게 재전송한다.
여러 가지 설정으로 만들 수 있다:
- 요소 한 개만 캐시한다 (
cacheLast). - 히스토리 일부만 캐시하거나 (
create(int)), 전체를 (create()) 캐시한다. - 시간을 기반으로 반복되는 윈도우를 캐시한다 (
createTimeout(Duration)). - 히스토리 크기와 시간 윈도우 조합으로 캐시한다 (
createSizeOrTimeout(int, Duration)).
“Reactor Core Features” 수정 제안하기
Next :Kotlin support
리액터 코틀린 지원 한글 번역
전체 목차는 여기에 있습니다.