스프링 클라우드 데이터 플로우 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
이 섹션에선 예제 코드를 통해, 파이썬 스크립트를 Data Flow 스트림의 프로세서로 실행하는 방법을 보여준다.
이 가이드에선 파이썬 스크립트를 도커 이미지로 패키징하고 쿠버네티스에 배포한다. 메세징 미들웨어는 아파치 카프카를 사용한다. Data Flow에 도커 이미지를 등록할 땐 Processor 타입 애플리케이션으로 등록한다.
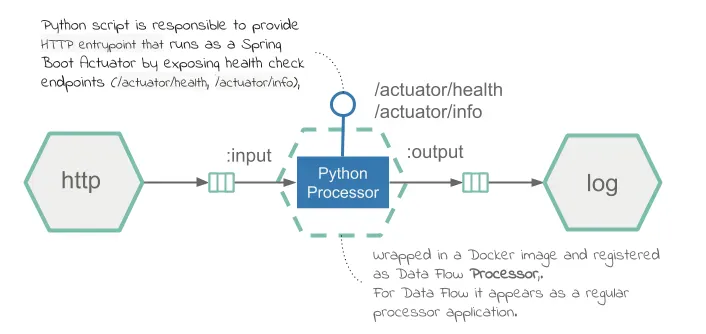
이 가이드에선 텍스트를 처리하는 스트리밍 데이터 파이프라인을 만들어볼 거다. HTTP를 통해 텍스트 메세지를 받으면, Data Flow 프로세서로 등록한 파이썬 스크립트에 텍스트 처리를 위임하고, 그 결과를 로그로 출력한다. 파이썬 스크립트는 reversestring 프로퍼티를 true로 설정했을 땐 입력 텍스트를 반전시킨다. 그 외는 입력 텍스트를 변경하지 않고 그대로 출력한다.
다음은 이 text-reversing 파이프라인의 다이어그램이다:
목차
Development
소스 코드는 샘플 깃허브 레포지토리에서 확인할 수 있으며, polyglot-python-processor.zip을 클릭하면 압축된 아카이브 파일을 다운받을 수 있다.
이 프로세서는 kafka-python 라이브러리를 사용해 컨슈머와 프로듀서 커넥션을 생성한다.
주요 실행 루프는 python_processor.py 안에 들어 있다. 이 스크립트는 인바운드 카프카 토픽에서 메세지를 받아 출력을 카프카 토픽에 전송한다. 출력 값은 입력 값을 그대로 보내거나, 스트림 정의로 --reversestring=true를 전달했을 땐 문자열을 반전해서 보낸다. 다음은 python_processor.py 코드다:
#!/usr/bin/env python
import os
import sys
from kafka import KafkaConsumer, KafkaProducer
from util.http_status_server import HttpHealthServer
from util.task_args import get_kafka_binder_brokers, get_input_channel, get_output_channel, get_reverse_string
consumer = KafkaConsumer(get_input_channel(), bootstrap_servers=[get_kafka_binder_brokers()])
producer = KafkaProducer(bootstrap_servers=[get_kafka_binder_brokers()])
HttpHealthServer.run_thread()
while True:
for message in consumer:
output_message = message.value
reverse_string = get_reverse_string()
if reverse_string is not None and reverse_string.lower() == "true":
output_message = "".join(reversed(message.value))
producer.send(get_output_channel(), output_message)
유틸리티 파일 task_args.py에는 헬퍼 메소드들이 정의돼 있다. 여기서는 공통 환경 변수와 커맨드라인 인자를 추출하는 일을 도와준다.
HTTPServer 구현체에선 스프링 부트 헬스 체크 엔드포인트(/actuator/health, /actuator/info)에 응답을 보내는 스레드를 실행하며, 항상 디폴트로 HTTP 200을 반환한다. Dockerfile은 이미지를 생성한다.
python_processor.py를 Data Flow processor로 동작시키려면, 도커 이미지에 번들링해서 DockerHub에 업로드해야 한다. 아래 Dockerfile은 파이썬 스크립트를 도커 이미지로 번들링하는 방법을 보여준다:
FROM springcloud/openjdk:latest
RUN apt-get update && apt-get install --no-install-recommends -y \
python-pip \
&& rm -rf /var/lib/apt/lists/*
RUN pip install kafka-python
COPY python_processor.py /processor/
COPY util/*.py /processor/util/
ENTRYPOINT ["python", "/processor/python_processor.py", "$@", "--"]
이 Dockerfile에선 필수 의존성을 설치하고, python_processor.py 스크립트와 유틸리티(util 폴더 아래에 있는 스크립트)를 추가하고, 커맨드 항목을 설정한다.
Build
이제 도커 이미지를 빌드하고 도커허브 레지스트리에 푸시하면 된다. 그러려면:
-
샘플 프로젝트를 체크아웃 받고
polyglot-python-processor폴더로 이동한다:git clone https://github.com/spring-cloud/spring-cloud-dataflow-samples cd ./spring-cloud-dataflow-samples/dataflow-website/recipes/polyglot/polyglot-python-processor/ -
polyglot-python-processor/안에서polyglot-python-processor도커 이미지를 빌드하고 도커허브에 푸시한다:docker build -t springcloud/polyglot-python-processor:0.1 . docker push springcloud/polyglot-python-processor:0.1springcloud는 각자 환경에 맞는 도커허브 프리픽스로 변경해라.
도커허브에 올라가고 나면, Data Flow에서 이미지를 등록하고 배포할 수 있다.
Deployment
프로세서를 배포하려면:
-
설치 가이드에 따라 쿠버네티스 환경에 Data Flow를 세팅한다.
-
Minikube에서 아래 명령어를 실행해 Data Flow URL을 가져온다:
minikube service --url scdf-server -
아래 명령어를 실행해서 Data Flow 쉘을 세팅한다:
dataflow config server --uri <Your Data Flow URL> -
SCDF 앱 스타터들을 임포트한다
app import --uri https://dataflow.spring.io/kafka-docker-latest -
polyglot-python-processor이미지를python-processor라는 이름을 사용해processor타입으로 등록한다.app register --type processor --name python-processor --uri docker://springcloud/polyglot-python-processor:0.1docker://springcloud/polyglot-python-processor:0.1은 도커허브 레포지토리에서 리졸브된다. -
아래 명령어를 실행해 Data Flow 스트림
text-reversal을 생성한다:stream create --name text-reversal --definition "http --server.port=32123 | python-processor --reversestring=true | log"http소스는32123포트에서 HTTP 메세지를 수신listen하고python-processor로 전달한다. 프로세서는 입력 메세지를 반전시키고 (reversestring=true면) 다운스트림에 있는log싱크로 전송한다. -
HTTP 포트를 로컬 호스트에 노출시키는
kubernetes.createNodePort프로퍼티를 사용해서 스트림을 배포한다:stream deploy text-reversal --properties "deployer.http.kubernetes.createNodePort=32123" -
minikube에서 다음 명령어를 실행해 테스트 데이터를 게시해볼
http-sourceURL을 조회한다:minikube service --url text-reversal-http-v1 http://192.168.99.104:32123 -
다음 명령어를 실행해
http-source애플리케이션에 샘플 메세지를 게시한다:http post --target http://192.168.99.104:32123 --data "hello world"메세지 게시에 성공하면 아래와 같은 확인 메세지를 볼 수 있을 거다:
> POST (text/plain) http://192.168.99.104:32123 hello world > 202 ACCEPTED -
다음 명령어를 실행해 전송했던 메세지 로그를 찾아봐라
kubectl logs -f <log pod name>다음과 유사한 로그가 출력된 것을 볼 수 있을 거다:
INFO 1 --- [container-0-C-1] log-sink : dlrow olleh게시한 메세지가 역순으로 출력됐을 거다 (이 경우엔
dlrow olleh).
Next : Create and Deploy a Python Task
Create and Deploy a Python Task
파이썬 스크립트로 만든 태스크를 Data Flow로 실행하기
전체 목차는 여기에 있습니다.