스프링 배치 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
목차
- 5.1. Chunk-oriented Processing
- 5.2. TaskletStep
- 5.3. Controlling Step Flow
- 5.4. Late Binding of Job and Step Attributes
domain 챕터에서 이야기한 대로,
Step은 batch job의 독립적으로 실행되는 순차적인 단계를 캡슐화한 도메인 객체이며,
실제 배치 처리를 정의하고 컨트롤하는 데 필요한 모든 정보를 가지고 있다.
설명이 모호하게 느껴질 수도 있는데, Step의 모든 내용은 Job을 만드는 개발자 재량이기 때문에 그렇다.
Step은 어떻게 개발하느냐에 따라 간단할 수도 있고 복잡할 수도 있다.
아래 그림에서 표현하는 Step은 단순히 데이터베이스에서 파일을 읽는,
코드가 거의 필요 없거나 전혀 필요하지 않은(사용한 구현체에 따라 다름)
간단한 작업이 될 수도 있고,
프로세싱 일부를 처리하는 복잡한 비지니스 로직일 수도 있다.
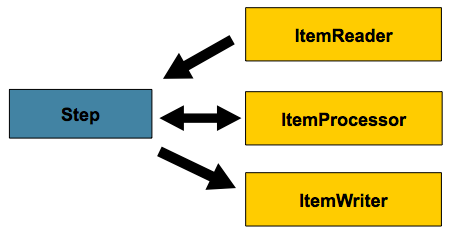
5.1. Chunk-oriented Processing
스프링 배치 구현체의 대부분은 ‘청크 지향’으로 개발되었다.
청크 지향 프로세싱이란 한 번에 데이터를 하나씩 읽어와서 트랜잭션 경계 내에서 쓰여질 ‘청크’를 만드는 것이다.
ItemReader가 item 하나를 읽으면 데이터는 ItemProcessor에 넘겨지고 결국엔 합쳐진다.
읽어온 item 수가 commit interval과 같아지면 ItemWriter가 청크 전체를 write하고, 트랜잭션이 커밋된다.
다음은 이 절차를 도식화한 그림이다:
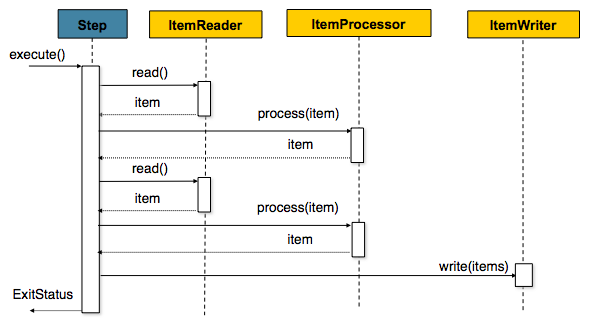
같은 개념을 코드로 나타내면 다음과 같다:
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);
5.1.1. Configuring a Step
Step은 필수 의존성(dependency)이 상대적으로 적은 편이지만,
많은 collaborator를 포함할 수 있는 매우 복잡한 클래스다.
자바 기반 설정을 사용한다면 아래 예제처럼 스프링 배치 빌더를 사용한다:
/**
* Note the JobRepository is typically autowired in and not needed to be explicitly
* configured
*/
@Bean
public Job sampleJob(JobRepository jobRepository, Step sampleStep) {
return this.jobBuilderFactory.get("sampleJob")
.repository(jobRepository)
.start(sampleStep)
.build();
}
/**
* Note the TransactionManager is typically autowired in and not needed to be explicitly
* configured
*/
@Bean
public Step sampleStep(PlatformTransactionManager transactionManager) {
return this.stepBuilderFactory.get("sampleStep")
.transactionManager(transactionManager)
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.build();
}
위 설정은 아이템 지향 step을 생성하는 데 꼭 필요한 의존성(dependency)만 보여주고 있다.
reader: 처리할 아이템을 제공하는ItemReaderwriter:ItemReader가 제공하는 아이템을 처리할ItemWritertransactionManager: 트랜잭션을 시작하고 커밋하는 스프링의PlatformTransactionManagerrepository:StepExecution과ExecutionContext를 주기적으로(커밋 직전) 저장하는JobRepositorychunk: 트랜잭션을 커밋하기 전까지 처리할 아이템 수로, 아이템 기반 step이라는 걸 보여줌
디폴트 레포지토리는 jobRepository, 디폴트 트랜잭션 매니저는 transactionManger라는 걸 명심해라
(모두 @EnableBatchProcessing을 통해 제공된다).
아이템은 아무런 처리 없이 reader에서 writer로 바로 전달될 수도 있기 때문에 ItemProcessor는 옵션이다.
5.1.3. The Commit Interval
앞에서 말했듯이 step은 아이템을 읽고 쓰는 동안 설정되어 있는 PlatformTransactionManager를 사용해 주기적으로 커밋한다.
commit-interval이 1이면 각 아이템을 write할 때마다 커밋한다.
트랜잭션을 시작하고 커밋하는 건 소모적이기 때문에 보통 이렇게 사용하진 않는다.
보통은 한 트랜잭션에서 가능한 많은 아이템을 처리하는데,
처리하는 데이터 유형과 step이 상호작용하는 리소스에 따라 천차만별이다.
그렇기 때문에 한 커밋에서 처리할 아이템 수를 직접 설정할 수 있다.
아래 예제는 tasklet의 commit-interval이 10인 step을 사용한다.
@Bean
public Job sampleJob() {
return this.jobBuilderFactory.get("sampleJob")
.start(step1())
.end()
.build();
}
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.build();
}
앞의 예제는 한 트랜잭션에서 아이템을 10개씩 처리한다.
데이터를 처리하기 전에 트랜잭션을 시작한다.
ItemReader의 read 메소드를 호출할 때마다 카운터가 증가한다.
카운터가 10이 되면 합쳐진 아이템 리스트는 ItemWriter로 넘겨지고 트랜잭션이 커밋된다.
5.1.4. Configuring a Step for Restart
Configuring and Running a Job 섹션에서
Job을 재시작하는 방법을 다뤘다.
재시작은 step에도 큰 영향을 주므로 몇 가지 설정이 필요하다.
Setting a Start Limit
종종 Step의 실행 횟수를 조정하고 싶을 때가 있을 것이다.
예를 들어, 일부 자원을 무효화시키는 Step이 있어서 다시 실행하기 전
수동으로 수정해야 한다면, 한 번만 실행되도록 설정해야 한다.
step마다 요구사항이 다를 수 있기 때문에 step 레벨에 설정할 수 있다.
하나의 Job에 한 번만 실행해야 하는 Step과 그렇지 않은 Step이 같이 있는 경우도 있다.
다음은 start limit을 설정하는 샘플 코드다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.startLimit(1)
.build();
}
위 step은 한 번만 실행할 수 있다.
다시 실행하려고 하면 StartLimitExceededException이 발생한다.
start-limit의 디폴트 값은 Integer.MAX_VALUE이다.
Restarting a Completed Step
재시작 가능한 job이라면 첫 실행에서 성공했는 지와는 상관없이 항상 실행해야 하는 step도 있을 수 있다.
유효성 검증 step이나 배치 전 리소스를 정리하는 Step이 그렇다.
재시작된 job을 처리하는 동안에는 ‘COMPLETED’ 상태를 가진, 즉 이미 성공적으로 완료된 step은 스킵한다.
아래 예제처럼 allow-start-if-complete가 “true”로 설정된 step은 항상 실행된다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.allowStartIfComplete(true)
.build();
}
Step Restart Configuration Example
아래 예제에서는 재시작 가능한 step을 가진 job 설정법을 보여준다:
@Bean
public Job footballJob() {
return this.jobBuilderFactory.get("footballJob")
.start(playerLoad())
.next(gameLoad())
.next(playerSummarization())
.end()
.build();
}
@Bean
public Step playerLoad() {
return this.stepBuilderFactory.get("playerLoad")
.<String, String>chunk(10)
.reader(playerFileItemReader())
.writer(playerWriter())
.build();
}
@Bean
public Step gameLoad() {
return this.stepBuilderFactory.get("gameLoad")
.allowStartIfComplete(true)
.<String, String>chunk(10)
.reader(gameFileItemReader())
.writer(gameWriter())
.build();
}
@Bean
public Step playerSummarization() {
return this.stepBuilderFactor.get("playerSummarization")
.startLimit(2)
.<String, String>chunk(10)
.reader(playerSummarizationSource())
.writer(summaryWriter())
.build();
}
위 예제는 축구 게임 정보를 읽어와서 요약하는 job을 설정하고 있다.
playerLoad, gameLoad, playerSummarization 세 가지 step이 있다.
playerLoad step은 플랫(flat) 파일에서 선수 정보를 읽어오고, gameLoad step은 같은 방법으로 게임 정보를 읽어온다.
마지막 playerSummarization step은 읽어온 게임 정보를 참고해서 각 선수에 대한 요약통계를 추출한다.
playerLoad에서 읽는 파일은 한 개여서 한 번에 읽어올 수 있지만,
gameLoad는 특정 디렉토리 아래 있는 어떤 게임 파일이라도 읽을 수 있으며
성공적으로 데이터베이스에 저장한 다음에는 파일을 지운다고 가정한다.
따라서 playerLoad는 몇 번이고 실행돼도 괜찮고, 이미 완료됐다면 스킵해도 좋기 때문에 별다른 설정이 없다.
그러나 gameLoad step은 이전에 실행된 이후 파일이 추가되었을 수도 있으므로 매번 실행해야 한다.
항상 실행될 수 있도록 ‘allow-start-if-complete’를 ‘true’로 설정했다.
(게임을 저장하는 데이터베이스에는 실행을 식별할 수 있는 값이 있어서,
summarization step에서 게임이 새로 추가된 게임인지 아닌지를 알 수 있다고 가정한다.)
가장 중요한 summarization step은 start limit을 2로 설정했다.
step이 계속해서 실패하면 새 종료코드가 리턴되므로 job 운영자는 수동 처리가 필요하다는 걸 인지할 수 있다.
이 job은 이 문서의 예시일 뿐이며 샘플 프로젝트에 있는
footballJob과는 동일하지 않다.
여기서부터 footballJob 예제를 세 번 실행했을 때의 각 동작을 설명하겠다.
Run 1:
playerLoad이 실행되고 정상적으로 완료되어 ‘PLAYERS’ 테이블에 400명의 선수 정보를 추가한다.gameLoad이 실행되고 게임 데이터에 해당하는 11개의 파일을 처리해 ‘GAMES’ 테이블에 저장한다.playerSummarization이 시작하고 5분 뒤에 실패한다.
Run 2:
playerLoad는 이전에 이미 성공했고allow-start-if-complete이 ‘false’(디폴트)이므로 실행되지 않는다.gameLoad는 다시 실행되어 다른 2개의 파일을 처리하고 마찬가지로 ‘GAMES’ 테이블에 저장한다 (실행을 식별할 수 있는 값과 함께 저장).playerSummarization은 남은 모든 데이터(실행을 식별할 수 있는 값으로 필터링함)를 처리하고 30분 뒤 다시 실패한다.
Run 3:
playerLoad는 이전에 이미 성공했고allow-start-if-complete이 ‘false’(디폴트)이므로 실행되지 않는다.gameLoad는 다시 실행되어 다른 2개의 파일을 처리하고 마찬가지로 ‘GAMES’ 테이블에 저장한다 (실행을 식별할 수 있는 값과 함께 저장).playerSummarization을 실행하지 않은 채로 job은 즉시 종료된다.playerSummarization을 세 번째 실행하는 건데, 두 번으로 제한되어있기 때문이다. 이 제한을 바꾸던가 새JobInstance로Job을 실행해야 한다.
5.1.5. Configuring Skip Logic
중간에 에러가 발생하면 Step을 실패로 끝내는 대신 무시하고 넘어가야 하는 케이스도 많다.
보통 이런건 데이터가 무엇인지 이해하고 있는 사람이 결정한다.
예를 들어 금융 데이터를 다룰 때는 돈이 송금될 수도 있으므로, 완전 무결해야 하며 실패했을 때 그냥 넘어가선 안 된다.
반면 벤더 리스트를 읽어들일 때는 그냥 넘어가도 상관 없다.
데이터 포맷이 잘못되거나 필수 정보가 누락되서 벤더 정보를 읽어들이지 못하는 경우라면 크게 문제 되지 않는다.
잘못된 로그가 저장되는 경우도 빈번하며, 이런 케이스를 다루는 방법은 뒤에서 listener를 다룰 때 설명하겠다.
아래 예제는 skip limit을 사용한 예제이다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(FlatFileParseException.class)
.build();
}
앞의 예제는 FlatFileItemReader를 사용했다.
언제든지 FlatFileParseException이 발생하면 해당 아이템은 건너뛰고 skip limit으로 설정된 10이 될 때까지 카운팅한다.
선언되어있는 Exception(혹은 하위 클래스들)은 청크 프로세싱(read, process, write)의 모든 단계에서 발생할 수 있는데,
step 내에 read, process, write 별로 각각 skip 카운트를 매기지만 이 limit 값은 모두에 적용된다.
skip limit에 도달했는데 또 예외가 발생하면 그땐 step이 실패로 끝난다.
다시 말해 10번은 괜찮아도 11번째 skip은 예외를 발생시킨다.
앞에 예제에 한 가지 문제점이 있는데, FlatFileParseException이 아닌 다른 예외가 발생하면 Job은 실패한다.
물론 이 동작을 의도했을 수도 있다.
아래 예제처럼 실패로 간주할 예외만 지정하고 나머지는 건너뛰게 만들면 문제는 단순해진다.
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(flatFileItemReader())
.writer(itemWriter())
.faultTolerant()
.skipLimit(10)
.skip(Exception.class)
.noSkip(FileNotFoundException.class)
.build();
}
java.lang.Exception을 건너뛰어도 되는 exception 클래스로 지정했는데, 이는 모든 Exception을 무시하겠다는 뜻이다.
하지만 java.io.FileNotFoundException을 예외로 둠으로써, FileNotFoundException을 제외한 모든 Exception을 무시할 예외 클래스로 지정한다.
치명적일 수 있는 클래스는 예외로 둔다. (즉, 건너뛰지 않음).
어떤 exception이 발생하더라도, 건너뛸지 말지는 클래스 계층에서 가장 가까운 슈퍼클래스를 참조해 결정한다. 지정되지 않은 exception은 ‘fatal’로 간주한다.
skip noSkip 메소드 호출 순서는 아무런 상관이 없다.
5.1.6. Configuring Retry Logic
대부분은 예외를 무시하고 넘어가거나 Step을 실패로 만드는 걸로 충분하지만, 모두 그런 것은 아니다. 파일을 읽는 동안 FlatFileParseException이 발생하면 항상 예외를 발생시킨다. 여기선 ItemReader를 바꾸는 게 능사는 아니다. 반면 성격이 다른 예외도 있다. 예를 들어 DeadlockLoserDataAccessException은 현재 프로세스가 다른 프로세스가 이미 락(lock)을 소유한 데이터를 수정하려 했을 때 발생하는데, 기다렸다가 다시 시도하면 성공할 수도 있다. 이런 경우라면 아래처럼 재시도(retry)를 설정하는 게 좋다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.retryLimit(3)
.retry(DeadlockLoserDataAccessException.class)
.build();
}
이 Step은 각 item을 재시도할 수 있는 횟수와 ‘재시도 가능한(retryable)’ exception 리스트를 정의했다. 재시도가 어떤 방식으로 이뤄지는지는 retry에서 자세히 설명한다.
5.1.7. Controlling Rollback
기본적으로 재시도 여부에 상관없이 ItemWriter에서 발생하는 모든 예외는 Step에서 처리되는 트랜잭션을 롤백시킨다.
이전에 나온 예제처럼 재시도 없이 넘어가도록(skip) 설정되었다면 ItemReader에서 발생한 예외는 롤백을 발생시키지 않는다.
하지만 트랜잭션을 무효화시킬 다른 조치가 따로 필요하다면, ItemWriter에서 발생한 예외가 롤백을 유발하면 안 될 수도 있다.
그렇기 때문에 아래 예제에서처럼 Step에 롤백을 유발하지 않는 exception 리스트를 지정할 수 있다.
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.faultTolerant()
.noRollback(ValidationException.class)
.build();
}
Transactional Readers
ItemReader는 데이터를 읽을 때 기본적으로 앞에서 뒤로만 읽고 역행하지 않는다 (forward only).
step은 데이터를 읽고 나면 버퍼에 넣어두기 때문에 롤백되었을 때 한 번 읽어들인 데이터를 다시 읽어올 필요는 없다.
하지만 어떤 경우에는 reader가 트랜잭션 리소스보다 상위 레벨에 있을 수도 있다 (e.g JMS 큐).
이런 경우 큐가 롤백되는 트랜잭션과 엮여있기 때문에 큐로부터 읽어온 메세지는 여전히 큐에 남아있다.
이런 이유로 아래 예제처럼 step이 버퍼를 사용하지 않도록 설정할 수 있다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.readerIsTransactionalQueue()
.build();
}
5.1.8. Transaction Attributes
트랜잭션 속성값으로 트랜잭션 고립 수준(isolation), 전파(propagation), 타임아웃을 설정할 수 있다. 트랜잭션 속성에 대한 자세한 설명은 스프링 코어 문서을 참고하라. 아래 예제에서는 고립 수준, 전파, 타임아웃을 설정한다:
@Bean
public Step step1() {
DefaultTransactionAttribute attribute = new DefaultTransactionAttribute();
attribute.setPropagationBehavior(Propagation.REQUIRED.value());
attribute.setIsolationLevel(Isolation.DEFAULT.value());
attribute.setTimeout(30);
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(itemWriter())
.transactionAttribute(attribute)
.build();
}
5.1.9. Registering ItemStream with a Step
step의 생명주기 동안 ItemStream 콜백을 처리해야 할 때가 있다
(ItemStream에 대한 자세한 설명은 ItemStream 참고 ).
ItemStream은 step이 실패해서 재시작하려는 경우에 각 실행 상태에 대해 꼭 필요한 정보를 얻을 수 있는 매우 중요한 인터페이스를 제공한다.
ItemStream 인터페이스를 ItemReader, ItemProcessor, ItemWriter 중 하나로 구현하면 자동으로 등록된다.
다른 steam 구현체는 별도로 등록해야 한다.
위임받은 객체(delegate)처럼 reader나 writer에 간접적으로 의존성(dependency)을 주입하는 경우가 그렇다.
아래 예제처럼 Step에 stream을 등록할 땐 ‘stream’ 메소드를 사용한다.
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(2)
.reader(itemReader())
.writer(compositeItemWriter())
.stream(fileItemWriter1())
.stream(fileItemWriter2())
.build();
}
/**
* In Spring Batch 4, the CompositeItemWriter implements ItemStream so this isn't
* necessary, but used for an example.
*/
@Bean
public CompositeItemWriter compositeItemWriter() {
List<ItemWriter> writers = new ArrayList<>(2);
writers.add(fileItemWriter1());
writers.add(fileItemWriter2());
CompositeItemWriter itemWriter = new CompositeItemWriter();
itemWriter.setDelegates(writers);
return itemWriter;
}
위에서 보이는 CompositeItemWriter는 ItemStream이 아니며, 두 stream에게 위임한다(delegate).
따라서 두 delegate writer는 명시적으로 stream으로 등록해주어야 프레임워크에서 처리할 수 있다.
ItemReader는 Step의 프로퍼티이므로 따로 stream으로 등록하지 않아도 된다.
위 step은 재시작 가능한 step인데, 실패 이벤트가 발생해도 reader와 writer 상태를 저장할 수 있다.
5.1.10. Intercepting Step Execution
Job과 마찬가지로 Step에서도 실행 중 발생한 특정 이벤트를 별도로 처리해야 할 때가 있다.
예를 들어 맨 끝에 꼬리말이 필요한 파일에 데이터를 쓰고 있다면
ItemWriter는 Step이 완료됐을 때 통지를 받아야만 꼬리말을 써넣을 수 있다.
이를 위한 여러 가지 Step 레벨의 리스너가 준비돼 있다.
모든 StepListener를 확장한 구현체는 (인터페이스는 비어있으므로 해당하지 않음)
listener 메소드로 step에 등록할 수 있다.
listener는 step, tasklet, 청크 단위 사용할 수 있다.
리스너가 필요한 레벨에 등록하는 게 좋지만, 리스너가 여러 개라면 (StepExecutionListener, ItemReadListener 같은)
세분화해서 필요한 곳에 각각 등록하는 게 낫다.
아래 예제에서는 청크 레벨로 리스너를 등록했다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(reader())
.writer(writer())
.listener(chunkListener())
.build();
}
네임스페이스에 <step>을 사용하거나 *StepFactoryBean 중 하나를 사용해 Step을 만들었다면
StepListener를 구현한 ItemReader, ItemWriter, ItemProcessor는 자동으로 등록된다.
즉 Step에 직접 주입하는 컴포넌트는 자동이다.
다른 컴포넌트 안에 감싸져 있는(nested) 리스너는 명시적으로 등록해야 한다
(Registering ItemStream with a Step 예제처럼).
StepListener가 아니어도 어노테이션으로 같은 관심사를 처리할 수 있다.
일반 자바 객체 메소드 위에 이 어노테이션을 선언하면 그에 맞는 StepListener로 변환된다.
ItemReader, ItemWriter, Tasklet 같은 청크 컴포넌트를 커스텀해서 어노테이션을 다는 방법도 많이 쓰인다.
빌더의 listener 메소드로 리스너를 등록하듯,
어노테이션을 선언하면 XML 파서가 <listener/> 요소로 처리하므로,
XML 네임스페이스나 빌더 둘 중 하나만 사용하면 step에 리스너를 등록할 수 있다.
StepExecutionListener
Step을 실행할 때는 StepExecutionListener를 가장 많이 사용한다.
아래 예제에 보이듯, Step의 성공/실패 여부와 상관없이 step 시작 전과 완료 후에 통지를 보낸다.
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}
afterStep에서 인자로 받는 ExitStatus로 종료 코드를 수정할 수 있다.
위 인터페이스와 동일한 어노테이션:
@BeforeStep@AfterStep
ChunkListener
청크는 트랜젹션 스코프에서 처리하는 아이템 묶음이다.
각 커밋 인터벌마다 트랜잭션을 커밋하는데, 이때 이 ‘청크’를 커밋한다.
ChunkListener는 청크를 처리하기 전이나 청크가 완료되고 난 후에 호출된다.
인터페이스 정의는 다음과 같다:
public interface ChunkListener extends StepListener {
void beforeChunk(ChunkContext context);
void afterChunk(ChunkContext context);
void afterChunkError(ChunkContext context);
}
beforeChunk 메소드는 트랜잭션이 시작된 후 호출되는데, 아직 ItemReader의 read 메소드를 호출하기 전이다.
반대로 afterChunk 메소드는 청크가 커밋된 후 호출된다 (롤백됐다면 호출되지 않는다).
위 인터페이스와 동일한 어노테이션:
@BeforeChunk@AfterChunk@AfterChunkError
청크 선언이 없어도 ChunkListener를 사용할 수 있다.
TaskletStep이 ChunkListener를 호출하는데,
아이템 기반이 아닌 tasklet에도 마찬가지로 적용된다 (tasklet 전과 후에 호출된다).
ItemReadListener
전에 skip을 설명할 때, 무시하고 지나간 데이터를 어딘가에 기록해두면 나중에 처리할 수 있다고 언급했었다.
아래 인터페이스를 보면 알겠지만 읽기에 실패한 경우 ItemReaderListener로 로그를 남길 수 있다.
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}
beforeRead 메소드는 ItemReader의 read 메소드를 호출하기 전 매번 호출된다.
afterRead 메소드는 read 메소드 호출에 성공할 때마다 호출하며, 읽은 아이템을 인자로 받는다.
읽는 도중 에러가 발생하면 onReadError 메소드가 호출된다.
발생한 exception 정보도 함께 전달되므로 여기서 로그에 남길 수 있다.
위 인터페이스와 동일한 어노테이션:
@BeforeRead@AfterRead@OnReadError
ItemProcessListener
ItemReadListener처럼 아이템을 처리(process)할 때도 리스너를 사용할 수 있다:
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}
beforeProcess 메소드는 ItemProcessor의 process 메소드 전 호출되며,
처리할 아이템을 넘겨받는다.
afterProcess 메소드는 아이템을 성공적으로 처리한 다음 호출한다.
처리 중 에러가 발생하면 onProcessError 메소드를 호출한다.
exception과 처리하려고 했던 아이템 정보를 함께 넘겨받으므로 로그에 남길 수 있다.
위 인터페이스와 동일한 어노테이션:
@BeforeProcess@AfterProcess@OnProcessError
ItemWriteListener
아이템을 write할 때는 ItemWriteListener를 사용한다:
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}
beforeWrite는 ItemWriter의 write 메소드 전 호출되며 write할 아이템 리스트를 넘겨받는다.
afterWrite메소드는 아이템을 성공적으로 write한 다음 호출한다.
아이템을 쓰는 중 에러가 발생하면 onWriteError 메소드를 호출한다.
exception과 쓰려고 했던 아이템 정보를 함께 넘겨받으므로 로그에 남길 수 있다.
위 인터페이스와 동일한 어노테이션:
@BeforeWrite@AfterWrite@OnWriteError
SkipListener
ItemReadListener, ItemProcessListener, ItemWriteListener 모두
에러를 통지해주지만,
데이터가 스킵된 경우는 알려주지 않는다.
예를 들어 onWriteError 메소드는 재시도로 성공한 경우에도 호출된다.
따라서 스킵된 아이템을 추적하기 위한 별도의 인터페이스를 제공한다:
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}
onSkipInRead 메소드는 아이템을 읽는 동안 아이템이 스킵될 때마다 호출된다.
주의할 점은, 롤백된 경우에는 같은 아이템이 여러 번 스킵된 걸로 간주할 수도 있다.
onSkipInWrite 메소드는 아이템을 쓰는 동안 아이템을 스킵할 때 호출한다.
이때는 아이템을 읽는 데는 성공했으므로 (읽는 도중 스킵되지 않고), 메소드 인자로 아이템을 제공한다.
위 인터페이스와 동일한 어노테이션:
@OnSkipInRead@OnSkipInWrite@OnSkipInProcess
SkipListeners and Transactions
스킵된 아이템을 로깅할 때 SkipListener를 가장 많이 쓰는데,
skip된 이슈를 확인하고 수정하려면 다른 배치 프로세스나 심지어 수동 작업이 필요할 때가 있다.
기존 트랜잭션이 롤백되었다면, 여러 가지 이유가 있을 수 있으므로 스프링 배치는 다음 두 가지를 보장한다:
- 적절한 skip 메소드를(에러 발생 시점에 따라 다름) 아이템마다 한 번만 호출한다.
SkipListener는 항상 트랜잭션이 커밋 되기 직전에 호출한다. 따라서ItemWriter에서 오류가 발생해도 리스너에서 호출하는 트랜잭션까지 롤백되지 않는다.
5.2. TaskletStep
청크 기반 처리가 Step을 다루는 절대적인 방법은 아니다.
Step이 반드시 저장 프로시저(stored procedure)를 호출해야 한다면 어떻게 해야 할까?
ItemReader에 호출부를 구현하고 프로시저가 끝나면 null을 리턴하게 만들 수도 있다.
하지만 ItemWriter가 아무 일도 하지 않으므로 부자연스럽게 느껴진다.
스프링 배치는 이런 케이스를 위해 TaskletStep을 제공한다.
Tasklet은 execute 메소드 하나를 가진 심플한 인터페이스인데, 이 메소드는
RepeatStatus.FINISHED가 리턴되거나 실패했단 뜻으로 exception이 던져지기 전까지
TaskletStep이 반복적으로 호출한다.
각 Tasklet 호출은 트랜잭션으로 감싸져 있다.
Tasklet 구현부는 저장 프로시저나 스크립트를 호출하거나 간단한 SQL 업데이트 구문이 될 수 있다.
TaskletStep을 생성하려면 빌더의 tasklet 메소드에 Tasklet 인터페이스를 구현한 빈을 넘겨야 한다.
TaskletStep을 만들 때는 chunk 메소드를 사용하면 안 된다.
아래 예제는 간단한 tasklet을 만드는 샘플 코드다:
@Bean
public Step step1() {
return this.stepBuilderFactory.get("step1")
.tasklet(myTasklet())
.build();
}
tasklet이
StepListener인터페이스를 구현했다면TaskletStep이 자동으로 이 tasklet을StepListener로 등록한다.
5.2.1. TaskletAdapter
ItemReader, ItemWriter 인터페이스의 어댑터(adapter)처럼
Tasklet 인터페이스도 기존 클래스에 꽂아서 사용할 수 있는 TaskletAdapter가 있다.
예를 들어 레코드 셋 플래그를 업데이트할 때 사용힐 DAO가 이미 있는 경우에 어댑터를 사용할 수 있다.
TaskletAdapter를 사용하면 Tasklet 인터페이스를 위한 어댑터를 직접 구현하지 않고도 이 클래스를 호출할 수 있다.
@Bean
public MethodInvokingTaskletAdapter myTasklet() {
MethodInvokingTaskletAdapter adapter = new MethodInvokingTaskletAdapter();
adapter.setTargetObject(fooDao());
adapter.setTargetMethod("updateFoo");
return adapter;
}
5.2.2. Example Tasklet Implementation
리소스 세팅을 위해 시작 전 꼭 호출해야 하는 step이나,
리소스 정리(cleanup)를 위해 완료 후 꼭 호출해야 하는 step이 필요한 경우도 많다.
파일 처리가 많은 job이라면 파일을 다른 위치에 쓰고나서 원본을 지우는 경우가 종종 있다.
아래 예제는 (Spring Batch samples project에서 따온)
그런 일을 처리하는 Tasklet 구현체다:
public class FileDeletingTasklet implements Tasklet, InitializingBean {
private Resource directory;
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
File dir = directory.getFile();
Assert.state(dir.isDirectory());
File[] files = dir.listFiles();
for (int i = 0; i < files.length; i++) {
boolean deleted = files[i].delete();
if (!deleted) {
throw new UnexpectedJobExecutionException("Could not delete file " +
files[i].getPath());
}
}
return RepeatStatus.FINISHED;
}
public void setDirectoryResource(Resource directory) {
this.directory = directory;
}
public void afterPropertiesSet() throws Exception {
Assert.notNull(directory, "directory must be set");
}
}
앞에 있는 Tasklet 구현체는 주어진 디렉토리에 있는 파일을 모두 지운다.
execute 메소드는 한 번만 호출된다는 점에 주의해라.
이제 남은 건 Step에 이 Tasklet을 알려주는 일이다:
@Bean
public Job taskletJob() {
return this.jobBuilderFactory.get("taskletJob")
.start(deleteFilesInDir())
.build();
}
@Bean
public Step deleteFilesInDir() {
return this.stepBuilderFactory.get("deleteFilesInDir")
.tasklet(fileDeletingTasklet())
.build();
}
@Bean
public FileDeletingTasklet fileDeletingTasklet() {
FileDeletingTasklet tasklet = new FileDeletingTasklet();
tasklet.setDirectoryResource(new FileSystemResource("target/test-outputs/test-dir"));
return tasklet;
}
5.3. Controlling Step Flow
job은 소유한 여러 step을 함께 묶을 수 있으므로, 각 step 어떻게 연결(flow)할지도 결정할 수 있어야 한다.
Step이 실패했다고 해서 반드시 Job도 실패로 끝나야 하는 건 아니다.
게다가 step이 ‘성공’했다고 해서 모두 같은 ‘성공’은 아니다.
다음에 실행해야 할 step이 다를 수 있다.
Step 그룹이 어떻게 설정됐냐에 따라 특정 step은 전혀 실행되지 않을 수도 있다.
5.3.1. Sequential Flow
아래는 모든 step이 항상 순차적으로 실행되는 가장 간단한 job을 도식화한 그림이다:
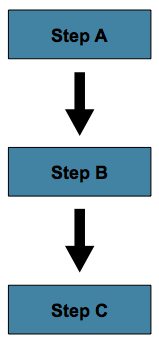
아래 샘플 코드처럼 step element의 ‘next’ attribute를 사용해 구현한다:
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA())
.next(stepB())
.next(stepC())
.build();
}
위 코드대로라면 가장 먼저 선언된 Step인 ‘step A’가 가장 먼저 실행된다.
그런데 ‘step A’가 실패하면 전체 Job이 실패로 끝나 ‘step B’는 실행하지 않는다.
5.3.2. Conditional Flow
위 예제에서는 두 가지만 가능하다:
Step이 성공하고 다음Step을 진행한다.Step이 실패하고 따라서Job도 실패한다.
이것만으로 충분한 경우도 많다.
하지만 Step의 실패가 전체 실패를 유발하면 안 되고 다른 Step을 유발해야 하는 경우라면?
아래 그림은 이런 flow를 도식화했다:
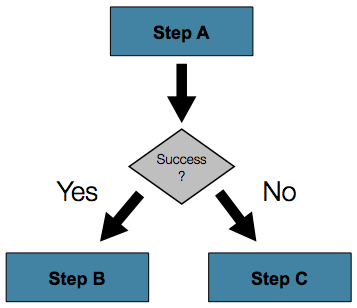
스프링 배치 네임스페이스를 사용한다면 step에 transition element를 정의해서 더 복잡한 케이스를 처리할 수 있다.
next element도 transition 중 하나이다.
next attribute처럼 next element는 Job에게 다음에 실행할 Step을 알려준다.
하지만 attribute와는 달리 next element는 몇 개든지 Step에 등록할 수 있으며
실패 시 처리할 디폴트 액션이라는 게 존재하지 않는다.
즉 transition element를 사용하려면 모든 Step transition 행동을 명시적으로 정의해야 한다.
또한 step 한 개가 next attribute와 transition element를 둘 다 가질 수는 없다.
아래 예제처럼 next element에 매칭시킬 패턴을 넘겨서 다음 실행할 step을 정할 수 있다:
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA())
.on("*").to(stepB())
.from(stepA()).on("FAILED").to(stepC())
.end()
.build();
}
자바 기반 설정이라면 on 메소드에
간단한 패턴 매칭 스키마를 사용한 값을 넘겨주면 되는데,
이는 Step의 실행 결과로 돌려받는 ExitStatus와 매칭한다.
패턴 안에서 특수문자는 다음 두 가지만 허용된다:
- “*” : 0개 이상의 문자와 매칭
- ”?” : 정확히 1개의 문자와 매칭
예를 들어 “c*t”는 “cat”과 “count”에 매칭되고, “c?t”는 “cat”에는 매칭되지만 “count”와는 매칭되지 않는다.
Step은 transition element 수에 제한이 없긴 하지만,
Step의 결과로 받은 ExitStatus가 어떤 element와도 매칭되지 않으면
프레임워크 단에서 예외을 발생시키고 Job은 실패한다.
transition은 구체적인 것부터 그렇지 않은 순서로 적용된다.
즉, 위 예제의 “stepA”의 순서를 바꿔도 “FAILED” 상태인 ExitStatus가 “stepC”를 유발한다.
Batch Status Versus Exit Status
Job에 조건적인 flow를 설정하려면
BatchStatus와 ExitStatus의 차이를 이해해야 한다.
BatchStatus는 JobExecution과 StepExecution의 프로퍼티로, 단순 열거형(enumeration)이며
Job과 Step의 상태를 나타낸다.
이 열거형 값 중 하나가 될 수 있다:
COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED, UNKNOWN.
대부분 설명이 필요하지 않을 것이다:
COMPLETED는 step이나 job이 성공적으로 완료된 상태를 나타낸다.
FAILED는 실패한 경우를 나타낸다.
다음은 자바 기반 설정으로 ‘on’ element를 사용한 예제다:
...
.from(stepA()).on("FAILED").to(stepB())
...
언뜻 보면 ‘on’ 메소드는 해당 Step의 BatchStatus를 나타내는 것처럼 보인다.
그러나 실제로는 Step의 ExitStatus를 참조한다.
이름에서 알 수 있듯, ExitStatus는 실행이 종료되고 난 다음의 Step 상태를 가지고 있다.
말로 풀어 설명하면 이렇다 : “종료 코드가 FAILED라면 stepB로 가라”.
기본적으로 종료코드는 Step의 BatchStatus와 항상 동일하기 때문에 아직까지는 딱히 문제가 없어 보인다.
하지만 종료 코드가 달라진다면?
samples project에 있는 skip sample job이 좋은 예시가 될 것이다:
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1()).on("FAILED").end()
.from(step1()).on("COMPLETED WITH SKIPS").to(errorPrint1())
.from(step1()).on("*").to(step2())
.end()
.build();
}
step1 다음 세 가지 케이스로 끝난다:
Step이 실패해서 job도 실패한다.Step이 성공한다.Step이 성공했지만 종료 코드가 ‘COMPLETED WITH SKIPS’다. 이땐 에러 처리를 위해 다른 step을 실행시켜야 한다.
위 설정은 잘 되었다. 하지만 아래 예제처럼 스킵된 execution 상태에 따라 종료 코드를 바꿔줘야 한다:
public class SkipCheckingListener extends StepExecutionListenerSupport {
public ExitStatus afterStep(StepExecution stepExecution) {
String exitCode = stepExecution.getExitStatus().getExitCode();
if (!exitCode.equals(ExitStatus.FAILED.getExitCode()) &&
stepExecution.getSkipCount() > 0) {
return new ExitStatus("COMPLETED WITH SKIPS");
}
else {
return null;
}
}
}
위 코드는 StepExecutionListener로, Step이 성공했는지 제일 먼저 확인하고 StepExecution에서 스킵된 횟수가 0보다 큰지를 체크한다.
두 조건이 모두 충족되면 COMPLETED WITH SKIPS라는 종료 코드를 가진 새 ExitStatus를 리턴한다.
5.3.3. Configuring for Stop
BatchStatus and ExitStatus를 봤다면,
Job의 BatchStatus와 ExitStatus는 어떻게 결정되는지 궁금한 사람도 있었을 것이다.
Step의 상태는 실행되는 코드로 결정되는 반면, Job의 상태는 설정에 따라 달라진다.
지금까지 다룬 job은 모두 transition이 없는 마지막 Step을 최소 한 개 이상 갖고 있었다.
예를 들어 아래 샘플처럼 step을 다 실행하고 나면 Job이 종료된다:
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.build();
}
Step에 정의된 transition이 없다면 아래 규칙대로 Job 상태를 정의한다:
Step이 끝나고ExitStatusFAILED를 리턴했다면,Job의BatchStatus와ExitStatus도FAILED다.- 그 외에는
Job의BatchStatus,ExitStatus모두COMPLETED다.
순차적인 step만 있는 단순한 job이라면 위 규칙대로 job을 끝내도 상관없지만,
커스텀한 job 종료 시나리오가 필요할 수도 있다.
이를 위해 스프링 배치는 Job을 종료시키기 위한 transition element 세 가지를 지원한다
(위에서 다룬 next element와는 별도로).
각 stopping element는 Job을 종료시키면서 BatchStatus를 적절한 값으로 설정해둔다.
stop transition element는 Step의 BatchStatus, ExitStatus에는 영향을 주지 않는다는 점을 주의해라.
이 element는 Job의 최종 상태만 변경한다.
예를 들어 job의 모든 step은 FAILED, job은 COMPLETED 상태로 종료시킬 수도 있다.
Ending at a Step
step이 끝나기만 하면 Job의 BatchStatus를 COMPLETED로 둔 채 종료할 수도 있다.
COMPLETED 상태로 종료된 Job은 재시작할 수 없다
(프레임워크에서 JobInstanceAlreadyCompleteException을 발생시킨다).
자바 기반 설정에선 ‘end’ 메소드를 사용한다.
end 메소드에 Job의 ExitStatus를 커스텀할 수 있는 ‘exitStatus’ 파라미터를 넘길 수도 있다 (옵션).
‘exitStatus’ 파라미터를 넘기지 않았다면
ExitStatus를 디폴트값인 COMPLETED로 설정해 BatchStatus와 통일시킨다.
아래 시나리오에서는 step2가 실패하면 Job은 BatchStatus가 COMPLETED,
ExitStatus가 COMPLETED인 상태로 종료되며, step3는 실행하지 않는다.
반대로 step2가 성공하면 다음은 step3를 실행한다.
step2가 실패하면 Job은 재시작되지 않는다는 점에 주의해라 (COMPLETED이므로).
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.next(step2())
.on("FAILED").end()
.from(step2()).on("*").to(step3())
.end()
.build();
}
Failing a Step
특정 step이 실패한 경우만 BatchStatus를 FAILED로 설정하고 Job을 중단하는 방법도 있다.
end 메소드와는 다르게 Job이 실패해도 재시작할 수 있다.
아래 예제에서는 step2가 실패하면 Job의 BatchStatus는 FAILED,
ExitStatus는 EARLY TERMINATION으로 두고 종료되며, step3를 실행하지 않는다.
반대로 step2가 성공하면 다음은 step3를 실행한다.
step2가 실패해서 Job을 재시작하면 step2부터 다시 실행한다.
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.next(step2()).on("FAILED").fail()
.from(step2()).on("*").to(step3())
.end()
.build();
}
Stopping a Job at a Given Step
특정 step에서 작업을 중단하도록 설정하면 BatchStatus가 STOPPED인 상태로 Job이 종료된다.
Job을 중단하면 중간에 잠깐의 텀이 생겨서 Job을 재시작하기 전 필요한 액션을 실행할 수 있다.
자바 기반 설정을 사용한다면 stopAndRestart 메소드에
“Job이 다시 실행됐을 때” 실행해야 할 step을 나타내는 ‘restart’ 인자를 넘겨야 한다.
아래 예제에서는 step1이 COMPLETE로 끝나면 job을 중단한다.
재시작되면 step2를 시작한다.
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1()).on("COMPLETED").stopAndRestart(step2())
.end()
.build();
}
5.3.4. Programmatic Flow Decisions
어떨 땐 다음 step을 결정하려면 ExitStatus 이외의 다른 정보가 필요하다.
이럴 경우엔 아래 예제처럼 JobExecutionDecider를 사용한다:
public class MyDecider implements JobExecutionDecider {
public FlowExecutionStatus decide(JobExecution jobExecution, StepExecution stepExecution) {
String status;
if (someCondition()) {
status = "FAILED";
}
else {
status = "COMPLETED";
}
return new FlowExecutionStatus(status);
}
}
아래 예제에선 자바 기반 설정을 사용해 JobExecutionDecider를 구현한 빈을 next 호출부에 직접 넘긴다.
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.next(decider()).on("FAILED").to(step2())
.from(decider()).on("COMPLETED").to(step3())
.end()
.build();
}
5.3.5. Split Flows
앞에 나온 모든 Job은 step을 한 번에 하나씩 선형적으로 실행한다.
스프링 배치는 이 전형적인 방법 외에 병렬 플로우(flow)를 지원한다.
자바 기반 설정에선 기본으로 제공하는 빌더로 split을 설정할 수 있다.
아래 예제에서 보이는 바와 같이 split element는 하나 이상의 ‘flow’ element를 포함하며,
여기서 전체 flow를 분리해 정의한다.
‘split’ element는 ‘next’ attribute, ‘next’, ‘end’, ‘fail’ element같이
앞에 나온 transition element라면 어떤 것이든 포함할 수 있다.
@Bean
public Job job() {
Flow flow1 = new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
Flow flow2 = new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
return this.jobBuilderFactory.get("job")
.start(flow1)
.split(new SimpleAsyncTaskExecutor())
.add(flow2)
.next(step4())
.end()
.build();
}
5.3.6. Externalizing Flow Definitions and Dependencies Between Jobs
일부 flow는 빈으로 따로 정의해서 재사용해도 된다. 두 가지 방법이 있는데, 첫 번째는 아래 예제처럼 다른 곳에 정의된 flow를 단순히 레퍼런스로 사용하는 것이다.
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(flow1())
.next(step3())
.end()
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
앞의 예제처럼 외부 flow를 사용하면 인라인으로 선언된 것과 마찬가지로 외부 flow의 step을 job에 추가한다. 이렇게 하면 여러 job에서 같은 템플릿 flow를 참조할 수 있으며, 템플릿을 여러 flow로 구성할 수 있다. 또한 각 flow의 통합 테스트를 분리하는 좋은 방법이 될 수 있다.
외부 flow를 사용하는 또 하나의 방법은 JobStep을 사용하는 것이다.
JobStep은 FlowStep과 비슷하지만 지정된 flow의 step마다 별도의 job을 생성하고 실행한다.
다음은 JobStep을 사용하는 예제이다:
@Bean
public Job jobStepJob() {
return this.jobBuilderFactory.get("jobStepJob")
.start(jobStepJobStep1(null))
.build();
}
@Bean
public Step jobStepJobStep1(JobLauncher jobLauncher) {
return this.stepBuilderFactory.get("jobStepJobStep1")
.job(job())
.launcher(jobLauncher)
.parametersExtractor(jobParametersExtractor())
.build();
}
@Bean
public Job job() {
return this.jobBuilderFactory.get("job")
.start(step1())
.build();
}
@Bean
public DefaultJobParametersExtractor jobParametersExtractor() {
DefaultJobParametersExtractor extractor = new DefaultJobParametersExtractor();
extractor.setKeys(new String[]{"input.file"});
return extractor;
}
jobParametersExtractor는 Step의 ExecutionContext를 Job이 실행되는 데 필요한 JobParameters로 변환하는 방법을 정의한다.
job과 step을 모니터링하고 리포팅기능을 구현하기 위해 더 세세한 옵션이 필요하다면 JobStep을 유용하게 쓸 수 있다.
여러 job에 의존성(dependency)을 설정하고 싶을 때도 JobStep으로 해결할 수 있다.
또 커다란 시스템을 작은 모듈로 쪼개고 job의 flow를 관리하는 데에도 좋다.
5.4. Late Binding of Job and Step Attributes
앞에 나온 XML과 플랫(flat) 파일 예제 모두 스프링의 Resource 인터페이스로 파일을 읽는다.
이는 Resource에 java.io.File을 리턴하는 getFile 메소드가 있어서 가능하다.
XML, flat file 리소스 모두 표준 스프링 구성으로 설정할 수 있다.
@Bean
public FlatFileItemReader flatFileItemReader() {
FlatFileItemReader<Foo> reader = new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource("file://outputs/file.txt"))
...
}
위에 있는 Resource는 명시된 파일 시스템 위치에서 파일을 로드한다.
절대 경로는 더블 슬래쉬 (//)로 시작한다는 점을 주의해라.
대부분 스프링 어플리케이션이라면 컴파일 타임에 리소스 이름을 알 수 있기 때문에 이 방식으로도 충분하다.
하지만 배치 처리라면, 런타임에 job에서 넘겨받는 파라미터로 파일명을 결정하는 경우도 있다.
이럴 때는 ‘-D’ 파라미터를 사용해 시스템 속성을 읽는다.
아래 예제는 프로퍼티로부터 파일명을 읽는 방법을 보여준다:
@Bean
public FlatFileItemReader flatFileItemReader(@Value("${input.file.name}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
위 코드가 동작하기 위해 필요한 건 시스템 인자(argument)가 전부다
(-Dinput.file.name="file://outputs/file.txt" 같은).
여기서는
PropertyPlaceholderConfigurer를 사용해도 괜찮지만 시스템 속성을 항상 사용한다면 설정하지 않아도 된다. 스프링엔 시스템 속성을 필터링하고 플레이스홀더를 치환하는ResourceEditor가 있기 때문이다.
보통 파일명을 시스템 속성으로 가져와서 직접 접근하기보단 JobParameters 활용을 선호한다.
아래 코드에서 보이는 것처럼 스프링 배치를 사용하면
Job이나 Step의 attribute 값을 나중에 바인딩할 수 있다:
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters['input.file.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
JobExecution, StepExecution 레벨의 ExecutionContext 모두 같은 방식으로 사용할 수 있다:
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobExecutionContext['input.file.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{stepExecutionContext['input.file.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
late-binding을 사용하는 모든 빈은 scope=”step”을 선언해야 한다. 자세한 정보는 Step Scope를 참조하라.
5.4.1. Step Scope
위에 있는 모든 late binding 예제는 아래처럼 빈을 정의할 때 “step” scope를 선언했다:
@StepScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters[input.file.name]}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
Step을 시작하기 전까지는 빈을 초기화할 수 없으므로 Step scope는 late-binding의 필수 조건이다.
scope는 스프링 컨테이너의 기본 기능이 아니기 때문에 명시적으로 추가해야 한다.
batch 네임스페이스를 사용하거나, StepScope 빈을 정의하거나,
@EnableBatchProcessing를 사용하거나.
세 방법 중 하나만 사용해라.
다음은 batch 네임스페이스를 사용한 예제이다:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>
다음은 StepScope 빈 정의를 선언한 예제이다:
<bean class="org.springframework.batch.core.scope.StepScope" />
5.4.2. Job Scope
스프링 배치 3.0에서 도입된 Job scope는 Step scope 설정과 유사하지만,
Job 컨텍스트를 위한 Scope이기 때문에
이 빈의 인스턴스는 실행 중인 job마다 하나씩만 가지고 있다.
#{..} 플레이스홀더로 JobContext에 나중에 바인딩되는(late binding) 값도 참조할 수 있다.
이 기능을 사용하면 아래 예제처럼 job이나 job 실행 컨텍스트,
job 파라미터로부터 빈 프로퍼티를 가져올 수 있다:
@JobScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobParameters[input]}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
@JobScope
@Bean
public FlatFileItemReader flatFileItemReader(@Value("#{jobExecutionContext['input.name']}") String name) {
return new FlatFileItemReaderBuilder<Foo>()
.name("flatFileItemReader")
.resource(new FileSystemResource(name))
...
}
scope는 스프링 컨테이너의 기본 기능이 아니기 때문에 명시적으로 추가해야 한다.
batch 네임스페이스를 사용하거나, JobScope 빈을 정의하거나,
@EnableBatchProcessing를 사용하거나 (모두 다 사용하는 건 안 된다).
다음은 batch 네임스페이스를 사용한 예제이다:
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="...">
<batch:job .../>
...
</beans>
다음은 JobScope 빈 정의를 선언한 예제이다:
<bean class="org.springframework.batch.core.scope.JobScope" />
Next :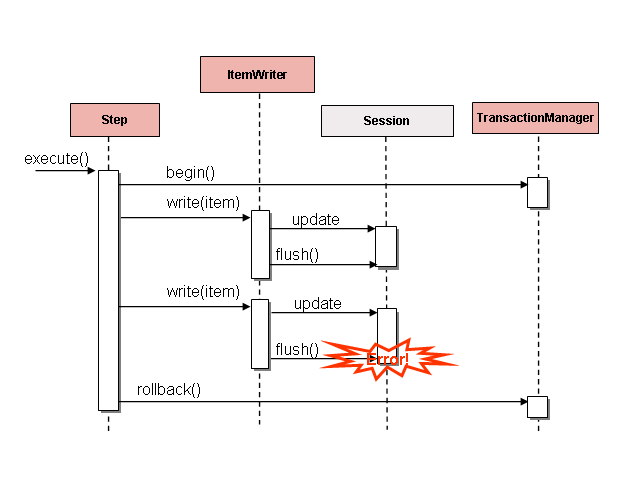 ItemReaders and ItemWriters
ItemReaders and ItemWriters
스프링 배치 ItemReader, ItemWriter 한글 번역
전체 목차는 여기에 있습니다.