아파치 카프카 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
목차
5.1 Network Layer
네트워크 계층은 상당히 직관적인 NIO 서버이며, 자세히 설명하진 않을 거다. sendfile은 MessageSet 인터페이스에 writeTo 메소드를 제공하는 식으로 구현한다. 이렇게하면 프로세스에 전송할 데이터를 버퍼링하지 않고, 그대신 파일에 저장된 메세지 셋을 사용해 더 효율적인 transferTo를 활용할 수 있다. 스레딩 모델은 단일 acceptor 스레드와, 각각 커넥션을 고정된 수만큼 처리하는 N개의 프로세서 스레드다. 이 설계는 다른 곳에서 꽤 철저하게 테스트되었으며, 구현이 간단하고 빠른 것으로 밝혀졌다. 이 프로토콜은 꽤 간단하게 유지돼서, 향후 다른 언어로도 클라이언트를 구현할 수 있다.
5.2 Messages
메세지는 가변 길이 헤더와, 특정 구조를 강제하지 않는(opaque) 가변 길이의 키 바이트 배열, 값 바이트 배열로 구성된다. 헤더 형식은 다음 섹션에서 설명한다. 키와 값은 구조를 미리 정의하지 않은채로 두는 게 맞다. 지금도 직렬화 라이브러리에선 많은 것들이 개선되고 있으며, 특정 값을 선택하게 되면 모든 용도로 활용하기 어려울 수도 있다. 당연히 카프카를 사용하는 어플리케이션은 특정 직렬화 타입을 지정할 수 있다. RecordBatch 인터페이스는 메세지에 사용할 수 있는 이터레이터로, NIO Channel에서 벌크로 읽기/쓰기를 수행하기 위한 특수 메소드를 가지고 있다.
5.3 Message Format
메세지(일명 레코드)는 항상 배치로 작성된다. 메세지 배치 처리를 기술적으로 표현하면 레코드 배치라고 하며, 레코드 배치는 하나 이상의 레코드를 가진다. 구버전에선 레코드를 하나만 가진 레코드 배치가 있을 수도 있다. 레코드 배치와 레코드엔 자체 헤더가 있다. 각 헤더 형식은 아래에서 설명한다.
5.3.1 Record Batch
다음은 RecordBatch의 디스크 저장 포맷이다.
baseOffset: int64
batchLength: int32
partitionLeaderEpoch: int32
magic: int8 (current magic value is 2)
crc: int32
attributes: int16
bit 0~2:
0: no compression
1: gzip
2: snappy
3: lz4
4: zstd
bit 3: timestampType
bit 4: isTransactional (0 means not transactional)
bit 5: isControlBatch (0 means not a control batch)
bit 6~15: unused
lastOffsetDelta: int32
firstTimestamp: int64
maxTimestamp: int64
producerId: int64
producerEpoch: int16
baseSequence: int32
records: [Record]
압축을 활성화하면 압축된 레코드 데이터를 레코드 수에 따라 그대로 직렬화한다.
CRC는 attribute부터 배치 끝까지 있는 데이터를 커버한다 (즉, CRC 뒤에 나오는 모든 바이트). crc는 magic 바이트 뒤에 나온다. 따라서 클라이언트는 batchLength와 magic 바이트 사이에 있는 바이트를 어떻게 해석할지 결정하기 전에 먼저 magic 바이트를 파싱해야 한다. 파티션 리더 epoch 필드는 CRC 계산에 포함시키지 않는데, 브로커가 받는 배치마다 이 필드를 매번 할당하면 CRC를 다시 계산해야 하기 때문이다. 계산에는 CRC-32C (Castagnoli) 다항식을 사용한다.
컴팩션 시: 이전 메세지 포맷과는 달리, magic v2 이상에선 로그를 정리해도 기존 배치의 첫 번째와 마지막 오프셋/시퀀스 번호를 유지한다. 로그를 다시 로드할 때 프로듀서의 상태를 복원하기 위해서다. 예를 들어, 마지막 시퀀스 번호를 유지하지 않는다면, 파티션 리더가 실패하고나면 프로듀서는 OutOfSequence 오류를 만날 수도 있다. 중복을 확인하려면 베이스가 될 시퀀스 번호를 보존해야 한다 (브로커는 Produce 요청을 받으면, 요청으로 받은 배치의 첫 번째와 마지막 시퀀스 번호를, 해당 프로듀서의 마지막 시퀀스 번호와 비교해서 중복을 체크한다). 결과적으로, 배치 안에 있는 모든 레코드를 정리하고서도, 프로듀서의 마지막 시퀀스 번호를 유지하기 위해 배치를 남겨뒀다면, 로그에 빈 배치가 있을 수도 있다. 여기서 한 가지 특이한 점은, firstTimestamp 필드는 컴팩션 중에 보존되지 않기 때문에, 압축할 때 배치의 첫 번째 레코드가 사라지면 변경된다는 점이다.
5.3.1.1 Control Batches
컨트롤 배치에는 컨트롤 레코드라 부르는 단일 레코드가 들어있다. 컨트롤 레코드는 어플리케이션에 전달되지 않는다. 대신 컨슈머가 중단된 트랜잭션 메세지를 필터링하는 데 사용한다.
컨트롤 레코드의 키는 다음 스키마를 따른다:
version: int16 (current version is 0)
type: int16 (0 indicates an abort marker, 1 indicates a commit)
컨트롤 레코드의 값에 대한 스키마는 타입에 따라 다르다. 이 값은 클라이언트에서는 알아볼 수 없다.
5.3.2 Record
레코드 레벨 헤더는 카프카 0.11.0에서 도입됐다. 헤더를 사용하는 레코드의 디스크 저장 포맷은 아래에 기술했다.
length: varint
attributes: int8
bit 0~7: unused
timestampDelta: varint
offsetDelta: varint
keyLength: varint
key: byte[]
valueLen: varint
value: byte[]
Headers => [Header]
5.3.2.1 Record Header
headerKeyLength: varint
headerKey: String
headerValueLength: varint
Value: byte[]
Protobuf와 동일한 varint 인코딩을 사용한다. Protobuf에 대한 자세한 정보는 여기에서 확인할 수 있다. 레코드의 헤더 갯수도 varint로 인코딩된다.
5.3.3 Old Message Format
카프카 0.11 이전에는 메세지들을 전송하고, 메세지는 메세지 셋 안에 저장했다. 메세지 셋 안에서, 각 메세지는 자체 메타데이터를 가진다. 메세지 셋은 배열로 표현하긴 하지만, 이 프로토콜의 다른 배열 요소처럼 앞에 int32 array size가 나오진 않는다.
Message Set:
MessageSet (Version: 0) => [offset message_size message]
offset => INT64
message_size => INT32
message => crc magic_byte attributes key value
crc => INT32
magic_byte => INT8
attributes => INT8
bit 0~2:
0: no compression
1: gzip
2: snappy
bit 3~7: unused
key => BYTES
value => BYTES
MessageSet (Version: 1) => [offset message_size message]
offset => INT64
message_size => INT32
message => crc magic_byte attributes timestamp key value
crc => INT32
magic_byte => INT8
attributes => INT8
bit 0~2:
0: no compression
1: gzip
2: snappy
3: lz4
bit 3: timestampType
0: create time
1: log append time
bit 4~7: unused
timestamp => INT64
key => BYTES
value => BYTES
카프카 0.10 버전 이전에 유일하게 지원하는 메세지 포맷 버전(magic 값으로 나타내는)은 0이었다. 메세지 포맷 버전 1은 0.10 버전에서 타임스탬프 지원과 함께 도입됐다.
- 위에 있는 버전 2와 유사하게, 가장 낮은 attributes 비트는 압축 유형을 나타낸다.
- 버전 1에서 프로듀서는 항상 timestampType 비트를 0으로 설정해야 한다. 로그에 추가된 시간을 타임스탬프로 사용하는 토픽이라면 (브로커 레벨 설정 log.message.timestamp.type = LogAppendTime 또는 토픽 레벨 설정 message.timestamp.type = LogAppendTime으로 설정), 브로커가 메세지 셋에 있는 타임스탬프 타입과 타임스탬프를 덮어쓴다.
- attributes의 최상위 비트는 반드시 0으로 설정해야 한다.
메세지 포맷 버전 0, 1에선 카프카는 재귀 메세지를 통해 압축을 지원한다. 이땐 메세지의 attributes에 반드시 압축 유형 중 하나를 나타내도록 설정해야 하며, value 필드에는 이 유형으로 압축한 메세지 셋이 담길 거다. 이렇게 중첩된 메세지를 “내부 메세지(inner messages)”로, 래핑한 메세지를 “외부 메세지(outer message)”라고 표현한다. 외부 메세지에선 key가 null이어야 하며, 내부 메세지의 마지막 오프셋이 외부 메세지의 오프셋이 된다.
0 버전을 사용하는 재귀 메세지를 받으면 브로커는, 메세지의 압축을 풀고, 각 내부 메세지에 개별적으로 오프셋을 할당한다. 1 버전에선, 서버 측에서 다시 압축하지 않도록 래퍼 메세지에만 오프셋을 할당한다. 내부 메세지엔 상대적인 오프셋이 담긴다. 절대적인 오프셋 값은 마지막 내부 메세지에 할당된 오프셋에 해당하는, 외부 메세지의 오프셋으로 계산할 수 있다.
crc 필드에는 후속 메세지 바이트(즉, magic 바이트부터 value까지)의 CRC32(CRC-32C가 아님)가 담긴다.
5.4 Log
두 개의 파티션으로 구성된 “my_topic”이란 토픽의 로그는, 두 개의 디렉토리로 구성되며 (my_topic_0, my_topic_1), 이 디렉토리는 토픽 메세지를 가진 데이터 파일로 채워진다. 로그 파일은 “로그 엔트리”의 시퀀스 형식이다. 각 로그 엔트리는 메세지 길이를 저장하는 4바이트 정수 N과, 그 뒤에 나오는 N바이트 메세지로 이뤄진다. 각 메세지는 64비트 정수 오프셋으로 고유하게 식별된다. 오프셋은 해당 토픽 파티션으로 전송된 모든 메세지 스트림에서 이 메세지가 시작하는 바이트 상 위치를 제공한다. 각 메세지의 디스크 저장 포맷은 아래에 나온다. 각 로그 파일 이름은 파일 안에 있는 첫 번째 메세지의 오프셋으로 지정된다. 따라서 처음으로 만들어진 파일은 00000000000.kafka가 되고, 파일을 추가할 때마다 이전 파일에서 약 S바이트만큼 떨어진 정수 이름을 갖게된다. 여기서 S는 설정한 로그 파일의 최대 크기다.
레코드의 정확한 바이너리 포맷은 버전을 매기며 표준 인터페이스를 통해 관리하기 때문에, 문제가 딱히 없다면 다시 복사하거나 변환하지 않고도 프로듀서, 브로커, 클라이언트 간에 레코드 배치를 전송할 수 있다. 레코드의 디스크 저장 포맷에 대한 세부 정보는 이전 섹션에 나와있다.
메세지 오프셋을 메세지 id로 사용하는 건 좀 특이하다. 원래 아이디어는 프로듀서가 GUID를 생성하면 이 값을 id로 활용하고, GUID를 각 브로커의 오프셋과 매핑한 정보를 유지하는 거였다. 하지만 컨슈머가 각 서버에 대한 ID를 유지해야 하기때문에, 굳이 모든 서버에서 유일한 GUID를 사용하는 의미가 없다. 게다가, 랜덤 id와 오프셋의 매핑 정보를 유지하는 건 꽤 복잡해서, 본질적으로 완전한 persistent 랜덤 액세스 데이터 구조가 필요하며, 무거운 인덱스 구조를 디스크와 동기화해야 한다. 따라서 검색 구조를 단순화하기 위해, 파티션 id와 노드 id와 결합해 메세지를 고유하게 식별할 수 있는, 파티션 별로 간단한 atomic 카운터를 사용하기로 했었다. 이렇게하면 컨슈머 요청 당 디스크 검색을 여러 번 할 순 있지만, 검색 구조는 더 간단해진다. 그런데 일단 카운터로 정하고 보니, 오프셋을 직접 사용하는 게 자연스러워 보였다 — 결국 두 가지 모두 파티션에서 고유한, 단순히 증가하는 정수다. 오프셋은 컨슈머 API에 숨겨져 있기 때문에 궁극적으로 이 결정은 세부 구현 스펙이며, 더 효율적인 방법을 사용하기로 했다.
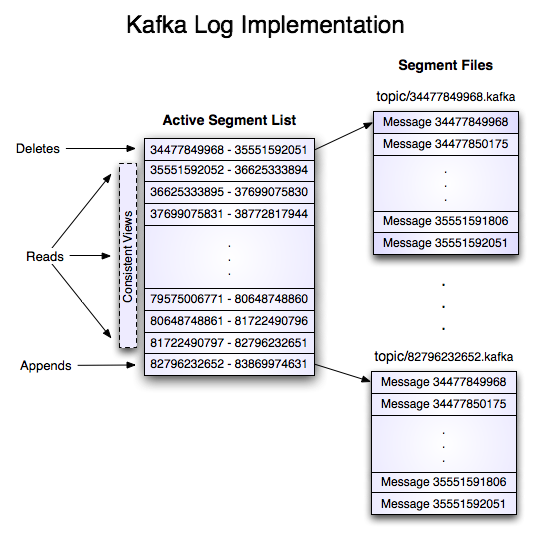
Writes
로그는 언제나 마지막 파일로 이동하는 순차 append를 허용한다. 이 파일은 설정한 크기(1GB등)에 도달하면 새 파일로 롤오버된다. 로그는 두 가지 설정 파라미터를 받는다: 이 갯수만큼 메세지를 쓰고나면 OS가 파일을 디스크로 플러시하는 M과, 이 시간만큼 경과하면 플러시를 강제하는 초 단위 시간 S. 이를 통해 보장하는 내구성은, 시스템이 충돌하면 최대 메세지 M개, 또는 S초 동안의 메세지를 유실할 수 있다.
Reads
읽기 요청은 메세지의 64비트짜리 논리적인 오프셋과, 최대 청크 크기 S바이트를 제공해서 수행한다. 읽기 요청 시엔 S바이트 버퍼에 담긴 메세지에 대한 이터레이터를 반환한다. S는 단일 메세지보다 큰 값을 설정하도록 의도했지만, 비정상적으로 큰 메세지가 있다면, 메세지를 읽는 데 성공할 때까지 버퍼 크기를 두 배로 늘리며, 그때마다 읽기를 여러 번 재시도할 수 있다. 메세지와 버퍼 사이즈의 최대치를 지정하면, 서버가 특정 크기보다 큰 메세지는 거절하게 만들 수 있으며, 클라이언트가 하나의 완전한 메세지를 가져가기 위해 읽어야 하는 최대값을 알려줄 수 있다. 읽기 버퍼는 메세지 일부만 가져온 상태로 끝나는 경우도 많으며, 사이즈 구분(delimiting)으로 쉽게 감지할 수 있다.
오프셋에서부터 읽어가는 실제 프로세스에선 먼저, 데이터가 저장된 로그 세그먼트 파일을 찾고, 전역 오프셋 값에서 파일 별 오프셋을 계산한 다음, 해당 파일 오프셋에서부터 읽어야 한다. 검색은 각 파일마다 유지되는 인메모리 범위에서 간단한 이진 검색 변형 알고리즘으로 수행한다.
로그에서는, 클라이언트가 “바로 지금”부터 구독을 시작할 수 있도록, 가장 최근에 작성한 메세지를 조회할 수 있다. 컨슈머가 SLA에서 지정한 일수 내에 데이터를 컨슘해가지 못했을 때도 유용하다. 이땐 클라이언트가 존재하지 않는 오프셋을 사용하려고 하면 OutOfRangeException을 받으며, 유스 케이스에 따라 자체적으로 리셋하거나 실패시킬 수 있다.
다음은 컨슈머에게 전송하는 결과 포맷이다.
MessageSetSend (fetch result)
total length : 4 bytes
error code : 2 bytes
message 1 : x bytes
...
message n : x bytes
MultiMessageSetSend (multiFetch result)
total length : 4 bytes
error code : 2 bytes
messageSetSend 1
...
messageSetSend n
Deletes
데이터를 삭제할 땐, 한 번에 로그 세그먼트 하나씩 삭제한다. 로그 매니저는 시간, 크기 메트릭을 활용해 삭제할만한 세그먼트를 식별한다. 시간 기반 정책에선, 레코드 타임스탬프를 고려해서 식별한다. 세그먼트 파일에서 가장 큰 타임스탬프(레코드 순서는 상관 없음)가 전체 세그먼트의 보존 기간을 결정한다. 크기 기반 보존 정책은 기본적으로 비활성화돼 있다. 활성화하면 로그 매니저는 파티션의 전반적인 크기가 설정한 제한 내에 다시 들어올 때까지, 가장 오래된 세그먼트 파일을 계속해서 삭제한다. 두 정책을 동시에 활성화한다면, 두 정책 중 하나에서라도 삭제 대상에 오른 세그먼트를 삭제한다. 데이터를 삭제하게 되면 세그먼트 리스트가 수정되는데, 일관된 뷰를 제공하는 copy-on-write 스타일 세그먼트 리스트를 구현해 읽기 잠금을 방지한다. 덕분에 삭제를 진행하는 동안에도 로그 세그먼트의 변경 불가능한 정적 스냅샷 뷰에서 바이너리 검색을 진행할 수 있다.
Guarantees
로그는 디스크에 플러시를 강제하기 전까지 기록할 최대 메세지 수를 제어하는 설정 파라미터 M을 제공한다. 기동 시에는, 최신 로그 세그먼트에 있는 모든 메세지를 순회해서, 각 메세지 엔트리가 유효한지 검증하는 로그 복구 프로세스를 실행한다. 메세지 엔트리의 크기와 오프셋의 합이 파일 길이보다 작고, 메세지 페이로드의 CRC32가 메세지와 함께 저장한 CRC와 일치하면 메세지 엔트리를 유효하다고 판단한다. 로그에서 메세지 손상을 감지하면, 마지막 유효한 오프셋까지 잘낸다.
반드시 처리해야 하는 데이터 손상은 두 종류다: 크래시로 인해 기록하지 않은 블록이 손실되는 절단(truncation)과, 의미 없는 블록이 파일에 추가되는 오염(corruption). 이게 가능한 이유는, 보통 OS는 파일 inode와 실제 블록 데이터 간의 쓰기 순서를 보장하지 않으므로, 기록한 데이터를 유실하는 것도 가능하지만, inode가 새로운 크기로 업데이트됐는데 이 데이터를 가진 블록을 쓰기 전에 크래시가 나면, 파일에 의미 없는 데이터가 생길 수도 있다. CRC는 이런 코너 케이스를 감지하고 로그가 손상되지 않게 막아준다 (물론, 기록하지 않은 메세지는 유실되긴 하지만).
5.5 Distribution
Consumer Offset Tracking
카프카 컨슈머는 각 파티션에서 컨슘한 최대 오프셋을 추적하고 오프셋을 커밋할 수 있기 때문에, 재시작해도 이 오프셋부터 다시 시작할 수 있다. 카프카에선 주어진 컨슈머 그룹에 대한 모든 오프셋을 그룹 코디네이터라고 부르는, (그 그룹에) 지정된 브로커에 저장할 수 있다. 즉, 컨슈머 그룹에 속한 모든 컨슈머 인스턴스는 이 그룹의 코디네이터(브로커)에게 오프셋 커밋과 페치 요청을 보내야 한다. 컨슈머 그룹은 그룹명을 기반으로 코디네이터에 할당된다. 컨슈머는 아무 카프카 브로커에 FindCoordinatorRequest를 발행하면, 코디네이터 세부 정보를 가진 FindCoordinatorResponse를 읽어 코디네이터를 찾을 수 있다. 그러고나면 컨슈머는 그 코디네이터 브로커에서 오프셋을 커밋하거나 가져올 수 있다. 코디네이터가 다른 브로커로 이동한다면, 컨슈머는 코디네이터를 다시 알아내야 한다. 오프셋 커밋은 컨슈머 인스턴스에서 자동으로도, 수동으로도 수행할 수 있다.
그룹 코디네이터가 OffsetCommitRequest를 받으면, 이 요청을 __consumer_offsets란 특별한 컴팩트 카프카 토픽에 추가한다. 브로커는 이 토픽의 모든 레플리카가 오프셋을 받고난 뒤에만 컨슈머에게 성공적인 오프셋 커밋 응답을 보낸다. 오프셋이 설정한 제한 시간 내에 복제되지 않으면, 오프셋 커밋은 실패하고 컨슈머는 백오프 후 커밋을 재시도할 수 있다. 이 오프셋 토픽은 파티션 당 가장 최신 오프셋만 유지하면 되기 때문에, 브로커는 오프셋 토픽을 주기적으로 압축(compact)한다. 코디네이터는 오프셋 페치에 빠르게 응답하기위해, 인 메모리 테이블에도 오프셋을 캐시해둔다.
코디네이터가 오프셋 페치 요청을 받으면, 단순히 오프셋 캐시를 조회해 마지막으로 커밋한 오프셋 벡터를 반환한다. 코디네이터가 이제 막 기동됐거나, 이제 막 새 컨슈머 그룹 셋의 코디네이터가된 상황에선 (오프셋 토픽 파티션의 리더로 선출됨으로써), 오프셋 토픽 파티션을 캐시에 로드해야 할 수 있다. 이럴때 오프셋 페치는 CoordinatorLoadInProgressException과 함께 실패하며, 컨슈머는 백오프 후 OffsetFetchRequest를 재시도할 수 있다.
ZooKeeper Directories
이어서 컨슈머와 브로커 간의 코디네이션에 사용하는 주키퍼 구조와 알고리즘을 설명한다.
Notation
경로 안에 있는 요소를 [xyz]로 표기하면, xyz 값은 고정 값이 아니라, 가능한 xyz의 값마다 주키퍼 znode가 있음을 의미한다. 예를 들어 /topics/[topic]은 각 토픽명에 해당하는 하위 디렉토리를 가진 /topics라는 디렉토리다. 하위 디렉토리 0, 1, 2, 3, 4를 나타낼 땐 [0...5]같은 숫자 범위도 사용한다. 화살표 ->는 znode의 컨텐츠를 나타낼 때 사용한다. 예를 들어 /hello -> world는 값 “world”를 가진 znode /hello를 나타낸다.
Broker Node Registry
/brokers/ids/[0...N] --> {"jmx_port":...,"timestamp":...,"endpoints":[...],"host":...,"version":...,"port":...} (ephemeral node)
현재 있는 모든 브로커 노드의 리스트로, 각 노드는 컨슈머가 식별할 수 있는 유니크한 논리적 브로커 id를 제공한다 (반드시 설정해야 한다). 기동 시에 브로커 노드는 /brokers/ids 아래 이 논리적인 브로커 id로 znode를 생성해서 자신을 등록한다. 논리적인 브로커 id를 사용하는 목적은, 컨슈머에 영향 없이 브로커를 다른 물리 장비로 이동할 수 있게 하기 위함이다. 이미 사용 중인 브로커 id를 등록하려고 하면 (예를 들어, 두 서버를 동일한 브로커 Id로 설정하면) 오류가 발생한다.
브로커는 자신을 주키퍼에 등록할 땐 임시(ephemeral) znode를 사용하기 때문에, 이 등록은 동적이며, 브로커가 종료되거나 죽으면 사라지는 정보다 (따라서 컨슈머에게 더 이상 사용할 수 없음을 알린다).
Broker Topic Registry
/brokers/topics/[topic]/partitions/[0...N]/state --> {"controller_epoch":...,"leader":...,"version":...,"leader_epoch":...,"isr":[...]} (ephemeral node)
각 브로커는 관리하는 토픽 아래에 자신을 등록하고, 해당 토픽의 대한 파티션 수를 저장한다.
Cluster Id
클러스터 id는 카프카 클러스터에 할당된 변경할 수 없는 고유 식별자다. 클러스터 id는 최대 22자까지 가능하며, 허용 문자는 정규식 [a-zA-Z0-9_-]+로 정의된다. 허용 문자는 URL에 사용해도 안전한, 패딩이 없는 Base64에서 쓰는 문자와 동일하다. 개념적으로 보면 이 값은 클러스터가 처음 시작할 때 자동으로 생성된다.
구현 측면에선, 0.10.1 버전 이상 브로커가 처음 성공적으로 시작했을 때 생성된다. 브로커는 기동 중에 /cluster/id znode에서 클러스터 id를 가져온다. znode가 없으면 브로커는 새 클러스터 id를 만들어 이 값으로 znode를 만든다.
Broker node registration
브로커 노드는 기본적으로 독립적이기 때문에, 자신이 보유한 정보만 게시한다. 브로커가 조인할 땐, 브로커 노드 레지스트리 디렉토리에 자신을 등록하고, 자신의 호스트명과 포트 정보를 기록한다. 이와 더불어 가지고있는 토픽 목록과 논리적인 파티션을 브로커 토픽 레지스트리에 등록한다. 새 토픽은 브로커에서 만들어질 때 동적으로 등록된다.
Next : Operations
Operations
카프카 운영에 필요한 커맨드라인 명령어와, 주요 카프카 설정, 자바, OS, 파일시스템 튜닝, 주키퍼 정책
전체 목차는 여기에 있습니다.