스프링 클라우드 데이터 플로우 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
애플리케이션을 어떠한 환경에 배포할 땐, 보통은 인프라 중단 사태를 처리할 수 있는 전략을 세팅하는 게 이상적이다. 중단 범위는 하드웨어 장애부터 시작해, 데이터 센터가 완전히 오프라인이 돼서 애플리케이션들을 사용할 수 없게 되는 것까지 매우 다양하다. 인프라 문제가 해결될 때까지 운영을 잠재 중단하기보단, 워크로드를 다른 인프라로 마이그레이션해서 운영을 계속 이어가는 방안이 있다. 이럴 땐 특정 애플리케이션이 상주해야 하는 위치나, 함께 배치해야 하는 다른 애플리케이션들을 지정할 수 있으면 더 좋다.
쿠버네티스에선 노드가 실패하면, 실패한 노드에서 실행 중인 워크로드는 자동으로 사용 가능한 다른 노드로 다시 예약하는 식으로 처리된다. 간단한 유스 케이스에선 쿠버네티스 클러스터를 기본적으로 단일 컨트롤 영역control plane과, 같은 위치에 속한 여러 워커 노드들로 구성하는 경우가 많다. 하지만 이런 유형에선 장애 발생 시 고가용성을 지키기 어렵다.
이 레시피는 클라우드 provider GKEGoogle Kubernetes Engine에 초점을 두고 있으므로, 여기서 말하는 위치는 특정 “region” 안에 있는 하나 이상의 “zone”을 의미한다. “region”은 지리적인 위치를 말한다 (ex. us-east1). “region” 안에는 다른 zone들과는 격리돼있는 여러 가지 “zone”이 들어있다 (ex. us-east1-b, us-east1-c). region과 zone은 CPU/GPU 타입, 디스크 타입, 컴퓨팅 성능 등과 같은 구체적인 요구 사항을 기반으로 선택해야 한다. 구글의 Regions and Zones 문서를 읽어보면 어떤 것들을 검토해야 하는지 자세히 알 수 있다.
GKE는 single-zone 클러스터 외에 다른 클러스터 타입을 두 가지 지원한다:
- Multi-zonal 클러스터
- 단일 zone에서 실행되는 컨트롤 영역control plane (single replica)
- 지정 region에 있는 여러 zone에서 실행되는 워커 노드들
- Regional 클러스터
- 지정 region에 있는 여러 zone에서 실행되는 컨트롤 영역control plane (multiple replicas)
- 각 컨트롤 영역control plane과 동일한 zone에서 실행되는 노드들
이 레시피에선 “Single Zone”이나 “Multi-zonal” 클러스터보다 가용성이 더 뛰어난 “Regional 클러스터”를 중심으로 설명한다.
목차
- Prerequisites
- Creating the Cluster
- Verify the Cluster Creation
- Deploying Spring Cloud Data Flow
- Deploying Streams and Tasks
- Conclusion
Prerequisites
GKEGoogle Kubernetes Engine 클러스터를 새로 생성할 수 있는 권한을 가진 Google Cloud(GCP) 계정이 필요하다. GCP와 GKE와 상호작용할 땐 웹 인터페이스를 이용할 수 있다. Google Cloud SDK를 설치하면 커맨드라인 인터페이스도 사용할 수 있다. 쿠버네티스 클러스터와 상호 작용하려면 표준 도구를 설치해야 한다 (ex. Kubectl).
Creating the Cluster
이 레시피에선 GKE 웹 콘솔을 이용해 클러스터를 생성한다. location 타입과 인스턴스 사이즈를 제외하고는 대부분 기본값을 사용할 거다. 클러스터를 새로 생성할 땐 가장 먼저 “Cluster Basics”를 선택해야 한다. 이 데모에서 선택할 옵션은 아래 스크린샷에서 확인 수 있다:
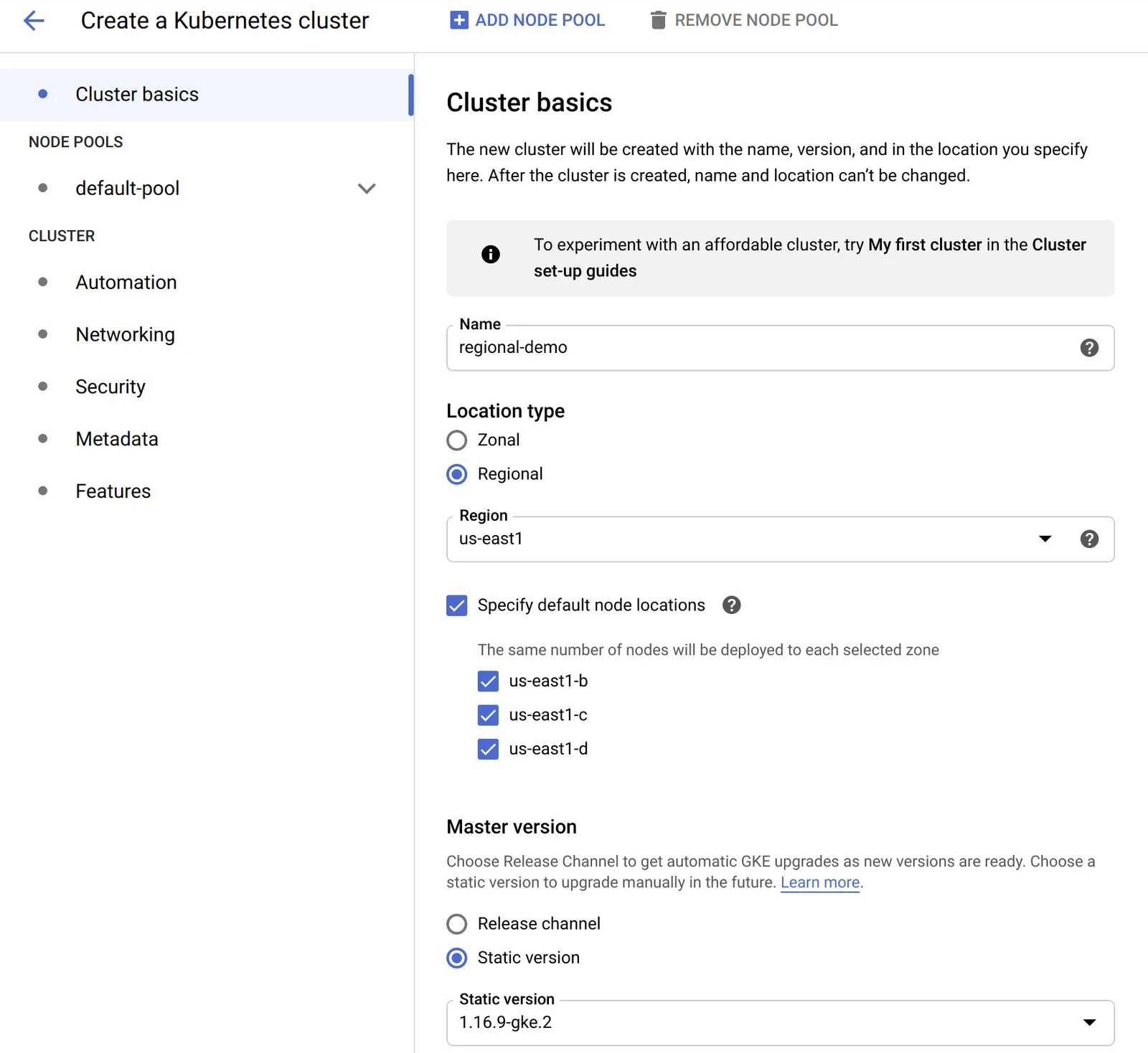
여기서 주목해야 하는 것들은:
Location Type에선Regional을 선택한다.Region을 선택한다 – 여기선us-east1을 골랐다. region은 앞에서 설명했던것 처럼, 가지고 있는 요구 사항에 따라 결정해야 한다.Specify default node locations에선 세 가지 zone을 선택했다. zone 3개는 자동으로 선택된다. zone이 3개보다 많을 때는 이 곳에서 직접 zone을 선택할 수 있다.
다른 값들은 (ex. Name, Master Version 설정) 적절히 커스텀해도 된다.
그 다음으론, 아래 이미지에서 보이는 것처럼 Node Pools -> default-pool의 하위에 있는 Nodes에서 머신 타입을 선택한다:
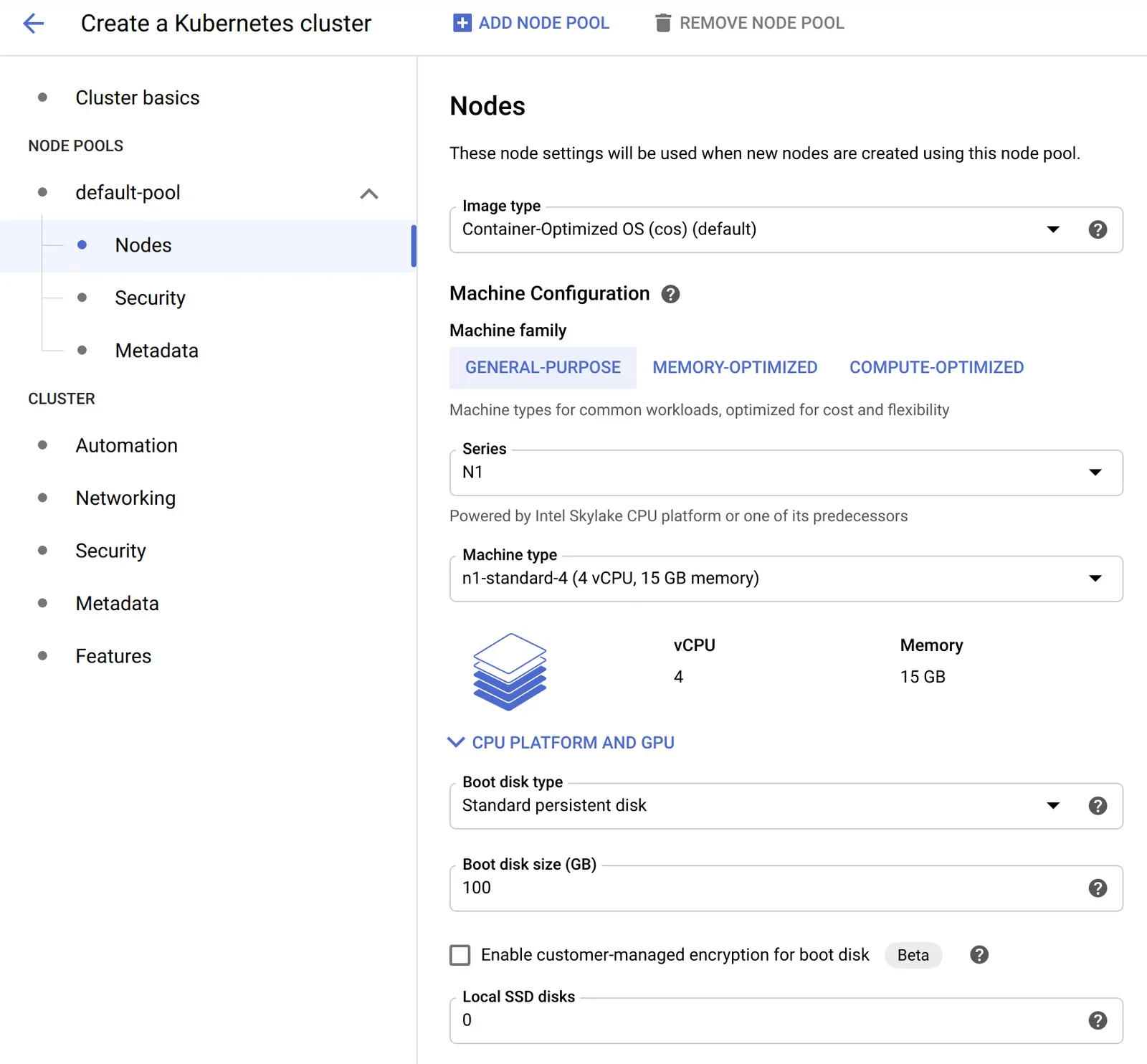
여기서 주요 변경점은 머신 타입에서 n1-standard-4 (4 vCPU, 15GB memory)를 선택하는 거다. 이 타입은 디폴트 타입보다 작업 공간을 약간 더 제공한다. 세팅은 적절히 커스텀해도 좋다.
노드 수와 머신 타입은 기본 요구사항 뿐 아니라 failover tolerance 요구에 따라서도 달라진다. 예를 들어, 노드들에 분산시킬 수 있는 예상 애플리케이션 수를 기반으로 선택한 머신의 사이즈를 조정할 수도 있다. 하지만 그럼에도 특정 노드나 하나 이상의 region 장애에 대비하려면, 다른 노드에서 부하를 대신 처리할 수 있을 만큼 클러스터 사이즈를 확보해야 한다. 사이즈를 확보할 수 없다면 그만큼 여유가 생기기 전까진 워크로드를 예약할 수 없게 된다. 이때는 다양한 전략을 구사할 수 있다. 예를 들어 미리 사이즈를 늘려놓거나, 클러스터 오토스케일러 등을 활용할 수 있다.
커스텀을 완료했다면, 아래 이미지에 보이는 Create 버튼을 클릭하고 클러스터를 생성하면 된다.

GKE UI를 사용하면 클러스터 설정을 간편하게 커스텀할 수 있지만, Google Cloud CLI에서도 같은 일을 할 수 있다.
command line링크를 클릭하면 손쉽게 명령어를 만들 수 있다. 링크를 클릭하면 똑같은 클러스터 설정을 생성할 수 있는 gcloud CLI 명령어가 적절히 만들어진다.
클러스터가 생성되면, 세 가지 zone에 각각 워커 노드가 3개씩 배포돼서, 총 9개의 워커 노드가 만들어진다. 참고로, GKE는 컨트롤 영역control plane 노드에 액세스하는 기능은 제공하지 않는다.
마지막으로 kubectl이 클러스터와 상호작용할 수 있으려면, gcloud CLI를 통해 credential을 가져와야 한다. 다음 명령어를 실행하면 된다:
$ gcloud container clusters get-credentials regional-demo --zone us-east1 --project PROJECT_ID
PROJECT_ID는 가지고 있는 GKE 프로젝트 ID로 변경해라. 추가로, 아래 명령어를 실행해서 컨텍스트 이름을 좀더 알아보기 쉽게 바꿔주자:
$ kubectl config rename-context gke_PROJECT_ID_us-east1_regional-demo regional-demo
kubectl을 이용해 현재 컨텍스트가 제대로 설정됐는지 확인해보자 (*로 표시한다):
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* regional-demo gke_PROJECT_ID_us-east1_regional-demo gke_PROJECT_ID_us-east1_regional-demo
Verify the Cluster Creation
워커 노드들을 사용할 수 있는 상태인지 확인해보자:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-regional-demo-default-pool-e121c001-k667 Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-e121c001-zhrt Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-e121c001-zpv4 Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-ea10f422-5f72 Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-ea10f422-ntdk Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-ea10f422-vw3c Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-fb3e6608-0lx2 Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-fb3e6608-0rcc Ready <none> 13m v1.16.9-gke.2
gke-regional-demo-default-pool-fb3e6608-2qsk Ready <none> 13m v1.16.9-gke.2
위에 보이는 것처럼, 9개의 노드들이 각 풀에 3개씩 나뉘어있다.
모든 노드는 failure-domain.beta.kubernetes.io/zone이라는 레이블을 가지고 있다. 이 레이블엔 노드가 위치하고 있는 zone을 저장한다. 어떤 노드가 어떤 zone에 있는지는 이 레이블로 식별할 수 있다. 예를 들면 다음과 같다:
$ kubectl get nodes -l failure-domain.beta.kubernetes.io/zone=us-east1-b
NAME STATUS ROLES AGE VERSION
gke-regional-demo-default-pool-ea10f422-5f72 Ready <none> 29m v1.16.9-gke.2
gke-regional-demo-default-pool-ea10f422-ntdk Ready <none> 29m v1.16.9-gke.2
gke-regional-demo-default-pool-ea10f422-vw3c Ready <none> 29m v1.16.9-gke.2
$ kubectl get nodes -l failure-domain.beta.kubernetes.io/zone=us-east1-c
NAME STATUS ROLES AGE VERSION
gke-regional-demo-default-pool-e121c001-k667 Ready <none> 29m v1.16.9-gke.2
gke-regional-demo-default-pool-e121c001-zhrt Ready <none> 29m v1.16.9-gke.2
gke-regional-demo-default-pool-e121c001-zpv4 Ready <none> 29m v1.16.9-gke.2
$ kubectl get nodes -l failure-domain.beta.kubernetes.io/zone=us-east1-d
NAME STATUS ROLES AGE VERSION
gke-regional-demo-default-pool-fb3e6608-0lx2 Ready <none> 29m v1.16.9-gke.2
gke-regional-demo-default-pool-fb3e6608-0rcc Ready <none> 29m v1.16.9-gke.2
gke-regional-demo-default-pool-fb3e6608-2qsk Ready <none> 29m v1.16.9-gke.2
Deploying Spring Cloud Data Flow
이제 region 하나에 속한 3개의 zone에 걸쳐있는 멀티 노드 클러스터가 모두 준비됐다. 각 zone에는 워커 노드가 3개씩 떠 있다.
Spring Cloud Data Flow는 Data Flow, Skipper, 서비스 의존성들(ex. 데이터베이스와 메세징 미들웨어)을 배포하기 위한 매니페스트 파일을 제공한다. 이 파일들은 Spring Cloud Data Flow 깃 레포지토리의 src/kubernetes 디렉토리에서 확인할 수 있다.
관련 파일들을 그대로 적용해서 쿠버네티스가 앱들을 예약할 위치를 알아서 처리하도록 해도 되지만, 표준 쿠버네티스 구성을 이용해서 이 애플리케이션들을 배포할 위치나 인스턴스 수 등을 조정할 수도 있다.
이 레시피에선 아래 유스 케이스를 구현해서 배포해본다:
- Skipper는 3개의 레플리카를 배포해야 하며, zone당 레플리카 하나씩이다.
- Data Flow는 3개의 레플리카를 배포해야 하며, zone당 레플리카 하나씩이고, Skipper와 같은 노드에 배치한다.
- 데이터베이스엔 MySQL을 사용하며, 특정 zone 하나에 배치한다.
- 메세징 미들웨어엔 RabbitMQ를 사용하며, 특정 zone 하나에 배치한다.
Deploying MySQL
이 레시피에선 단일 zone에 MySQL 인스턴스를 배포한다. 고가용성과 관련해서는 MySQL 제품의 문서를 읽어봐라. zone에 장애가 발생하면 MySQL을 사용하지 못할 수 있다. HAhigh availability를 위한 MySQL 설정은 SCDF와 이 레시피의 범위를 벗어난다.
MySQL은 레플리카 하나를 구성해서 배포한다. MySQL은 영구 스토리지를 사용하며, 이 스토리지는 regional 클러스터의 영구 스토리지에서 설명하는 규칙에 따라 생성하고 접근한다. StorageClass를 정의해서 스토리지를 생성할 특정 zone을 지정하지 않았다면, GKE가 임의로 zone을 선택한다. StorageClass를 커스텀했다면 MySQL의 PVC 설정에서 참조를 걸어주면 된다.
여기서는 단순히 GKE가 디폴트 StorageClass를 자동으로 생성하게 놔둔다. 프로비저닝된 디스크를 참조하는 모든 포드는 디스크를 프로비저닝한 zone과 동일한 zone에서 자동으로 예약된다. 각 zone에는 노드가 3개씩 있으므로, 노드가 실패하면 MySQL 포드는 해당 zone에 있는 다른 노드로 다시 예약된다.
매니페스트들을 배포해라:
$ kubectl create -f mysql/
deployment.apps/mysql created
persistentvolumeclaim/mysql created
secret/mysql created
service/mysql created
볼륨 이름을 조회해봐라:
$ kubectl get pvc/mysql
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql Bound pvc-24f2acb5-17cd-45e1-8064-34bf602e408f 8Gi RWO standard 3m1s
이 볼륨이 위치한 zone을 확인해보자:
$ kubectl get pv/pvc-24f2acb5-17cd-45e1-8064-34bf602e408f -o jsonpath='{.metadata.labels.failure-domain\.beta\.kubernetes\.io/zone}'
us-east1-d
MySQL 포드가 실행 중인지, 어떤 노드에 할당됐는지 확인해보자:
$ kubectl get pod/mysql-b94654bd4-9zpt2 -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName
NAME STATUS NODE
mysql-b94654bd4-9zpt2 Running gke-regional-demo-default-pool-fb3e6608-0rcc
마지막으로 이 노드가 속해있는 zone을 확인해보자:
$ kubectl get node gke-regional-demo-default-pool-fb3e6608-0rcc -o jsonpath='{.metadata.labels.failure-domain\.beta\.kubernetes\.io/zone}'
us-east1-d
Deploying RabbitMQ
이 레시피에선 단일 zone에 RabbitMQ 인스턴스를 배포한다. 고가용성과 관련해서는 RabbitMQ 제품의 문서를 읽어봐라. zone에 장애가 발생하면 RabbitMQ를 사용하지 못할 수 있다. HAhigh availability를 위한 RabbitMQ 설정은 SCDF와 이 레시피의 범위를 벗어난다.
RabbitMQ는 레플리카 하나를 구성해서 배포한다. 기본 제공하는 매니페스트는 MySQL과 같은 영구 저장소를 구성하지 않는다. RabbitMQ를 원하는 zone에 배치하려면 간단히 nodeSelector를 사용하면 된다.
포드가 예약되는 노드 자체는 관심사가 아닐 거다. 포드를 단지 특정한 zone에만 배치하겠다는 뜻이다. 클러스터에 있는 모든 노드엔 자동으로 레이블들이 할당된다. 이 레이블을 통해 포드가 예약된 노드가 어떤 zone에 속해있는지 확인할 수 있다.
RabbitMQ를 us-east1-b zone에 있는 노드에 배치하려면, rabbitmq/rabbitmq-deployment.yaml 파일을 다음과 같이 수정해라:
spec:
nodeSelector:
failure-domain.beta.kubernetes.io/zone: us-east1-b
매니페스트들을 배포해라:
$ kubectl create -f rabbitmq/
deployment.apps/rabbitmq created
service/rabbitmq created
포드가 배포된 노드를 조회해보자:
$ kubectl get pod/rabbitmq-6d65f675d9-4vksj -o jsonpath='{.spec.nodeName}'
gke-regional-demo-default-pool-ea10f422-5f72
이 노드가 속해있는 zone을 확인해보자:
$ kubectl get node gke-regional-demo-default-pool-ea10f422-5f72 -o jsonpath='{.metadata.labels.failure-domain\.beta\.kubernetes\.io/zone}'
us-east1-b
Deploying Skipper
Skipper는 레플리카 3개를 구성해서 배포한다. 영구 저장소는 필요하지 않으며, 레플리카는 각 zone에 나눠 실행해보려 한다. 레플리카 여러 개가 같은 zone에 중복되면 안 된다. 이때 가능한 한 가지 방법은, pod anti-affinity를 이용하는 거다.
skipper/skipper-deployment.yaml 파일을 다음과 같이 수정해서 레플리카 수를 늘리고 포드 anti-affinity를 추가해라:
spec:
replicas: 3
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- skipper
topologyKey: failure-domain.beta.kubernetes.io/zone
매니페스트들을 배포해라:
$ kubectl create -f server/server-roles.yaml
$ kubectl create -f server/server-rolebinding.yaml
$ kubectl create -f server/service-account.yaml
$ kubectl create -f skipper/skipper-config-rabbit.yaml
$ kubectl create -f skipper/skipper-deployment.yaml
$ kubectl create -f skipper/skipper-svc.yaml
포드들이 배포된 노드를 조회해보자:
$ kubectl get pods -l app=skipper -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName
NAME STATUS NODE
skipper-6fd7bb796c-flm44 Running gke-regional-demo-default-pool-e121c001-zhrt
skipper-6fd7bb796c-l99dj Running gke-regional-demo-default-pool-ea10f422-5f72
skipper-6fd7bb796c-vrf9m Running gke-regional-demo-default-pool-fb3e6608-0lx2
이 노드들이 속해있는 zone을 확인해보자:
$ kubectl get node gke-regional-demo-default-pool-e121c001-zhrt -o jsonpath='{.metadata.labels.failure-domain\.beta\.kubernetes\.io/zone}'
us-east1-c
$ kubectl get node gke-regional-demo-default-pool-ea10f422-5f72 -o jsonpath='{.metadata.labels.failure-domain\.beta\.kubernetes\.io/zone}'
us-east1-b
$ kubectl get node gke-regional-demo-default-pool-fb3e6608-0lx2 -o jsonpath='{.metadata.labels.failure-domain\.beta\.kubernetes\.io/zone}'
us-east1-d
Deploying Data Flow
Data Flow는 레플리카 3개를 구성해서 배포한다. 영구 저장소는 필요하지 않으며, 레플리카는 각 zone에 나눠 실행해보려 한다. 레플리카 여러 개가 같은 zone에 중복되면 안 된다. 더불어서 Data Flow는 Skipper를 자주 호출하므로, 각 zone에선 동일한 노드에 같이 배치하려고 한다. 이때 가능한 한 가지 방법은, pod affinity를 이용하는 거다.
server/server-deployment.yaml 파일을 다음과 같이 수정해서 레플리카 수를 늘리고 포드 affinity를 추가해라:
spec:
replicas: 3
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- skipper
topologyKey: kubernetes.io/hostname
매니페스트들을 배포해라:
$ kubectl create -f server/server-config.yaml
$ kubectl create -f server/server-svc.yaml
$ kubectl create -f server/server-deployment.yaml
포드들이 배포된 노드를 조회해보자:
$ kubectl get pods -l app=scdf-server -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName
NAME STATUS NODE
scdf-server-5ddf7bbd4f-dpnmm Running gke-regional-demo-default-pool-fb3e6608-0lx2
scdf-server-5ddf7bbd4f-hlf9h Running gke-regional-demo-default-pool-e121c001-zhrt
scdf-server-5ddf7bbd4f-vnjh6 Running gke-regional-demo-default-pool-ea10f422-5f72
이 포드들이 Skipper와 같은 노드에 배포됐는지 확인해보자:
$ kubectl get pods -l app=skipper -o=custom-columns=NAME:.metadata.name,STATUS:.status.phase,NODE:.spec.nodeName
NAME STATUS NODE
skipper-6fd7bb796c-flm44 Running gke-regional-demo-default-pool-e121c001-zhrt
skipper-6fd7bb796c-l99dj Running gke-regional-demo-default-pool-ea10f422-5f72
skipper-6fd7bb796c-vrf9m Running gke-regional-demo-default-pool-fb3e6608-0lx2
Data Flow에 잘 연결되는지 확인해보자:
$ SCDF_IP=$(kubectl get svc/scdf-server -o jsonpath='{.status.loadBalancer.ingress[*].ip}')
$ curl -s http://$SCDF_IP/about | jq
{
"featureInfo": {
"analyticsEnabled": true,
"streamsEnabled": true,
"tasksEnabled": true,
"schedulesEnabled": true,
"grafanaEnabled": true
},
"versionInfo": {
"implementation": {
"name": "spring-cloud-dataflow-server",
"version": "2.7.0-SNAPSHOT"
},
...
...
...
Deploying Streams and Tasks
서버를 배포할 때와 마찬가지로, Data Flow를 통해 스트림과 태스크를 배포할 때도 다양한 배치 옵션을 활용할 수 있다. 스트림이나 태스크에 따라, 특정한 zone이나 심지어 특정 노드에만 배포해야 하는 상황이 생기기도 한다. 배포할 스트림과 태스크도 결국 애플리케이션이므로, 마찬가지로 장애가 발생하면 쿠버네티스가 다른 노드로 다시 예약해줄 거다.
쿠버네티스에 스트림과 태스크를 배포할 땐 관련 기능들을 YAML 매니페스트에 명시하는 게 아니라 Data Flow와 Skipper를 이용하므로, 배포 옵션은 depolyer 프로퍼티를 통해 설정한다. 지원하는 전체 deployer 프로퍼티 목록은 Spring Cloud Data Flow 레퍼런스 매뉴얼에 있는 Deployer 프로퍼티 섹션을 참고해라.
아래 있는 depolyer 프로퍼티들을 중심으로 살펴보면 된다:
Node selector:
deployment.nodeSelector
Tolerations:
tolerations.keytolerations.effecttolerations.operatortolerations.tolerationSecondstolerations.value
Node Affinity:
affinity.nodeAffinity
Pod Affinity:
affinity.podAffinity
Pod Anti-Affinity:
affinity.podAntiAffinity
배포 프로퍼티들을 애플리케이션 수준이나 서버 수준으로 설정하는 구체적인 예시는 레퍼런스 매뉴얼의 Tolerations 섹션을 참고해라. 사용할 프로퍼티 이름이나 값이 다르더라도, 같은 패턴으로 적용하면 된다.
Conclusion
이 레시피에선 GKE에 regional 클러스터를 세팅해보고, 해당 region에 속해있는 여러 zone에 걸쳐 고가용성 컨트롤 영역control plane과 워커들을 구성해봤다. node selector, pod affinity, pod anti-affinity같은 구성을 이용해 다양하게 애플리케이션을 배치할 수 있는 옵션들도 탐구해봤다. 사용하는 애플리케이션과 환경에 따라 각자의 요구 사항은 다르겠지만, 이 레시피를 기점으로 표준 쿠버네티스 구성을 이용해서 Data Flow를 운영하는 방법을 익힐 수 있었을 거다.
Next : Resources
Resources
Spring Cloud Data Flow 자료 모음집
전체 목차는 여기에 있습니다.