스프링 배치 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
목차
- 4.1. Configuring a Job
- 4.2. Java Config
- 4.3. Configuring a JobRepository
- 4.4. Configuring a JobLauncher
- 4.5. Running a Job
- 4.6. Advanced Meta-Data Usage
domain 섹션에서 아래 다이어그램을 사용해서 전반적인 아키텍처 설계를 다뤘다:
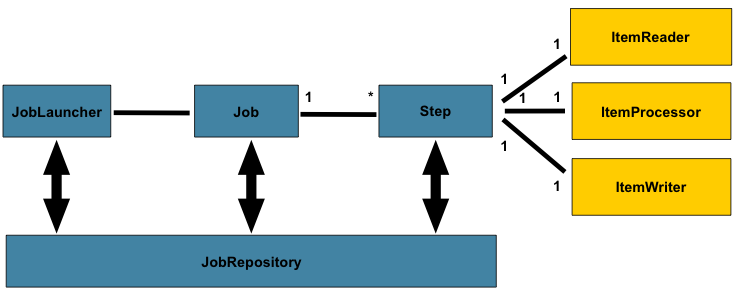
Job 오브젝트가 단순한 step의 컨테이너처럼 보이긴 하지만, 반드시 알아둬야 할 여러 가지 설정 옵션이 있다.
Job을 실행하고 실행 중 메타 데이터를 저장하기 위해서는 여러 가지를 고려해야 한다.
여기서는 다양한 설정 옵션과 Job을 실행할 때 고려해야 하는 사항을 다룬다.
4.1. Configuring a Job
Job 인터페이스 구현체는 다양하고 설정 방법도 다른데, builder로 이를 추상화한다.
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}
Job(보통 Step을 안에 가지고 있음)은 JobRepository가 필요하다.
BatchConfigurer를 통해 JobRepository를 설정한다.
위에 보이는 예시에서 Job은 세 개의 Step을 가지고 있다.
job 빌더로 step뿐 아니라 병렬화(Split), 선언적인 flow 제어(Decision),
flow 정의 외부화(Flow) 같은 다른 요소도 설정할 수 있다.
4.1.1. Restartability
배치 job을 실행할 때 발생하는 주요 이슈는 Job이 재시작할 때의 동작과 관련 있다.
job을 실행할 때 특정 JobInstance의 JobExecution이 이미 존재한다면, ‘재시작’으로 간주한다.
모든 잡이 중단된 지점부터 재시작할 수 있다면 이상적이겠지만, 불가능할 때가 있다.
이런 경우에는 개발자가 직접 새 JobInstance를 생성해야 한다.
물론 스프링 배치를 사용하면 문제가 조금 쉬워지는데,
restartable 프로퍼티 값을 ‘false’로 설정하면 절대 Job을 재실행하지 않고 항상 새 JobInstance로 실행한다:
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.preventRestart()
...
.build();
}
restartable이 false라는 건 “이 Job은 재시작을 지원하지 않는다”는 말이다.
재시작을 지원하지 않는 Job을 재시작하려고 하면 JobRestartException이 발생한다.
Job job = new SimpleJob();
job.setRestartable(false);
JobParameters jobParameters = new JobParameters();
JobExecution firstExecution = jobRepository.createJobExecution(job, jobParameters);
jobRepository.saveOrUpdate(firstExecution);
try {
jobRepository.createJobExecution(job, jobParameters);
fail();
}
catch (JobRestartException e) {
// expected
}
위 코드에서 보여주는 바와 같이 재시작 불가능한 job으로 JobExecution을 처음으로 생성할 때는 문제없이 잘 생성된다.
그러나 두 번째 시도부터 JobRestartException이 발생한다.
4.1.2. Intercepting Job Execution
Job이 실행 중일 때 이 job의 라이프사이클 동안 발생한 이벤트를 통지받아 원하는 코드를 실행할 수도 있다.
SimpleJob은 적절한 타이밍에 JobListener를 호출하므로 이벤트를 통지받을 수 있다.
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
job의 listener 메소드를 통해 SimpleJob에 JobListener를 등록한다.
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.listener(sampleListener())
...
.build();
}
afterJob 메소드는 job의 성공 여부와 상관없이 호출된다는 점에 주의해라.
성공/실패 여부는 JobExecution을 통해 알 수 있다.
public void afterJob(JobExecution jobExecution){
if( jobExecution.getStatus() == BatchStatus.COMPLETED ){
//job success
}
else if(jobExecution.getStatus() == BatchStatus.FAILED){
//job failure
}
}
인터페이스와 동일한 어노테이션도 지원한다:
@BeforeJob@AfterJob
4.1.4. JobParametersValidator
XML 네임 스페이스에서 선언되었거나 AbstractJob의 서브 클래스를 사용한 job은 원한다면 런타임에 사용할 job 파라미터 validator를 지정할 수 있다.
job 실행에 꼭 필요한 파라미터를 검증하는 용도로 유용하다.
간단한 필수/옵션 파라미터를 검증하는 데 사용할 수 있는 DefaultJobParametersValidator를 지원하며, 좀 더 복잡한 제약 조건이 있다면 인터페이스를 직접 구현할 수도 있다.
자바 빌더를 통해 validator를 설정한다:
@Bean
public Job job1() {
return this.jobBuilderFactory.get("job1")
.validator(parametersValidator())
...
.build();
}
4.2. Java Config
Spring 3부터 XML뿐 아니라 자바 코드로도 어플리케이션을 설정할 수 있는데,
이와 동일하게 스프링 배치 2.2.0부터 자바 코드로 배치 job을 설정할 수 있다.
자바 기반 설정을 위한 두 가지 컴포넌트를 지원한다:
@EnableBatchProcessing 어노테이션과 두 개의 빌더
@EnableBatchProcessing는 자바 진영의 다른 @Enable* 어노테이션과 유사하게 동작한다.
여기선 @EnableBatchProcessing이 배치 job 생성을 위한 기반 설정이라고 할 수 있다.
이 기반 설정 내에서 주입받은 여러 빈과 함께 StepScope 인스턴스를 생성한다:
JobRepository- bean name “jobRepository”JobLauncher- bean name “jobLauncher”JobRegistry- bean name “jobRegistry”PlatformTransactionManager- bean name “transactionManager”JobBuilderFactory- bean name “jobBuilders”StepBuilderFactory- bean name “stepBuilders”
이 설정을 위한 핵심 인터페이스는 BatchConfigurer이다.
디폴트 구현체는 위에서 언급된 빈을 제공하며 컨텍스트에 DataSource 빈을 설정해줘야 한다.
데이터 소스는 JobRepository에서 사용한다.
BatchConfigurer 인터페이스를 구현하면 직접 이 빈들을 커스터마이징할 수도 있다.
늘 그렇듯, DefaultBatchConfigurer(BatchConfigurer가 없으면 제공되는)를 확장하고
필요한 getter를 오버라이딩하는 것만으로 충분하다.
그러나 처음부터 직접 구현해야 할 수도 있다.
아래 예시는 커스텀 트랜잭션 매니저를 사용하는 방법을 설명한다:
@Bean
public BatchConfigurer batchConfigurer() {
return new DefaultBatchConfigurer() {
@Override
public PlatformTransactionManager getTransactionManager() {
return new MyTransactionManager();
}
};
}
설정 클래스에 필요한 건
@EnableBatchProcessing어노테이션 하나다. 이 어노테이션을 선언한 클래스만 있으면 위에 있는 모든 기능을 사용할 수 있다.
이 기반 설정만 해주면 기본으로 제공하는 빌더 팩토리로 job을 만들 수 있다.
아래 예제에서는 JobBuilderFactory와 StepBuilderFactory로 두 개의 step을 가지고 있는 job을 구성한다.
@Configuration
@EnableBatchProcessing
@Import(DataSourceConfiguration.class)
public class AppConfig {
@Autowired
private JobBuilderFactory jobs;
@Autowired
private StepBuilderFactory steps;
@Bean
public Job job(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2) {
return jobs.get("myJob").start(step1).next(step2).build();
}
@Bean
protected Step step1(ItemReader<Person> reader,
ItemProcessor<Person, Person> processor,
ItemWriter<Person> writer) {
return steps.get("step1")
.<Person, Person> chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
protected Step step2(Tasklet tasklet) {
return steps.get("step2")
.tasklet(tasklet)
.build();
}
}
4.3. Configuring a JobRepository
@EnableBatchProcessing을 이용하면 JobRepository를 바로 사용할 수 있다.
이번 섹션에선 repository를 원하는대로 설정하는 방법을 설명한다.
위에서 설명한대로, JobRepository는 영구 저장하는 JobExecution이나 StepExecution 같이
스프링 배치에서 사용하는 여러 도메인 객체를 CRUD할 때 필요하다.
도메인 객체 CRUD는 JobLauncher, Job, Step 같은 주요 프레임워크 기능에서 필요하다.
자바 기반 설정을 사용한다면 JobRepository가 제공될 거다.
DataSource를 제공했다면 JDBC 기반 repository를,
그 외는 Map 기반 repository를 제공한다.
물론 BatchConfigurer 인터페이스를 구현해서 JobRepository 설정을 커스터마이징할 수도 있다.
...
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setIsolationLevelForCreate("ISOLATION_SERIALIZABLE");
factory.setTablePrefix("BATCH_");
factory.setMaxVarCharLength(1000);
return factory.getObject();
}
...
위에 있는 옵션 중 필수값은 dataSource와 transactionManager 두 개뿐이다. 나머지 값들은 따로 설정하지 않으면 위에 보이는 디폴트 값이 사용되는데, 위에는 참고용으로 표기해 두었다. max varchar length는 디폴트값이 2500인데, 샘플 스키마 스크립트에서 사용한 long VARCHAR 컬럼의 길이와 동일하다.
4.3.1. Transaction Configuration for the JobRepository
네임스페이스나 기본으로 제공하는 FactoryBean을 사용한다면
레포지토리를 위한 트랜잭션 advice가 자동으로 생성된다.
이는 실패 후 재시작할 때 꼭 필요한 state를 포함한 배치 메타 데이터가 올바르게 저장됨을 보장해준다.
레포지토리 메소드에 트랜잭션 처리가 없다면 이를 보장할 수 없다.
두 프로세스가 동시에 같은 job을 실행하려고 하면 하나만 성공해야 하므로 create* 메소드의 isolation 레벨은 별도로 지정한다.
메소드의 디폴트 isloation 레벨은 SERIALIZABLE로, 극단적이라고 느껴질 수도 있다:
READ_COMMITTED도 잘 동작한다;
두 프로세스가 충돌하는 경우만 아니면 READ_UNCOMMITTED도 괜찮다.
하지만 create* 메소드 호출이 매우 짧기 때문에 SERIALIZED가 딱히 문제 되지는 않는다 (데이터베이스 플랫폼이 이를 지원한다면).
물론 원한다면 오버라이드할 수 있다:
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setIsolationLevelForCreate("ISOLATION_REPEATABLE_READ");
return factory.getObject();
}
네임스페이스나 팩토리 빈을 사용하지 않는다면 AOP를 사용해서 트랜잭션을 제어하는 게 좋다:
@Bean
public TransactionProxyFactoryBean baseProxy() {
TransactionProxyFactoryBean transactionProxyFactoryBean = new TransactionProxyFactoryBean();
Properties transactionAttributes = new Properties();
transactionAttributes.setProperty("*", "PROPAGATION_REQUIRED");
transactionProxyFactoryBean.setTransactionAttributes(transactionAttributes);
transactionProxyFactoryBean.setTarget(jobRepository());
transactionProxyFactoryBean.setTransactionManager(transactionManager());
return transactionProxyFactoryBean;
}
4.3.2. Changing the Table Prefix
메타 데이터 테이블의 프리픽스도 JobRepository의 속성을 통해 바꿀 수 있다.
기본적으로는 BATCH_라는 프리픽스를 사용한다. 예를 들어 BATCH_JOB_EXECUTION, BATCH_STEP_EXECUTION.
프리픽스를 바꾸고 싶은 경우도 있을 수 있는데,
스키마 이름을 테이블 이름 앞에 붙여야 하거나 같은 스키마로 여러 메타 데이터 테이블을 만들어야 하는 경우가 그렇다.
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setTablePrefix("SYSTEM.TEST_");
return factory.getObject();
}
위 예제대로 설정하면 모든 쿼리는 메타 테이블에 “SYSTEM.TEST_“라는 프리픽스를 붙인다. BATCH_JOB_EXECUTION는 SYSTEM.TEST_JOB_EXECUTION으로 바뀐다.
이 설정은 테이블 프리픽스만을 변경한다. 테이블 명이나 컬럼 명은 해당하지 않는다.
4.3.3. In-Memory Repository
성능 등의 이유로 도메인 오브젝트를 굳이 데이터베이스에 저장하고 싶지 않을 수도 있다. 매 커밋 때마다 도메인 오브젝트를 저장하는 건 별도의 시간이 소요되는 작업이다. 아니면 단순히 상태를 저장할 필요가 없는 job이거나. 위와 같은 이유로 스프링 배치는 인메모리 Map 버전의 job 레포지토리를 제공한다:
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
MapJobRepositoryFactoryBean factory = new MapJobRepositoryFactoryBean();
factory.setTransactionManager(transactionManager);
return factory.getObject();
}
인메모리 레포지토리는 휘발성이어서 JVM을 새로 띄우는 식의 재실행은 불가능하다.
같은 파라미터로 두 개의 job 인스턴스를 동시에 실행시킬 수 없으며,
멀티 쓰레드 job이나 프로그램 내에서 파티셔닝한 Step에는 적합하지 않다.
따라서 이런 기능이 필요하다면 인메모리가 아닌 데이터베이스 버전의 레포지토리를 사용해야 한다.
인메모리 레포지토리도 트랜잭션 매니저를 등록해야 한다.
레포지토리에 롤백 시멘틱이 존재하고, 여전히 비지니스 로직에 트랜잭션이 필요하기 때문이다 (e.g. RDBMS 접근).
테스트가 목적이라면 ResourcelessTransactionManager가 유용할 것이다.
4.3.4. Non-standard Database Types in a Repository
사용하려는 데이터베이스 플랫폼이 지원되지 않는다면
SQL이 크게 다르지 않은 경우에 한해 지원되는 타입 중 하나를 골라 사용하는 방법도 있다.
손쉬운 네임스페이스 대신 로(raw) 레벨의 JobRepositoryFactoryBean을 사용해서 가장 유사한 database를 설정하면 된다.
// This would reside in your BatchConfigurer implementation
@Override
protected JobRepository createJobRepository() throws Exception {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setDatabaseType("db2");
factory.setTransactionManager(transactionManager);
return factory.getObject();
}
(데이터베이스 타입을 지정하지 않으면 JobRepositoryFactoryBean은
DataSource로부터 자동으로 타입을 알아낸다.)
플랫폼마다 주로 primary key를 증가시키는 전략이 다르기 때문에,
필요하다면 incrementerFactory를 오버라이드해야 한다
(스프링 프레임워크의 표준 인터페이스 중 하나를 사용해서).
그래도 동작하지 않거나 RDBMS를 사용하지 않는다면 가능한 유일한 옵션은
SimpleJobRepository가 의존하는 여러 Dao 인터페이스를 구현해서 스프링 방식대로 수동으로 연결하는 방법뿐이다.
4.4. Configuring a JobLauncher
@EnableBatchProcessing를 사용하면 JobRegistry가 제공된다.
여기서는 직접 설정하는 방법을 설명한다.
JobLauncher 인터페이스의 가장 기본적인 구현체는 SimpleJobLauncher다.
JobRepository 의존성만 있으면 실행할 수 있다:
...
// This would reside in your BatchConfigurer implementation
@Override
protected JobLauncher createJobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
...
생성된 JobExecution은 job의 execute 메소드를 실행할 때 넘겨주고,
마지막에 caller에게 이 JobExecution을 리턴한다.
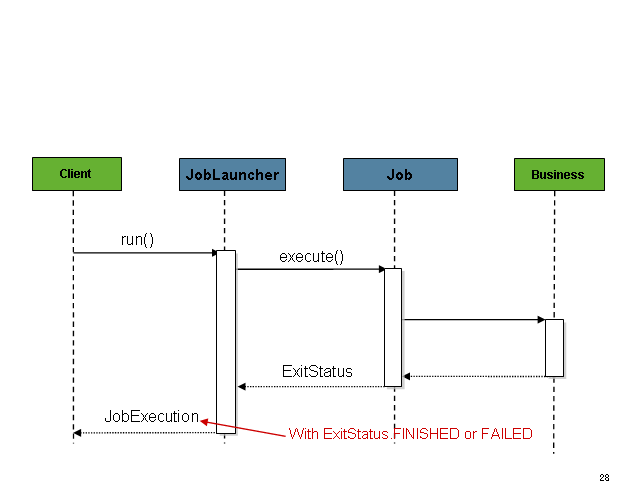
스케줄러가 job을 기동하면 순서대로 잘 동작한다.
문제는 HTTP 요청으로 job을 시작할 때 생긴다.
이때는 요청을 비동기로 처리해서 SimpleJobLauncher가 요청 즉시
caller에게 결과를 리턴해줘야 한다.
배치 같은 긴 시간이 소요되는 작업 동안 HTTP 요청을 열린 채로 두는 것은
좋은 방법이 아니기 때문이다. 다음은 작동 순서 예시이다:
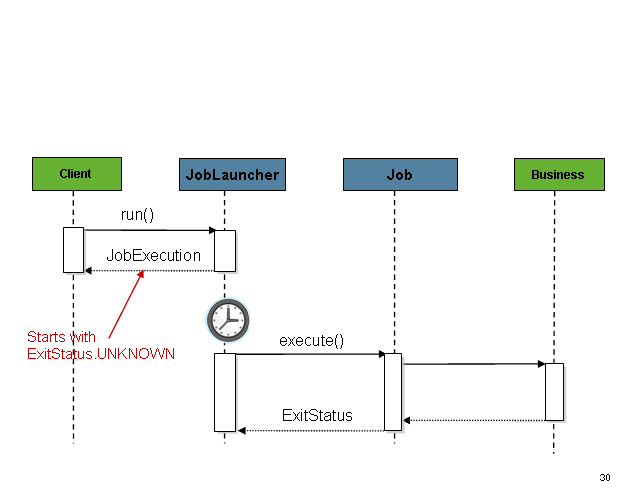
이런 경우 SimpleJobLauncher에 TaskExecutor를 설정하면 된다:
@Bean
public JobLauncher jobLauncher() {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository());
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor());
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
스프링 TaskExecutor의 모든 구현체는 job을 비동기로 처리할 수 있다.
4.5. Running a Job
배치 job을 실행하려면 실행할 Job과 JobLauncher 두 가지가 필요하다.
두 가지 모두 같은 컨텍스트를 사용할 수도 있고 각기 다른 컨텍스트를 사용할 수 있다.
예를 들어 커맨드라인에서 job을 실행시킬 때는 각 job마다 JVM이 따로 초기화될 거고,
그러면 각 job은 다른 JobLauncher에서 실행된다.
반대로 웹 컨테이너에서 HttpRequest로 job을 실행한다면 일반적으로 여러 요청을 비동기로 실행하기 위해 JobLauncher를 하나만 사용한다.
4.5.1. Running Jobs from the Command Line
엔터프라이즈 스케줄러로 job을 실행한다면 커맨드라인이 기본 인터페이스다. NativeJob을 사용하지 않는다면 Qartz를 제외한 스케줄러 대부분은 주로 쉘 스크립트로 실행돼서 운영체제 프로세스와 직접 작동하기 때문이다. Perl, Ruby같은 쉘 스크립트나 ant, maven같은 ‘빌드 도구’가 아니어도 Java 프로세스를 시작하는 방법은 많다. 그러나 예제에서는 대부분이 익숙하다고 느낄 쉘 스크립트를 사용한다.
The CommandLineJobRunner
스크립트로 job을 실행하면 자바 가상 머신을 실행하기 때문에 진입점으로 메인 메소드를 가진 클래스가 필요하다.
스프링 배치는 이를 위해 CommandLineJobRunner라는 구현체를 만들어놨다.
단, 이는 어플리케이션을 실행하는 방법 중 하나일 뿐이고, 자바 프로세스를 시작할 방법은 많으며 이 클래스가 절대적인 것은 아니다.
CommandLineJobRunner는 네 가지 작업을 수행한다:
- 적절한
ApplicationContext로딩 - 커맨드라인에서 받은 인자를
JobParameters로 변환 - 인자에 따른 적절한 job 선택
- 어플리케이션 컨텍스트에 있는
JobLauncher로 job 실행
이 모든 건 인자(argument)만 넘겨받을 수 있으면 가능하다. 필수 인자는 다음과 같다:
| jobPath | ApplicationContext를 생성할 때 필요한 XML 파일 위치. 이 파일은 Job 실행에 필요한 모든 것을 포함한다. |
| jobName | 실행할 job의 이름 |
이 인자들은 path, name 순으로 전달해야 한다.
이 두 인자 다음에 나오는 모든 인자는 JobParameter로 간주하며 ‘name=value’ 포맷으로 사용해야 한다.
<bash$ java CommandLineJobRunner io.spring.EndOfDayJobConfiguration endOfDay schedule.date(date)=2007/05/05
대부분 manifest를 jar 파일 안의 메인 클래스에 선언하고 싶겠지만, 단순화를 위해 클래스를 직접 사용한다. 이 예시에서도 domainLanguageOfBatch에서 사용한 ‘EndOfDay’ 예제를 그대로 사용한다. 첫 번째 인자받은 ‘io.spring.EndOfDayJobConfiguration’는 Job을 포함한 설정 클래스의 풀네임이다. 두 번째 인자 ‘endOfDay’는 job의 이름이다. 마지막으로 넘긴 인자 ‘schedule.date(date)=2007/05/05’는 JobParameter로 변환된다. 다음은 자바 설정 예제이다:
@Configuration
@EnableBatchProcessing
public class EndOfDayJobConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job endOfDay() {
return this.jobBuilderFactory.get("endOfDay")
.start(step1())
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet((contribution, chunkContext) -> null)
.build();
}
}
스프링 배치에서 배치 job을 실행하려면 더 복잡한 설정들이 있는데,
이 예제에서는 CommandLineJobRunner에서 필요로 하는
Job과 JobLauncher만 다뤘다.
ExitCodes
커맨드라인으로 배치를 실행할 땐 보통 엔터프라이즈 스케줄러를 사용한다.
대부분 스케줄러는 그렇게 똑똑하진 않은데, 프로세스 수준에서만 작동한다.
이 말은 직접 호출할 수 있는 쉘 스크립트 등의 운영체제 프로세스만 다룬다는 뜻이다.
따라서 스케줄러를 사용하면 리턴 코드로 잡의 성공/실패 여부를 판단해야 한다.
리턴 코드는 프로세스가 스케줄러에게 리턴하는 숫자로 실행 결과를 나타낸다.
가장 간단하게는 0은 성공이고 1은 실패를 의미한다.
그러나 더 복잡한 케이스도 있는데, job A가 4를 리턴하고 job B를 시작했으며, job B는 5를 리턴하고 job C를 시작한 경우를 생각해 보자.
이런 동작은 스케줄러 레벨에서 처리되지만, 스프링 배치 같은 프레임워크를 다룰 때는 특정 job의 ‘Exit Code’를 의미하는 숫자를 리턴할 방법이 필요하다.
스프링 배치에선 이를 ExitStatus로 캡슐화해서 지원하는데, 5장에서 상세하게 다룬다.
여기서 기억해둬야 할 점은 ExitStatus는 프레임워크에서 설정하는(혹은 개발자가 직접) exit code라는 프로퍼티가 있으며,
JobLauncher가 리턴하는 JobExecution에서 확인할 수 있다는 점이다.
CommandLineJobRunner가 ExitCodeMapper 인터페이스를 사용해 string 값을 number로 바꿔 준다:
public interface ExitCodeMapper {
public int intValue(String exitCode);
}
string으로 된 종료 코드를 받아서 숫자로 리턴하는 게 ExitCodeMapper의 핵심이다.
job runner가 디폴트로 사용하는 구현체는 SimpleJvmExitCodeMapper로,
성공 시에는 0을, 일반적인 에러라면 1을, 컨텍스트 내에서 Job을 못 찾는 등의 job runner 에러는 2를 리턴한다.
좀 더 세세한 구분이 필요하면 ExitCodeMapper 인터페이스를 직접 구현해야 한다.
CommandLineJobRunner는 ApplicationContext를 생성하는 클래스이므로 context 내에 함께 묶일 수는 없고, 재구현한 값들을 주입해줄 필요가 있다.
즉 BeanFactory 내에 ExitCodeMapper 구현체가 있으면 컨텍스트가 생성되고 난 이후에 runner에 주입된다는 뜻이다.
직접 구현한 ExitCodeMapper를 사용하려면 루트 레벨에 구현체를 선언하고 runner에 의해 로드되는 ApplicationContext에 포함시켜야 한다.
4.5.2. Running Jobs from within a Web Container
위에서 설명한 바와 같이 보통 배치 job 같은 오프라인 처리는 커맨드라인에서 실행해왔다.
그러나 리포팅 용도나, 애드혹(ad-hoc) job을 실행할 때,
웹 어플리케이션을 지원해야 할 때 등 HttpRequest로 실행하는 게 더 나을 때도 있다.
배치 job은 보통 긴 작업을 의미하므로 job은 비동기로 실행해야 한다.
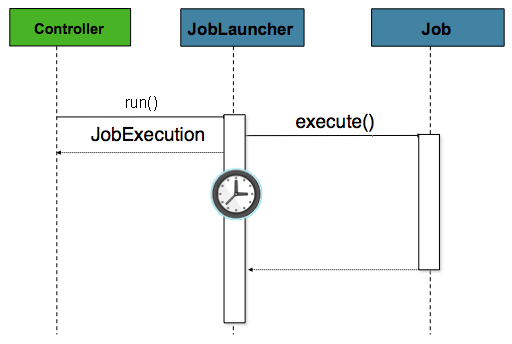
여기 나오는 컨트롤러는 스프링 MVC 컨트롤러를 의미한다.
스프링 MVC에 관한 상세 내용은 여기를 참고하라.
컨트롤러가 Job을 실행시키는데, 이때 요청 즉시 JobExecution을 리턴하게 설정한(비동기) JobLauncher를 사용한다.
Job은 여전히 실행 중인데도 논블로킹 처리로 컨트롤러는 즉시 응답할 수 있으며, HttpRequest를 사용한다면 이것은 필수이다.
예제는 아래 있다:
@Controller
public class JobLauncherController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@RequestMapping("/jobLauncher.html")
public void handle() throws Exception{
jobLauncher.run(job, new JobParameters());
}
}
4.6. Advanced Meta-Data Usage
지금까지 JobLauncher와 JobRepository 인터페이스에 대해 설명했다.
이 둘은 간단한 job 실행과 배치 도메인 오브젝트에 대한 기본 CRUD를 제공한다.
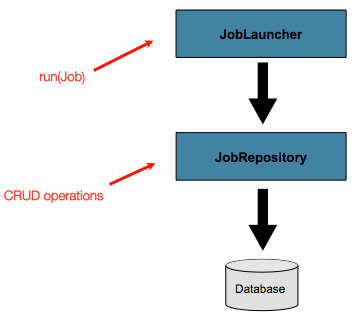
JobLauncher는 JobExecution 오브젝트를 생성하고 실행하기 위해 JobRepository를 사용한다.
그다음으론 Job과 Step 구현체가 job 실행 중에 execution을 업데이트하기 위해 JobRepository를 사용한다.
이 기본적인 동작은 간단한 시나리오에는 충분하지만 배치 job이 수백 개에 달하고 스케줄링까지 복잡하다면 메타 데이터에 접근하기 위한 고급 기술이 필요하다.
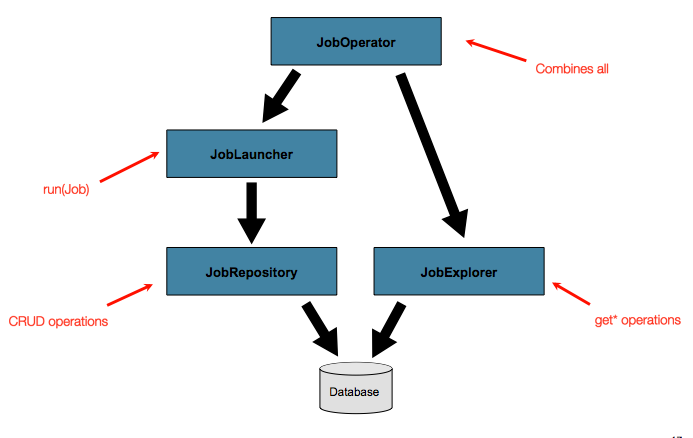
밑에서 설명할 JobExplorer와 JobOperator 인터페이스는 메타 데이터를 질의하고 관리하기 위한 추가적인 기능을 제공한다.
4.6.1. Querying the Repository
어떤 고급 기능보다도 가장 기본적인 요구사항은 레포지토리에 기존 execution을 요청하는 기능이다.
이 기능은 JobExplorer 인터페이스가 지원한다:
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}
위의 메소드에서 알 수 있듯이, JobExplorer는 JobRepository의 리드온리 버전이며,
JobRepository와 동일하게 팩토리 빈을 통해 손쉽게 설정할 수 있다:
...
// This would reside in your BatchConfigurer implementation
@Override
public JobExplorer getJobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
...
이 챕터 앞부분에서, JobRepository의 테이블 프리픽스를 수정하면 버전과 스키마별로 테이블을 따로 관리할 수 있다고 언급했었다.
JobExplorer도 같은 테이블에서 동작하므로 당연히 프리픽스를 변경할 수 있다:
...
// This would reside in your BatchConfigurer implementation
@Override
public JobExplorer getJobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
...
4.6.2. JobRegistry
JobRegistry는(부모 인터페이스 JobLocator도 마찬가지) 필수는 아니지만,
컨텍스트 내에 있는 job을 추적하고 싶을 때 유용하다.
여러 곳에서 job을 생성하는 환경이라면(e.g. 자식 컨텍스트) 어플리케이션 컨텍스트에서 job을 수집할 때도 사용할 수 있다.
커스텀 JobRegistry 구현체 또한 등록된 job의 이름이나 프로퍼티를 관리할 때 유용할 수 있다.
기본으로 제공하는 구현체는 job 이름을 job 인스턴스에 매핑한 간단한 map 기반이다.
@EnableBatchProcessing을 선언하면 JobRegistry를 기본으로 제공한다.
자체 구현체를 사용하고 싶다면:
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the getter in the SimpleBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
...
빈 post processer나 register lifecycle 컴포넌트를 사용해서 JobRegistry를 등록할 수 있는데,
이 두 가지 메커니즘은 아래 섹션에서 설명한다.
JobRegistryBeanPostProcessor
빈 post-processor는 생성된 모든 job을 등록할 수 있다:
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor() {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry());
return postProcessor;
}
위 예제에서는 자식 컨텍스트가 post-processor를 포함할 수 있도록 (e.g 상위 빈을 정의함으로써) 빈 id를 만들었지만, 필수는 아니다.
AutomaticJobRegistrar
AutomaticJobRegistrar는
자식 컨텍스트를 생성하고 각 job을 하위 컨텍스트에 등록하는 라이프사이클 컴포넌트다.
이렇게 하면 자식 컨텍스트에 있는 job 이름은 registry 전역에서 유일해야지만,
job이 의존성을 갖는 빈(bean) 이름은 그럴 필요가 없어진다.
예를 들어, Job을 하나씩 가진 여러 XML 설정 파일에
빈 이름이 같은(e.g. “reader”) ItemReader가 여러 개 있어도 상관없다.
모든 파일이 같은 컨텍스트에 임포트된다면 reader는 충돌해서 서로를 덮어쓰게 되지만
이 자동 registrar가 이를 방지해 준다.
여러 모듈로 구성된 어플리케이션의 job을 통합하기도 쉬워진다.
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
}
registrar 필수 프로퍼티는 ApplicationContextFactory 배열과(여기선 편의상 팩토리 빈으로 생성했다) JobLoader 두 개다.
JobLoader가 자식 컨텍스트와 JobRegistry에 등록된 job의 라이프사이클을 관리한다.
ApplicationContextFactory가 자식 컨텍스트 생성을 담당하며, 보통 위에서처럼 ClassPathXmlApplicationContextFactory를 사용한다.
이 팩토리는 기본적으로 부모 컨텍스트의 일부 설정을 자식 컨텍스트로 복사한다.
따라서 부모 컨텍스트와 동일한 설정을 사용한다면 자식 컨텍스트에서 PropertyPlaceholderConfigurer나 AOP 설정을 재정의하지 않아도 된다.
원한다면 AutomaticJobRegistrar를 JobRegistryBeanPostProcessor와 함께 사용할 수 있다 (DefaultJobLoader도 함께 사용하는 경우에만).
메인 부모 컨텍스트와 자식 컨텍스트에 모두 job을 정의한 경우에 유용하다.
4.6.3. JobOperator
앞서 말한 바와 같이 JobRepository는 메타 데이터에 대한 CRUD 오퍼레이션을, JobExplorer는 리드온리 오퍼레이션을 제공한다.
그런데 이 두 오퍼레이션을 함께 사용하면 배치에서 흔히 쓰는 중단, 재시작, job 요약 등의 모니터링이 가능해진다.
스프링 배치는 JobOperator 인터페이스를 통해 이를 지원한다:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}
위 오퍼레이션엔 JobLauncher, JobRepository, JobExplorer, JobRegistry 같은 인터페이스를 사용하는 메소드가 많다.
즉, JobOperator를 구현한 SimpleJobOperator는 의존성(dependency)이 높다.
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
}
job repository에 테이블 프리픽스를 설정했다면 job exploerer에도 지정해야 한다는 걸 잊지 말자.
4.6.4. JobParametersIncrementer
JobOperator의 메소드는 대부분 설명이 필요 없으며, 자세한 설명은 javadoc에 있다.
하지만 startNextInstance 메소드는 주의 깊게 살펴볼 필요가 있다.
이 메소드는 항상 새 job 인스턴스를 실행시킨다.
JobExecution에서 심각한 이슈가 발생해서 job을 처음부터 다시 시작해야 하는 경우 매우 유용하다.
JobLauncher는 이전 파라미터 셋과는 다른 값으로 새 JobInstance를 실행시키려면 새로운 JobParameters 오브젝트가 필요한 반면에,
startNextInstance 메소드는 Job에 상응하는 JobParametersIncrementer를 통해 새 인스턴스를 만들도록 강제한다.
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}
JobParametersIncrementer는 가지고 있는 JobParameters에서 필요한 값을 증가시켜 다음에 사용될 JobParameters 오브젝트를 리턴한다.
프레임워크에서는 JobParameters의 어떤 값을 바꿔야 ‘다음’ 인스턴스라고 할 수 있는지 알 수 없기 때문에 꽤 유용하다.
예를 들어 JobParameters에 날짜 값만 있고, 다음 인스턴스를 생성해야 한다면 날짜는 하루를 증가시켜야 할까? 아니면 한 주(위클리 job이라면)?
아래 보이는 것처럼 Job을 식별하는 데 사용할 수 있는 어떤 숫자든지 마찬가지다:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}
이 예제에서는 ‘run.id’라는 키를 가진 값으로 JobInstances를 구분한다. 넘겨받은 JobParameters가 null이라면 전엔 이 Job을 실행한 적이 없다는 뜻이므로 초기 상태를 리턴하면 된다. 반대로 null이 아니라면, 이전에 사용했던 값을 가져와서 1을 더해 반환한다.
incrementer는 빌더에서 제공하는 incrementer 메소드로 설정한다.
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.incrementer(sampleIncrementer())
...
.build();
}
4.6.5. Stopping a Job
job을 정상적으로(gracefully) 종료하는 데에도 JobOperator를 많이 사용한다.
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());
바로 종료시키지는 않는다. 강제로 즉시 종료시키는 건 불가능하다.
특히, 현재 실행 중인 execution이 개발자가 작성한 비지니스 로직을 담당하는 코드라면 프레임워크에서 컨트롤할 방법이 없다.
그러나 프레임워크가 다시 제어할 수 있게 되면 종료하기 전 즉시 현재 StepExecution의 상태를 BatchStatus.STOPPED로 바꾸고
저장한 다음 JobExecution에도 동일한 처리를 한다.
4.6.6. Aborting a Job
실패한 job은 재실행할 수 있는데 (Job이 restartable로 설정된 경우에 한해서),
ABANDONED 상태인 job은 프레임워크에 의해 재실행되지 않는다.
job을 재실행할 때 특정 step을 스킵하고 싶을 때도 ABANDONED를 사용한다:
이전에 실패한 job이 실행 중일 때 ABANDONED로 마킹된 step을 만나면 다음 step으로 넘어간다
(job flow 정의와 step execution의 종료 코드에 따라 달라진다).
프로세스가 죽으면 (“Kill -9” 명령어를 사용했거나 서버가 다운된 경우) 당연히 job은 실행 중이 아님에도
JobRepository는 프로세스가 죽었다는 통지를 받을 수가 없기 때문에 이를 알아채지 못한다.
execution이 실패하거나 중단되었다고 판단되면 이를 수동으로 알려줘야 하는데 (상태를 FAILED나 ABANDONED로 바꿔야 한다),
이는 비지니스 요구사항이기 때문에 자동화할 수는 없다.
재시작할 수 없는 job이거나(restartable=false) 데이터가 유효하다는 걸 확신할 수 있을 때만 status를 FAILED로 바꿔라.
job을 중단시키는 유틸리티는 스프링 배치 어드민 JobService에 있다.
Next : Configuring a Step
Configuring a Step
스프링 배치 step 설정하기 한글 번역
전체 목차는 여기에 있습니다.