스프링 클라우드 슬루스 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
이번 섹션에선 Spring Cloud Sleuth를 자세히 파헤쳐본다. 여기서 배우는 핵심 기능들은 그대로 사용할 수도 있고, 커스텀할 수도 있다. 혹시 아직 읽어보지 않았다면 “Spring Cloud Sleuth 시작하기“와 “Spring Cloud Sleuth 사용 가이드” 섹션으로 먼저 기초를 다지고 오는 것이 좋다.
목차
- 4.1. Context Propagation
- 4.2. Sampling
- 4.3. Baggage
- 4.4. OpenZipkin Brave Tracer Integration
- 4.5. Sending Spans to Zipkin
- 4.6. Log integration
- 4.7. Self Documenting Spans
- 4.8. Traces Actuator Endpoint
- 4.9. What to Read Next
4.1. Context Propagation
트레이스Trace는 헤더를 전파하는 식으로 서비스와 서비스를 연결해준다. 기본적으론 B3 포맷의 헤더를 사용하는데, 다른 데이터 형식과 마찬가지로, trace ID와 span ID가 B3와 호환만 된다면 원하는 다른 헤더 포맷을 설정할 수 있다. B3의 가장 눈에 띄는 특징은, trace ID와 span ID가 UUID가 아닌 소문자로 이루어진 16진수라는 점이다. trace 식별자 외에 다른 속성(Baggage)도 요청과 함께 전달할 수 있는데, 리모트 Baggage는 사전에 정의되어야 하지만 그 외는 유연하게 사용할 수 있다.
기본으로 제공하는 메커니즘을 통해 헤더를 전파propagation하려면 spring.sleuth.propagation.type 프로퍼티를 이용하면 된다. 값을 여러 개 지정하면 더 다양한 트레이싱propagation 헤더를 전파한다.
Brave의 경우 전파propagation 타입으로 AWS, B3, W3C를 지원한다.
컨텍스트 전파 로직을 커스텀하는 자세한 방법은 이 문서에 있는 “how to 섹션“에서 확인할 수 있다.
4.2. Sampling
Spring Cloud Sleuth에선 각 요청을 추적할지 결정하는 일sampling decision을 트레이서tracer 구현체로 위임한다. 하지만 때에 따라서는 샘플링 여부sampling decision를 런타임에 결정해야 하는 경우가 있다.
예를 들어 특정 클라이언트 span은 리포트하지 않을 수도 있다. 이럴 땐 spring.sleuth.web.client.skip-pattern에 스킵할 경로의 패턴을 설정해주면 된다. 아니면 org.springframework.cloud.sleuth.SamplerFunction<org.springframework.cloud.sleuth.http.HttpRequest>의 커스텀 구현체를 제공해 언제 주어진 HttpRequest를 샘플링하지 않을지 정의해도 된다.
4.3. Baggage
분산 트레이싱distributed tracing은 필드들을 내부로 전파하고, 여러 서비스 간에 전파하는 방식으로 트레이스trace를 서로 연결시킴으로써 동작한다. 전파하는 필드 중에는 대표적으로 traceId와 spanId가 있다. 이런 필드들은 컨텍스트에 보관하는데, 여러 서비스를 거치더라도 일관성을 유지하고 싶은 필드가 있다면 컨텍스트에 더 추가해도 된다. 이렇게 별도로 추가하는 필드는 간단히 “Baggage”라고 부른다.
Sleuth를 사용한다면, 트레이스trace 컨텍스트에 담을 수 있는 baggage를 직접 정의할 수 있다 (ex. 어떤 헤더명을 사용할 건지 등).
다음은 Spring Cloud Sleuth API를 사용해 baggage 값을 설정하는 예시다:
try (Tracer.SpanInScope ws = this.tracer.withSpan(initialSpan)) {
BaggageInScope businessProcess = this.tracer.createBaggage(BUSINESS_PROCESS).set("ALM");
BaggageInScope countryCode = this.tracer.createBaggage(COUNTRY_CODE).set("FO");
try {
현시점에는 baggage 항목의 개수나 크기에 제한을 두지 않았다. 하지만 baggage가 너무 많으면 시스템 처리량이 줄어들거나 RPC 지연 시간이 늘어날 수 있다는 점을 명심해두자. baggage가 극단적으로 많아지면 전송 계층transport-level 메시지나 헤더 허용량을 초과하게 돼, 애플리케이션이 비정상 종료crash될 수 있다.
단순히 이름을 매핑하는 것과 같이, 특별한 설정이 필요 없는 필드들은 프로퍼티를 통해 정의할 수 있다:
spring.sleuth.baggage.remote-fields: 원격 서비스에 전파할 헤더 이름의 목록spring.sleuth.baggage.local-fields: 로컬에 전파할 이름 목록
이 키에는 프리픽스가 적용되지 않는다. 설정한 값을 그대로 사용한다.
이 프로퍼티 중 하나에 이름을 설정하면 그 이름을 가진 Baggage가 생성된다.
baggage 값을 Slf4j의 MDC로 자동 설정하고 싶다면, spring.sleuth.baggage.correlation-fields 프로퍼티에 허용할 로컬 또는 원격 키 목록을 설정해야 한다. 예를 들어 spring.sleuth.baggage.correlation-fields=country-code와 같이 설정하면 MDC에 country-code라는 baggage의 값을 세팅한다.
참고로, 추가한 필드는 그 다음 다운스트림 트레이스trace 컨텍스트부터 전파되어 MDC에 추가된다. 추가한 필드를 현재 트레이스trace 컨텍스트에서 즉시 MDC에 추가하고 싶다면, 필드를 설정할 때 업데이트 시 플러시까지 처리하도록 구성해야 한다:
// configuration
@Bean
BaggageField countryCodeField() {
return BaggageField.create("country-code");
}
@Bean
ScopeDecorator mdcScopeDecorator() {
return MDCScopeDecorator.newBuilder()
.clear()
.add(SingleCorrelationField.newBuilder(countryCodeField())
.flushOnUpdate()
.build())
.build();
}
// service
@Autowired
BaggageField countryCodeField;
countryCodeField.updateValue("new-value");
MDC에 항목을 추가하게 되면 애플리케이션 성능이 급격히 떨어질 수도 있다는 점을 잊지 말기를!
span을 baggage 항목으로 검색할 수 있으려면 baggage 항목들을 태그로도 추가해야 한다. 이땐 허용할 baggage 키 목록과 함께 spring.sleuth.baggage.tag-fields 값을 설정해주면 된다. 이 기능을 비활성화하려면 spring.sleuth.propagation.tag.enabled=false 프로퍼티를 전달해야 한다.
4.3.1. Baggage versus Tags
트레이스trace ID와 마찬가지로 Baggage는 보통 헤더의 형태로 메시지 또는 요청에 추가된다. 태그는 span에 담아 Zipkin에 전송되는 키 값 쌍이다. 반면 Baggage 값은 기본적으로 span에 추가하지 않으므로, 설정을 수정해주지 않으면 Baggage를 기준으로 span을 검색할 수 없다.
baggage를 태그로도 만들려면 다음과 같이 spring.sleuth.baggage.tag-field 프로퍼티를 사용해라:
spring:
sleuth:
baggage:
foo: bar
remoteFields:
- country-code
- x-vcap-request-id
tagFields:
- country-code
4.4. OpenZipkin Brave Tracer Integration
Spring Cloud Sleuth는 spring-cloud-sleuth-brave 모듈에 있는 브릿지를 통해 OpenZipkin Brave 트레이서tracer와 통합된다. 이번 섹션에선 기능별로 Brave와 어떻게 통합되는지 설명한다.
Sleuth API와 Brave API 중 무엇을 사용할지는 코드에서 직접 선택할 수 있다 (e.g. Sleuth의 Tracer와 Brave의 Tracer 중 무엇을 사용할지). Brave의 트레이서tracer 구현체 API를 직접 사용하고 싶다면 Brave 문서에서 자세한 내용을 참고하면 된다.
4.4.1. Brave Basics
가장 많이 접하게 되는 핵심 타입은 다음과 같다:
brave.SpanCustomizer- 현재 진행 중인 span을 변경한다brave.Tracer- 상황에 맞게 span을 새로 시작할 수 있다
다음은 OpenZipkin Brave 프로젝트와 관련된 주요 사이트들이다:
4.4.2. Brave Sampling
샘플링은 Zipkin과 같은 트레이싱tracing 백엔드에만 적용되는 개념이다. 참고로, trace ID는 샘플링하는 비율에 관계없이 로그에 남는다. 샘플링은 모든 요청을 추적하는 대신에, 일부 요청만 지속적으로 추적해서 시스템 과부하를 방지한다.
샘플링 비율은 spring.sleuth.sampler.rate 프로퍼티로 조절하며, 초당 10개의 트레이스trace를 추적하는 게 기본이다. 로깅 이외의 다른 Sleuth 코드를 만나는 시점에 정해진 비율로 샘플링을 시작한다. 초당 100개 이상의 트레이스trace를 추적해야 한다면 트레이싱tracing 시스템에 과부하가 걸릴 수 있으므로 반드시 주의해서 사용해야 한다.
샘플러는 아래 예제처럼 자바 코드로도 설정할 수 있다:
@Bean
public Sampler defaultSampler() {
return Sampler.ALWAYS_SAMPLE;
}
HTTP 헤더
b3를1로 설정하거나 메시지 전송 시spanFlags헤더를1로 설정하면, 샘플러 설정과는 상관 없이 현재 요청을 강제로 샘플에 포함시킬 수 있다.
기본적으로 샘플러는 리프레시 스코프 메커니즘 내에서 동작한다. 즉, 런타임에 샘플링 프로퍼티를 변경할 수 있고, 애플리케이션을 리프레시하면 변경 사항이 반영된다. 하지만 샘플러를 감싼 프록시를 생성하고서 샘플러를 너무 일찍 호출하면 (ex. @PostConstruct 어노테이션을 선언한 메소드 안에서 호출), 데드락이 발생할 수 있다. 이럴 땐 샘플러 빈을 생성하는 코드를 직접 작성하거나, spring.sleuth.sampler.refresh.enabled 프로퍼티를 false로 설정해 리프레시 스코프 지원을 비활성해라.
4.4.3. Brave Baggage Java configuration
위에서 설명한 것들보다 더 많은 것을 커스텀해야 한다면, 프로퍼티를 정의하지 말고 대신 사용하는 baggage 필드에 필요한 @Bean을 설정해라.
BaggagePropagationCustomizer는 baggage 필드를 세팅한다.SingleBaggageField를 추가해Baggage의 헤더명을 제어한다.CorrelationScopeCustomizer는 MDC 필드를 세팅한다.SingleCorrelationField를 추가해Baggage의 MDC 이름을 변경하거나, 업데이트가 발생할 때마다 플러시한다.
4.4.4. Brave Customizations
brave.Tracer 객체는 sleuth가 전부 다 관리해주기 때문에, 사용자가 직접 컨트롤할 일은 거의 없다. 하지만 sleuth는 다양한 Customizer 타입을 지원하기 때문에, 자동 설정이나 프로퍼티로 해결되지 않는 것들도 원한다면 직접 수정해 사용할 수 있다.
다음 중 하나를 Bean으로 정의하면 Sleuth가 그 코드를 실행해 관련 동작을 커스텀해준다:
RpcTracingCustomizer- RPC 태깅 및 샘플링 정책 커스텀HttpTracingCustomizer- HTTP 태깅 및 샘플링 정책 커스텀MessagingTracingCustomizer- 메시지 태깅 및 샘플링 정책 커스텀CurrentTraceContextCustomizer- correlation같은 decorator들을 통합하는 용도BaggagePropagationCustomizer- 처리 중인 baggage 필드를 헤더로 전파하는 용도CorrelationScopeDecoratorCustomizer- MDC (로깅) 필드 correlation같은 스코프 데코레이션scope decoration 커스텀
Brave Sampling Customizations
클라이언트/서버 샘플링이 필요한 경우, brave.sampler.SamplerFunction<HttpRequest> 타입의 빈을 등록하고, 클라이언트 샘플러 빈의 이름은 sleuthHttpClientSampler로, 서버 샘플러 빈은 sleuthHttpServerSampler로 지정하면 된다.
간단히 빈을 주입받고 싶으면 @HttpClientSampler와 @HttpServerSampler 어노테이션을 사용하면 되고, 빈의 이름은 각 어노테이션에 정의된 스태틱 문자열 NAME 필드를 참조하면 된다.
경로를 기반으로 동작하는 샘플러 정책을 만들고 싶다면, Brave 레포지토리에 있는 예시를 참고해라. github.com/openzipkin/brave/tree/master/instrumentation/http#sampling-policy
HttpTracing 빈을 처음부터 다시 작성하고 싶다면, SkipPatternProvider 인터페이스를 사용해, 샘플링하지 않을 span의 URL Pattern을 반환할 수 있다. 다음은 서버 측 Sampler<HttpRequest> 안에서 SkipPatternProvider를 사용하는 예시다.
@Configuration(proxyBeanMethods = false)
class Config {
@Bean(name = HttpServerSampler.NAME)
SamplerFunction<HttpRequest> myHttpSampler(SkipPatternProvider provider) {
Pattern pattern = provider.skipPattern();
return request -> {
String url = request.path();
boolean shouldSkip = pattern.matcher(url).matches();
if (shouldSkip) {
return false;
}
return null;
};
}
}
4.4.5. Brave Messaging
Sleuth는 카프카나 JMS와 같은 메시지 처리 시스템을 계측instrumentation하기 위한 MessagingTracing 빈을 자동으로 설정해준다.
메시지 처리를 추적하기 위한 프로듀서producer / 컨슈머consumer 샘플링 로직을 커스텀해야 하는 경우, brave.sampler.SamplerFunction<MessagingRequest> 타입의 빈을 등록하고, 프로듀서producer 샘플러 빈의 이름은 sleuthProducerSampler로, 컨슈머consumer 샘플러는 sleuthConsumerSampler로 지정하기만 하면 된다.
간단히 빈을 주입받고 싶으면 @ProducerSampler와 @ConsumerSampler 어노테이션을 사용하면 되고, 빈의 이름은 각 어노테이션에 정의된 스태틱 문자열 NAME 필드를 참조하면 된다.
Ex. 다음은 “alerts” 채널을 제외한 컨슈머consumer 요청을 초당 100개씩 추적하는 샘플러다. 그외 다른 요청의 샘플링 비율은 Tracing 컴포넌트에서 제공하는 글로벌 설정을 따른다.
@Configuration(proxyBeanMethods = false)
class Config {
@Bean(name = ConsumerSampler.NAME)
SamplerFunction<MessagingRequest> myMessagingSampler() {
return MessagingRuleSampler.newBuilder().putRule(channelNameEquals("alerts"), Sampler.NEVER_SAMPLE)
.putRule(Matchers.alwaysMatch(), RateLimitingSampler.create(100)).build();
}
}
자세한 내용은 github.com/openzipkin/brave/tree/master/instrumentation/messaging#sampling-policy를 참고해라.
4.4.6. Brave Opentracing
Brave와 OpenTracing은 io.opentracing.brave:brave-opentracing 브릿지를 통해 통합할 수 있다. OpenTracing Tracer는 클래스패스에 넣어주기만 하면 자동으로 설정된다.
4.5. Sending Spans to Zipkin
Spring Cloud Sleuth는 분산 추적 시스템distributed tracing system 중 하나인 OpenZipkin과 다양한 방식으로 통합할 수 있다. 트레이서tracer 구현체로 무엇을 선택했는지와는 상관 없이, 클래스패스에 spring-cloud-sleuth-zipkin을 추가하기만 하면 Zipkin으로 span을 전송할 수 있다. 전송 방식은 HTTP와 메시지 처리 방식 중에 선택할 수 있다. 자세한 방법은 “how to 섹션“을 참고해라.
span이 닫히게 되면 HTTP를 통해 Zipkin으로 전송된다. 통신은 비동기로 이루어지는데, URL은 다음과 같이 spring.zipkin.baseUrl 프로퍼티로 설정할 수 있다:
spring.zipkin.baseUrl: https://192.168.99.100:9411/
Zipkin을 서비스 디스커버리를 통해 찾아야 한다면 URL에 Zipkin의 서비스 ID를 넣으면 된다. 다음 예제에선 zipkinserver가 Zipkin의 서비스 ID다:
spring.zipkin.baseUrl: https://zipkinserver/
이 기능을 비활성화하려면 spring.zipkin.discovery-client-enabled를 false로 설정하면 된다.
이 클라이언트 디스커버 기능이 활성화되면, Sleuth는 LoadBalancerClient를 사용해 Zipkin 서버의 URL을 찾는다. 이는 로드 밸런싱 설정을 구성할 수 있음을 의미한다.
클래스패스에 web, rabbit, activemq, kafka가 둘 이상 들어있는 경우엔, zipkin으로 span을 어떻게 전송할지 지정해줘야 할 수 있다. 이땐 spring.zipkin.sender.type 프로퍼티에 web, rabbit, activemq, kafka 중 하나를 설정해주면 된다. 다음은 sender 타입을 web으로 설정하는 예시다:
spring.zipkin.sender.type: web
리액티브 애플리케이션을 실행할 때는 WebClient 기반 span sender를 사용한다. 그 외는 RestTemplate 기반으로 동작한다.
HTTP를 통해 Zipkin으로 span을 전송할 때 사용하는 RestTemplate을 커스텀하려면, @Configuration 어노테이션을 선언한 스프링 설정 클래스 안에 ZipkinRestTemplateCustomizer 빈을 등록하면 된다.
@Bean
ZipkinRestTemplateCustomizer myZipkinRestTemplateCustomizer() {
return new ZipkinRestTemplateCustomizer() {
@Override
public RestTemplate customizeTemplate(RestTemplate restTemplate) {
// customize the RestTemplate
return restTemplate;
}
};
}
반면, RestTemplate 객체를 생성하는 로직을 통으로 제어하려면 ZipkinRestTemplateProvider 타입 빈을 생성해야 한다.
@Bean
ZipkinRestTemplateProvider myZipkinRestTemplateProvider() {
return MyRestTemplate::new;
}
기본적으로 API 경로는 인코더 버전에 따라 api/v2/spans 또는 api/v1/spans로 설정된다. API 경로를 커스텀하려면 아래 프로퍼티를 사용하면 된다 (하위 경로가 없다면, ““로 설정해라):
spring.zipkin.api-path: v2/path2
리액티브 애플리케이션의 경우, 간단한 WebClient.Builder 인스턴스가 하나 만들어진다. 자체 인스턴스를 제공하거나 기존 인스턴스를 재사용하고 싶다면, ZipkinWebClientBuilderProvider 빈을 만들어야 한다.
@Bean
ZipkinWebClientBuilderProvider myZipkinWebClientBuilderProvider() {
// create your own instance or inject one from the Spring Context
return () -> WebClient.builder();
}
4.5.1. Custom service name
보통 Zipkin으로 span을 전송할 땐, span의 서비스명이 spring.application.name 프로퍼티 값과 동일하게 세팅되길 바랄 거다. 기본적으로 Sleuth도 그렇게 동작한다. 하지만 예외적인 상황도 존재한다. 때에 따라서는 애플리케이션에서 만드는 모든 span에 어떤 다른 서비스명을 지정해야 하는 경우도 있다. 이럴 땐 애플리케이션에 다음 프로퍼티를 지정해 서비스명을 재정의할 수 있다 (아래 예제는 서비스 이름을 myService로 정의한다):
spring.zipkin.service.name: myService
4.5.2. Host Locator
이 섹션에선 서비스 디스커버리에서 호스트를 정의하는 방법에 대해 설명한다. 서비스 디스커버리를 통해 Zipkin을 찾는 것에 대한 내용이 아니다.
특정 span에 대한 호스트 정보를 정의하려면, 호스트명과 포트를 알 수 있어야 한다. 기본적으론 서버 프로퍼티에서 호스트명과 포트를 가져온다. 이 값들이 설정돼 있지 않으면 네트워크 인터페이스에서 호스트명을 검색해본다.
클라이언트 디스커버리를 활성화한 상태에서, 서비스 레지스트리에 등록한 인스턴스로 호스트명을 검색하려면, 다음과 같이 spring.zipkin.locator.discovery.enabled 프로퍼티를 설정해야 한다 (span을 HTTP 기반으로 리포트할 때와, 스트림 기반으로 리포트할 때 모두 적용할 수 있다):
spring.zipkin.locator.discovery.enabled: true
4.5.3. Customization of Reported Spans
Sleuth에서 생성하는 span의 이름은 고정돼있다. 하지만 간혹 태그 값에 따라 이름을 수정해야 할 때도 있다.
먼저 Sleuth는, 주어진 이름의 패턴에 따라 span 리포트를 자동으로 건너뛸 수 있는 SpanFilter 빈을 등록한다. spring.sleuth.span-filter.span-name-patterns-to-skip 프로퍼티에는 기본으로 건너뛸 span의 이름 패턴이 담겨 있다. spring.sleuth.span-filter.additional-span-name-patterns-to-skip 프로퍼티로는 기존 span 이름 패턴에 별도 패턴을 더 추가할 수 있다. 이 기능을 비활성화고 싶다면 spring.sleuth.span-filter.enabled를 false로 설정하면 된다.
Brave Customization of Reported Spans
이 섹션에서 설명하는 내용은 Brave 트레이서tracer에만 해당하는 내용이다.
span을 (Zipkin등 에) 리포트하기 전에, 어떤 식으로든 span을 수정하고 싶을 수 있다. 이럴 땐 SpanHandler를 구현하면 된다.
다음은 SpanHandler를 구현한 두 가지 빈을 등록하는 예시다:
@Bean
SpanHandler handlerOne() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span, Cause cause) {
span.name("foo");
return true; // keep this span
}
};
}
@Bean
SpanHandler handlerTwo() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span, Cause cause) {
span.name(span.name() + " bar");
return true; // keep this span
}
};
}
위 예제에서선 span을 (Zipkin 등으로) 리포트하기 직전에, foo bar로 이름을 변경한다.
4.5.4. Overriding the auto-configuration of Zipkin
Spring Cloud Sleuth는 2.1.0 버전부터 다양한 트레이싱 시스템tracing system으로 트레이스trace를 전송할 수 있게 지원한다. 이게 가능하려면 모든 트레이싱 시스템tracing system마다 Reporter<Span>과 Sender가 존재해야 한다. 기본으로 제공하는 빈을 재정의하려면, 정해진 이름을 사용해야 한다. 그러려면 각각 ZipkinAutoConfiguration.REPORTER_BEAN_NAME과 ZipkinAutoConfiguration.SENDER_BEAN_NAME을 사용하면 된다.
@Configuration(proxyBeanMethods = false)
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter(@Qualifier(ZipkinAutoConfiguration.SENDER_BEAN_NAME) MySender mySender) {
return AsyncReporter.create(mySender);
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
}
4.6. Log integration
Sleuth는 서비스 이름(%{spring.zipkin.service.name}, 또는 따로 설정하지 않은 경우 %{spring.application.name}), span ID(%{spanId}), trace ID(%{traceId}) 등의 변수를 사용해 로깅 컨텍스트를 구성한다. 덕분에 분산된 트레이스trace들 중 어떤 것에 대한 로그인지 손쉽게 파악하고, 서비스 문제 해결에 사용할 도구를 직접 선택할 수 있다.
에러 로그를 발견했다면 메시지 안에서 trace ID를 찾으면 된다. 이 값을 분산 트레이싱 시스템distributed tracing system에 붙여넣으면, 최초 요청이 아주 많은 서비스를 거쳐 전달됐더라도, 전체 트레이스trace를 시각화할 수 있다.
backend.log: 2020-04-09 17:45:40.516 ERROR [backend,5e8eeec48b08e26882aba313eb08f0a4,dcc1df555b5777b3] 97203 --- [nio-9000-exec-1] o.s.c.s.i.web.ExceptionLoggingFilter : Uncaught exception thrown
frontend.log:2020-04-09 17:45:40.574 ERROR [frontend,5e8eeec48b08e26882aba313eb08f0a4,82aba313eb08f0a4] 97192 --- [nio-8081-exec-2] o.s.c.s.i.web.ExceptionLoggingFilter : Uncaught exception thrown
위 예제에선 trace ID가 5e8eeec48b08e26882aba313eb08f0a4인 것을 확인할 수 있다. 로그 관련 설정들은 Sleuth가 자동으로 세팅한다. spring.sleuth.enabled=false 프로퍼티를 이용해 Sleuth를 비활성화하거나, logging.pattern.level 프로퍼티를 직접 변경하면 로그를 비활성화할 수 있다.
Kibana, Splunk 등과 같은 로그 집계 툴을 사용하고 있다면, 발생한 순서에 따라 이벤트를 정렬할 수 있다. 예를 들어 키바나를 사용하고 있다면 다음과 같은 화면을 볼 수 있다:
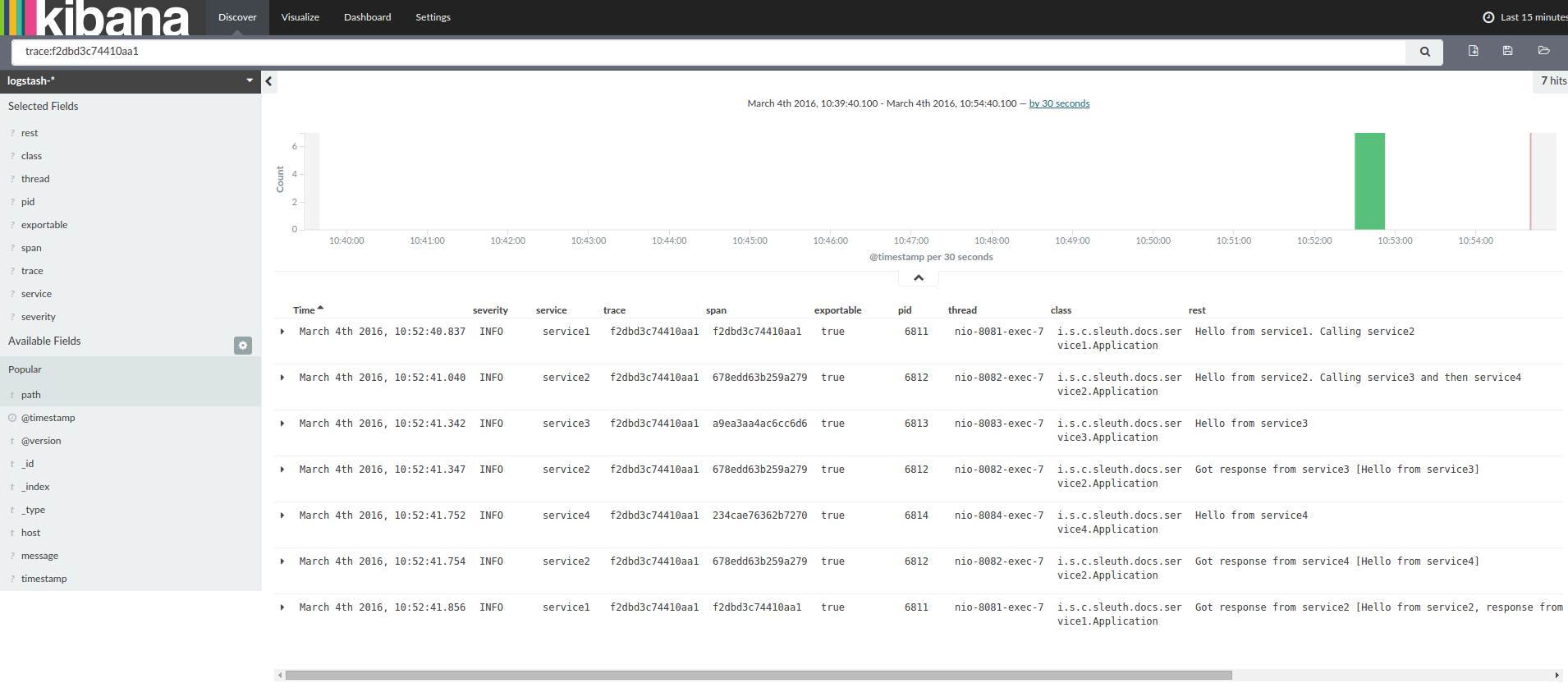
Logstash를 사용한다면, 다음은 Logstash의 Grok 패턴 예시다:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}
Grok을 Cloud Foundry의 로그와 함께 사용하려면 아래 패턴을 사용해야 한다:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
date {
match => ["timestamp", "ISO8601"]
}
mutate {
remove_field => ["timestamp"]
}
}
4.6.1. JSON Logback with Logstash
간혹, 로그를 텍스트 파일에 저장하는 대신, Logstash에서 바로 사용할 수 있는 JSON 파일에 저장하고 싶을 때가 있다. 로그를 JSON 파일에 기록하려면 다음과 같이 설정해주면 된다 (가독성을 위해 의존성은 groupId:artifactId:version 형태로 나타냈다).
의존성 세팅
- 클래스패스에 반드시 Logback이 존재해야 한다 (
ch.qos.logback:logback-core). - Logstash Logback 인코더를 추가한다. 예를 들어,
4.6버전을 사용하려면net.logstash.logback:logstash-logback-encoder:4.6을 추가해라.
Logback 세팅
아래 Logback 설정 파일 (logback-spring.xml) 예시를 살펴보자.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"timestamp": "@timestamp",
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{traceId:-}",
"span": "%X{spanId:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>
이 Logback 설정에 따르면:
- 애플리케이션의 정보를 JSON 형식으로
build/${spring.application.name}.json파일에 기록한다. - 추가적인 appender 두 가지를 주석 처리했다 (logstash, flatfile 로그 파일) .
- 이전 섹션에서 보여준 예시와 동일한 로그 패턴을 사용한다.
직접 정의한
logback-spring.xml을 사용한다면,application프로퍼티 파일이 아닌bootstrap에spring.application.name을 전달해야 한다. 그렇지 않으면 커스텀 logback 파일에서 프로퍼티를 제대로 읽어들이지 못한다.
4.7. Self Documenting Spans
DocumentedSpan 인터페이스를 도입한 덕분에, span 설정을 보면 어떤 작업이 수행된 것인지 바로 파악할 수 있게 됐다. Sleuth는 소스 코드를 분석해 허용하는 태그 키와 이벤트 이름 등 모든 span의 특성들이 포함된 문서를 생성한다. 자세한 내용은 부록: Sleuth Span에서 확인할 수 있다.
4.8. Traces Actuator Endpoint
Spring Cloud Sleuth는 액추에이터 엔드포인트 traces를 함께 제공해서, 작업이 완료된 span을 저장하고 조회할 수 있다. 이 엔드포인트에 HTTP GET 메소드를 통해 질의하면 간단하게 저장된 span의 목록을 조회할 수 있고, HTTP POST 메소드를 통해 질의하면 목록을 조회하고 동시에 비울 수 있다.
span을 저장하는 대기열의 사이즈는 management.endpoint.traces.queue-size 프로퍼티를 통해 조정할 수 있다.
액추에이터 엔드포인트에서 변경할 수 있는 설정들은 Spring Boot Actuator: Production-ready Features 섹션을 참조해라.
4.9. What to Read Next
이번 섹션에서 설명한 클래스들을 자세히 알아보고 싶다면 소스 코드에서 직접 찾아보면 된다. 구체적으로 알고 싶은 게 있다면, how-to 섹션을 참고해라.
Spring Cloud Sleuth의 핵심 기능들에 어느정도 익숙해졌다면, 계속해서 Spring Cloud Sleuth의 통합 기능들에 대해 읽어봐라.
Next : “How-to” Guides
“How-to” Guides
스프링 클라우드 슬루스 how-to 가이드
전체 목차는 여기에 있습니다.