스프링 인티그레이션 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
이번 챕터에선 Spring Integration의 핵심 개념과 구성 요소들을 개괄적으로 알아본다. Spring Integration을 최대한 활용하기 위한 몇 가지 프로그래밍 팁도 포함하고 있다.
목차
- 5.1. Background
- 5.2. Goals and Principles
- 5.3. Main Components
- 5.4. Message Endpoints
- 5.5. Configuration and @EnableIntegration
- 5.6. Programming Considerations
- 5.7. Programming Tips and Tricks
- 5.8. POJO Method invocation
5.1. Background
스프링 프레임워크에서 다루는 핵심 주제 중 하나는 제어의 역전, 즉 IOCInversion of Control다. IOC는 가장 넓게 해석하면 컨텍스트 내에서 관리하는 컴포넌트들을 대신해 프레임워크가 책임 요소들을 관리해준다는 거다. 컴포넌트 자체에선 책임이 사라지기 때문에 단순해지는 효과를 볼 수 있다. 예를 들어 의존성 주입dependency injection은 컴포넌트가 가진 의존성들을 찾거나 생성하는 책임을 덜어준다. 마찬가지로, 관점 지향 프로그래밍aspect-oriented programming은 비즈니스 컴포넌트들을 재사용할 수 있는 aspect로 모듈화하는 식으로 비즈니스 컴포넌트들로부터 전반적인 횡단 관심사cross-cutting concern를 분리해준다. 두 케이스 모두 결과적으로 테스트하기도, 이해하기도, 관리하기도, 확장하기도 더 쉬운 시스템이 만들어진다.
더불어 스프링 프레임워크와 포트폴리오에선 엔터프라이즈 애플리케이션 구축을 위한 포괄적인 프로그래밍 모델을 제공한다. 개발자는 이 모델을 통해 일관성을 지킬 수 있는데, 특히 인터페이스 기반으로 프로그래밍하고 상속보다 컴포지션composition over inheritance을 선호하는 등, 잘 확립된 베스트 프랙티스를 기반으로 구성한 모델이라는 점에서 더 그러하다. 스프링이 단순화해 놓은 추상화와 강력한 지원 라이브러리 덕분에 더 쉽게 테스트가 가능하며, 이식성이 한 단계 더 올라가고, 동시에 개발자의 생산성 또한 높일 수 있다.
Spring Integration이 가지고 있는 목표와 원칙도 동일하다. Spring Integration은 스프링의 프로그래밍 모델을 메시지 처리 도메인으로 확장하며, 스프링의 기존 엔터프라이즈 통합 지원을 기반으로 한 층 더 추상화시켰다. 메시지 기반 아키텍처를 지원하며, 여기서는 특정 비즈니스 로직을 언제 실행해야 하는지와, 응답을 어디로 보내야 하는지와 같은 런타임 관심사에 제어의 역전inversion of control을 적용한다. 메시지 라우팅과 변환을 지원하기 때문에 다양한 전송 방식과 다양한 데이터 형식을 통합할 수 있으며, 그렇다고 테스트 난이도가 올라가지 않는다. 다시 말해, 메시지 처리와 통합이라는 관심사는 프레임워크에서 처리해준다. 비즈니스 컴포넌트들은 인프라에서 더욱 격리되며, 개발자는 복잡한 통합이라는 책임에서 벗어날 수 있다.
Spring Integration은 스프링의 프로그래밍 모델을 확장하기 때문에 다양한 방법으로 설정을 추가할 수 있다. 어노테이션을 지원하며, XML에선 네임스페이스 지원이나 일반적인 “bean” 요소를 사용할 수 있고, 내부 API를 직접 사용하는 것도 가능하다. 내부 API는 잘 정의돼 있는 전략 인터페이스와 비침투적인non-invasive 위임delegating 어댑터에 기초한다. Spring Integration의 설계는 스프링 내에서 흔히 쓰는 패턴들과 Enterprise Integration Patterns에서 Gregor Hohpe & Bobby Woolf (Addison Wesley, 2004)가 설명하는 유명 패턴들 사이 깊은 연관이 있다는 인식에서 고무됐다. 이 책을 읽어본 개발자라면 Spring Integration의 개념과 용어에 금방 익숙해질 거다.
5.2. Goals and Principles
Spring Integration을 만들게 된 목표는 다음과 같다:
- 복잡한 엔터프라이즈 통합 솔루션을 구현할 수 있는 단순한 모델을 제공한다.
- 스프링 기반 애플리케이션 내에서 메시지 기반 비동기 로직을 쉽게 구성할 수 있도록 지원한다.
- 기존 스프링 사용자가 큰 어려움 없이 조금씩 넘어올 수 있게 돕는다.
Spring Integration을 이끄는 원칙들은 다음과 같다:
- 구성 요소들은 모듈화나 테스트를 위해 느슨하게 결합loosely coupled해야 한다.
- 프레임워크는 비즈니스 로직과 통합 로직 간의 관심사를 분리해줘야 한다.
- 확장 포인트는 재사용과 이식성을 위해 완전히 추상화돼 있어야 한다 (단, 명확한 경계 내에서).
5.3. Main Components
계층 구조는 수직적인 관점에서 쉽게 관심사를 분리할 수 있게 해주며, 계층마다 인터페이스 기반으로 역할을 분리해 느슨한 결합loose coupling으로 이끌어준다. 전형적인 스프링 기반 애플리케이션들은 보통 계층 구조로 설계하며, 스프링 프레임워크와 포트폴리오는 엔터프라이즈 애플리케이션이 전체 스택에 걸쳐 이러한 베스트 프랙티스를 따를 수 있게끔 강력한 기반이 되어 준다. 메시지 기반 아키텍처는 수평적 관점을 더하긴 하지만, 그럼에도 이 목표들은 여전히 유효하다. “계층화된 아키텍처”가 극히 일반적이고 추상적인 패러다임이듯이, 메시지 처리 시스템에서도 보통 유사하게 추상적인 “파이프 필터pipes-and-filters” 모델을 따른다. “필터”는 메시지를 생산하거나 컨슘할 수 있는 모든 구성 요소를 나타내며, 이 구성 요소들 끼리는 느슨하게 결합된 상태로 유지할 수 있도록 “파이프”가 필터 간에 메시지를 전송해준다. 이 두 종류의 고수준 패러다임이 상호 배타적이지 않다는 것을 이해하는 것도 중요하다. “파이프”를 지원하는 내부 메시지 처리 인프라는 여전히 역할을 인터페이스로 정의하고, 하나의 계층으로 캡슐화되어야 한다. 마찬가지로 “필터” 자체는 논리적으로 애플리케이션의 서비스 계층 위에 있는 하나의 계층 내에서 관리돼야 하며, 웹 티어와 거의 동일하게 인터페이스를 통해 관련 서비스들과 상호 작용한다.
5.3.1. Message
Spring Integration에서 메시지는 어떠한 자바 객체와, 프레임워크에서 이 객체를 처리하는 동안 사용하는 메타데이터를 함께 감싼 범용 래퍼wrapper를 뜻한다. 메시지는 페이로드와 여러 가지 헤더로 구성된다. 페이로드는 어떤 타입이든지 될 수 있으며, 헤더는 ID, 타임스탬프, correlation ID, 반환 주소같이 흔히 필요한 정보들을 담고 있다. 헤더는 연결돼 있는 전송 구성 요소 간에 값을 주고받을 때에도 활용한다. 예를 들어, 수신한 파일로부터 메시지를 생성할 때는 다운스트림 구성 요소가 참고할 수 있도록 헤더에 파일 이름을 저장할 수 있다. 마찬가지로 마지막엔 아웃바운드 메일 어댑터가 메시지 컨텐츠를 전송한다면, 업스트림에 있는 구성 요소가 다양한 프로퍼티(to, from, cc, subject 등등)들을 메시지 헤더 값으로 설정할 수 있다. 헤더에 개발자가 원하는 임의의 키-값 쌍을 저장하는 것도 가능하다.
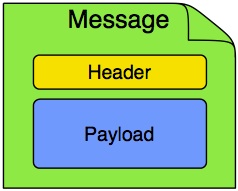
Figure 1. Message
5.3.2. Message Channel
메시지 채널은 파이프 필터pipes-and-filters 아키텍처에서 말하는 “파이프”를 나타낸다. 프로듀서는 채널에 메시지를 전송하며, 컨슈머는 채널에서 메시지를 받아간다. 따라서 메시지 채널은 메시지를 처리하는 구성 요소들을 분리시켜준다고 할 수 있으며, 쉽게 메시지를 가로채거나interception 모니터링할 수 있는 포인트를 마련해준다.

Figure 2. Message Channel
메시지 채널은 point-to-point나 publish-subscribe 시맨틱스를 따를 수 있다. point-to-point 채널을 사용하면 특정 채널로 전송한 모든 메시지는 딱 하나의 컨슈머만 받아갈 수 있다. 반면 publish-subscribe 채널은 각 메시지를 해당 채널의 모든 구독자에게 브로드캐스트한다. Spring Integration은 이 두 가지 모델을 모두 지원한다.
“point-to-point”와 “publish-subscribe” 중 어떤 것을 사용하느냐에 따라 각 메시지를 최종적으로 수신하는 컨슈머 수가 달라진다고 볼 수 있는데, 그 외에도 한 가지를 더 고려해봐야 한다. 채널에서 메시지를 버퍼링해야 할까? Spring Integration에선 pollable 채널이 큐 안에 메시지를 버퍼링할 수 있다. 버퍼링을 이용하면 인바운드 메시지들을 스로틀링throttling해서 컨슈머를 과부하로부터 지켜줄 수 있다는 장점이 있다. 하지만 이름에서 알 수 있듯이 채널에 poller를 설정해야만 컨슈머가 메시지를 받을 수 있기 때문에 복잡성이 추가된다. 반면에 subscribable 채널에 연결된 컨슈머는 단순히 메시지를 기반으로 움직인다. Spring Integration에서 사용할 수 있는 다양한 채널 구현체들은 메시지 채널 구현체에서 상세히 논하고 있다.
5.3.3. Message Endpoint
Spring Integration의 주요 목표 중 하나는 제어의 역전inversion of control을 통해 엔터프라이즈 통합 솔루션 개발을 단순하게 만들어주는 일이다. 즉, 사용자는 컨슈머와 프로듀서를 직접 구현할 필요가 없으며, 메시지를 만들거나 메시지 채널에서 send/receive 연산을 호출할 필요조차 없다는 의미다. 대신 순수 객체를 기반으로 구현을 이어가고, 가지고 있는 도메인 모델에 집중할 수 있어야 한다. 그러고 나서 설정을 선언해 줌으로써 도메인 관련 코드를 Spring Integration에서 제공하는 메시지 처리 인프라에 “연결”해주면 된다. 이 연결을 담당하는 구성 요소가 바로 메시지 엔드포인트다. 그렇다고 해서 반드시 기존 애플리케이션 코드 안에 직접 연결 정보를 넣어야 한다는 것은 아니다. 현존하는 모든 엔터프라이즈 통합 솔루션은 라우팅과 변환같은 통합 관심사를 위한 코드를 약간씩 요구한다. 중요한 건 통합 로직과 비즈니스 로직 간의 관심사를 분리시키는 거다. 다시 말해, 웹 애플리케이션을 위한 MVCModel-View-Controller 패러다임에서 그러했듯, 인바운드 요청을 서비스 레이어 호출로 옮겨온 다음 서비스 레이어가 반환한 값을 아웃바운드 응답으로 변환하는, 얇으면서도 맡은 책임을 이행하는 전용 레이어를 만드는 것을 목표로 삼아야 한다. 이어지는 섹션에선 이러한 역할을 담당하는 메시지 엔드포인트 유형을 간략하게 살펴본다. Spring Integration이 선언된 설정을 통해 어떻게 각 엔드포인트 유형을 비침투적으로non-invasive 사용할 수 있게 해주는지는 이후 나오는 챕터에서 확인할 수 있다.
5.4. Message Endpoints
메시지 엔드포인트는 파이프 필터pipes-and-filters 아키텍처에서 말하는 “필터”를 나타낸다. 앞에서 언급했듯이 엔드포인트가 담당하는 일차적인 역할은 애플리케이션 코드를 메시지 처리 프레임워크에 비침투적인non-invasive 방식으로 연결해주는 일이다. 다른 말로 하면 이상적으로는 애플리케이션 코드에선 메시지 객체나 메시지 채널을 알지 못해야 한다는 뜻이다. MVC 패러다임에서의 컨트롤러 역할과 유사하다고 볼 수 있다. 컨트롤러가 HTTP 요청을 처리하듯, 메시지 엔드포인트는 메시지를 처리한다. 컨트롤러가 URL 패턴에 매핑되듯, 메시지 엔드포인트는 메시지 채널에 매핑된다. 두 케이스 모두 목표는 인프라에서 애플리케이션 코드를 격리시키는 거다. 관련한 개념과 모든 패턴들은 Enterprise Integration Patterns라는 책에서 자세히 논하고 있다. 여기서는 Spring Integration에서 지원하는 주요 엔드포인트 유형과 각각의 역할을 간략히만 알아본다. 다음 챕터에서 좀 더 자세히 설명하며, 설정 예제와 샘플 코드를 함께 확인해볼 수 있다.
5.4.1. Message Transformer
메시지 트랜스포머는 메시지의 내용이나 구조를 변환하고, 수정을 마친 메시지를 반환하는 일을 담당한다. 예상컨데 가장 많이 쓰는 트랜스포머 유형은 메시지 페이로드를 특정 포맷에서 다른 포맷으로 변환하는 유형일 거다 (XML에서 java.lang.String으로 변환하는 등). 유사하게 메시지의 헤더 값을 추가하거나, 제거, 수정하는 트랜스포머도 있다.
5.4.2. Message Filter
메시지 필터는 메시지를 출력 채널로 전달할지 말지를 결정한다. 필터에선 간단히 boolean 테스트 메소드가 하나 있으면 된다. 이 메소드에선 특정 페이로드 컨텐츠 타입, 프로퍼티 값, 헤더의 존재 여부 등의 조건을 검사할 수 있다. 메시지를 받아들이면 출력 채널로 전송하고, 그 외에엔 메시지를 버린다 (좀 더 엄격하게 구현할 때는 Exception을 던지기도 한다). 메시지 필터는 보통 같은 메시지를 여러 컨슈머가 수신할 수 있는 publish-subscribe 채널과 함께 사용해서, 필터 기준을 이용해 처리할 메시지 셋을 조금씩 줄여나가는 식으로 활용하곤 한다.
여기서 설명한 필터는 채널 사이 흘려보낼 메시지를 선별해서 좁혀나가는 엔드포인트 유형이다. 아키텍처 패턴 파이프 필터pipes-and-filters에서 흔히 말하는 “필터”와 헷갈리면 안 된다. 파이프 필터pipes-and-filters에서 나오는 “필터”의 개념은 Spring Integration의 메시지 엔드포인트에 더 가깝다. 메시지 엔드포인트는 메시지 채널에 연결해 메시지를 보내거나 받는 모든 구성 요소를 뜻한다.
5.4.3. Message Router
메시지 라우터는 이어서 메시지를 수신할 채널들(있다면)을 결정하는 일을 담당한다. 보통은 메시지 내용이나 메시지 헤더에 있는 메타데이터를 기반으로 결정한다. 서비스 액티베이터service activator나 응답 메시지를 보낼 수 있는 기타 다른 엔드포인트에서 출력 채널을 정적으로 설정할 수 있다면, 메시지 라우터는 동적으로 설정하는 식으로 자주 활용한다. 마찬가지로, 앞에서 설명한 것처럼 메시지 필터는 여러 구독자에 대응하기 위해 메시지를 필터링한다면, 메시지 라우터는 사전에 메시지를 전송할 채널을 결정할 수 있다.
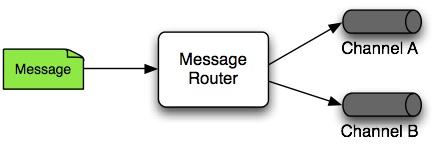
Figure 3. Message Router
5.4.4. Splitter
스플리터splitter 역시 엔드포인트 타입 중 하나로, 입력 채널에서 받은 메시지를 여러 메시지로 분할하고 각자의 출력 채널로 전송하는 일을 담당하고 있다. 보통은 “복합composite” 페이로드 객체를, 세분화한 페이로드를 담고 있는 여러 메시지로 나누는 데 사용한다.
5.4.5. Aggregator
애그리게이터aggregator는 스플리터splitter의 정반대 개념으로, 여러 메시지를 받아 하나의 메시지로 결합하는 메시지 엔드포인트다. 사실 애그리게이터는 파이프라인 앞쪽에 스플리터를 가지고 있는 다운스트림 컨슈머인 경우가 많다. 애그리게이터는 상태를 유지해야 하며 (집계하는 메시지들), 언제 완전한 메시지 그룹이 준비되는지를 판단하고, 필요 시 타임아웃으로 처리해야 하기 때문에 기술적으로 스플리터보다 더 복잡한 편이다. 게다가 타임아웃이 발생했을 땐 불완전한 결과라도 전송할지, 아니면 폐기discard할지, 별도 다른 채널로 전송할지를 애그리게이터가 알고 있어야 한다. Spring Integration은 CorrelationStrategy, ReleaseStrategy를 제공하며, 타임아웃 관련 설정들, 타임아웃 발생 시 불완전한 결과를 전송할지 여부나 discard 채널 등의 설정을 제공한다.
5.4.6. Service Activator
서비스 액티베이터service activator는 서비스 인스턴스를 메시지 시스템에 연결하기 위한 범용 엔드포인트다. 입력 메시지 채널을 반드시 구성해야 하며, 호출할 서비스 메소드가 값을 반환할 수 있는 경우엔 출력 메시지 채널도 지정할 수 있다.
메시지마다 고유 ‘Return Address’ 헤더를 제공할 수도 있기 때문에 출력 채널은 선택 사항이다. 이 규칙은 모든 컨슈머 엔드포인트에 동일하게 적용되는 규칙이다.
서비스 액티베이터는 요청 메시지의 페이로드를 추출하고 변환해서 (메소드에서 message 타입 파라미터를 받지 않는 경우), 특정 서비스 객체를 호출해 요청 메시지를 처리한다. 서비스 객체의 메소드가 값을 반환한다면, 마찬가지로 필요 시엔 (message 타입을 반환하지 않은 경우) 반환 값도 응답 메시지로 변환한다. 이 응답 메시지는 출력 채널로 전송된다. 출력 채널을 설정하지 않았을 땐 메시지에 “return address”가 있다면 이 헤더에 지정한 채널로 응답을 전송한다.
request-reply 서비스 액티베이터는 타겟 객체의 메소드를 입출력 메시지 채널에 연결해준다.
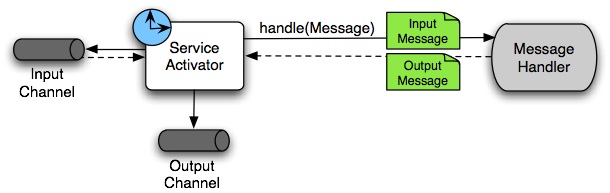
Figure 4. Service Activator
앞서 메시지 채널에서 논의한 바와 같이, 채널은 pollable 채널이거나 subscribable 채널일 수 있다. 위 다이어그램에선 이 사실을 “시계” 기호와 실선 화살표(poll), 점선 화살표(subscribe)로 묘사하고 있다.
5.4.7. Channel Adapter
채널 어댑터는 메시지 채널을 다른 시스템이나 전송 구성 요소에 연결해주는 엔드포인트다. 채널 어댑터는 인바운드와 아웃바운드로 나뉜다. 일반적으로 채널 어댑터는 다른 시스템(파일, HTTP 요청, JMS 메시지 등)과 주고받는 객체 혹은 리소스를 메시지에 매핑한다. 전송 구성 요소에 따라 채널 어댑터는 메시지 헤더에 값을 채우거나 추출하기도 한다. Spring Integration은 다양한 채널 어댑터를 제공하며, 이후 별도 챕터에서 따로 설명한다.

Figure 5. 소스 시스템을 MessageChannel에 연결해주는 인바운드 채널 어댑터 엔드포인트.
메시지 소스는 pollable이거나 (ex. POP3) message-driven일 수 있다 (ex. IMAP Idle). 위 다이어그램에선 이 사실을 “시계” 기호와 실선 화살표(poll), 점선 화살표(message-driven)로 묘사하고 있다.

Figure 6. MessageChannel을 타겟 시스템으로 연결해주는 아웃바운드 채널 어댑터 엔드포인트.
앞서 메시지 채널에서 논의한 바와 같이, 채널은 pollable 채널이거나 subscribable 채널일 수 있다. 위 다이어그램에선 이 사실을 “시계” 기호와 실선 화살표(poll), 점선 화살표(subscribe)로 묘사하고 있다.
5.4.8. Endpoint Bean Names
메시지를 컨슘하는 엔드포인트는 (inputChannel이 있는 엔드포인트) 컨슈머와 메시지 핸들러라는 두 가지 빈으로 구성된다. 컨슈머는 메시지 핸들러에 대한 참조를 가지고 있어서 메시지가 도착하면 핸들러를 호출한다.
아래 있는 XML로 예를 들어보자:
<int:service-activator id = "someService" ... />
위 예제에서 등록되는 빈들의 이름은 다음과 같다:
- 컨슈머:
someService(id) - 핸들러:
someService.handler
EIPEnterprise Integration Pattern 어노테이션을 사용할 땐 여러 가지 요인에 따라 빈 이름이 달라질 수 있다. 아래와 같이 어노테이션을 선언한 POJO를 생각해보자:
@Component
public class SomeComponent {
@ServiceActivator(inputChannel = ...)
public String someMethod(...) {
...
}
}
위 예제에서 등록되는 빈들의 이름은 다음과 같다:
- 컨슈머:
someComponent.someMethod.serviceActivator - 핸들러:
someComponent.someMethod.serviceActivator.handler
5.0.4 버전부터는 아래 예제와 같이 @EndpointId 어노테이션을 이용해 빈 이름을 변경할 수 있다:
@Component
public class SomeComponent {
@EndpointId("someService")
@ServiceActivator(inputChannel = ...)
public String someMethod(...) {
...
}
}
위 예제에서 등록되는 빈들의 이름은 다음과 같다:
- 컨슈머:
someService - 핸들러:
someService.handler
@EndpointId는 XML 설정에서 id 속성으로 이름을 지정하는 것과 동일하다. 아래처럼 어노테이션을 선언한 빈을 생각해보자:
@Configuration
public class SomeConfiguration {
@Bean
@ServiceActivator(inputChannel = ...)
public MessageHandler someHandler() {
...
}
}
위 예제에서 등록되는 빈들의 이름은 다음과 같다:
- 컨슈머:
someConfiguration.someHandler.serviceActivator - 핸들러:
someHandler(@Bean이름)
5.0.4 버전부터는 아래 예제와 같이 @EndpointId 어노테이션을 이용해 빈 이름을 변경할 수 있다:
@Configuration
public class SomeConfiguration {
@Bean("someService.handler") // (1)
@EndpointId("someService") // (2)
@ServiceActivator(inputChannel = ...)
public MessageHandler someHandler() {
...
}
}
(1) 핸들러: someService.handler (빈 이름)
(2) 컨슈머: someService (엔드포인트 ID)
@Bean 이름에 .handler를 붙이는 컨벤션만 지켜준다면 @EndpointId 어노테이션으로 만들어지는 이름도 XML 설정에서의 id 속성으로 생성하는 이름과 동일할 거다.
한 가지 특별한 케이스가 있는데, 이때는 또 다른 빈이 하나 더 생성된다. MessageHandler @Bean으로 정의한 빈이 AbstractReplyProducingMessageHandler가 아니라면 프레임워크는 아키텍처 상의 이유로 설정한 빈을 ReplyProducingMessageHandlerWrapper로 감싼다. 이 래퍼는 request 핸들러 어드바이스를 지원하며, 일반적인 디버그 로그 메시지 ‘produced no reply’를 출력한다. 빈 이름은 핸들러 빈 이름에 .wrapper를 붙여 사용한다 (@EndpointId를 선언했다면 — 그 외엔 일반적으로 생성하는 핸들러 이름을 사용한다).
유사하게 Pollable 메시지 소스는 SourcePollingChannelAdapter(SPCA)와 MessageSource라는 두 가지 빈을 생성한다.
아래 있는 XML로 예를 들어보자:
<int:inbound-channel-adapter id = "someAdapter" ... />
위 XML 설정에서 사용하는 빈들의 이름은 다음과 같다:
- SPCA:
someAdapter(id) - 핸들러:
someAdapter.source
아래와 같이 @EndpointId를 정의하는 POJO 자바 설정을 생각해보자:
@EndpointId("someAdapter")
@InboundChannelAdapter(channel = "channel3", poller = @Poller(fixedDelay = "5000"))
public String pojoSource() {
...
}
위 자바 설정에서 사용하는 빈들의 이름은 다음과 같다:
- SPCA:
someAdapter - 핸들러:
someAdapter.source
아래와 같이 @EndpointId를 정의하는 자바 빈 설정을 생각해보자:
@Bean("someAdapter.source")
@EndpointId("someAdapter")
@InboundChannelAdapter(channel = "channel3", poller = @Poller(fixedDelay = "5000"))
public MessageSource<?> source() {
return () -> {
...
};
}
위 예제에서 등록되는 빈들의 이름은 다음과 같다:
- SPCA:
someAdapter - 핸들러:
someAdapter.source(@Bean이름에.source를 붙이는 컨벤션만 지켜준다면)
5.5. Configuration and @EnableIntegration
XML 네임스페이스를 이용해 Spring Integration 플로우에 필요한 요소를 선언하는 설정은 이 문서 곳곳에서 발견할 수 있다. 네임스페이스는 적당한 빈 정의를 생성해 필요한 구성 요소를 구현하는 일련의 네임스페이스 파서parser를 통해 지원한다. 예를 들면 다양한 엔드포인트들이 MessageHandler 빈과, 이 핸들러와 입력 채널 이름을 주입받는 ConsumerEndpointFactoryBean으로 구성된다.
프레임워크는 Spring Integration 네임스페이스 요소를 처음 맞닥뜨리면 런타임 환경 지원을 위한 여러 가지 빈들을 자동으로 선언한다 (태스크 스케줄러, 내부적으로 필요한 채널 creator 등).
@EnableIntegration어노테이션은 4.0 버전에서 도입했다. 이 어노테이션은 Spring Integration 인프라 빈들의 등록을 활성화하며 (Javadoc 참고), 자바 설정에서만 필요하다. 예를 들어 스프링 부트나 Spring Integration 메시징 어노테이션 지원을 이용하거나, XML 통합 설정 없이 Spring Integration 자바 DSL을 사용할 때가 그렇다.
@EnableIntegration 어노테이션은 Spring Integration 컴포넌트가 없는 부모 컨텍스트와, Spring Integration을 사용하는 둘 이상의 자식 컨텍스트가 있을 때에도 유용하다. 이 어노테이션을 이용하면 관련 공통 컴포넌트들을 부모 컨텍스트에 한 번만 선언할 수 있다.
@EnableIntegration 어노테이션은 다양한 인프라 구성 요소들을 애플리케이션 컨텍스트에 등록한다. 구체적으로는:
errorChannel과 전용LoggingHandler, poller를 위한taskScheduler,jsonPathSpEL-function 등과 같은 몇 가지 내장 빈들을 등록한다.- 글로벌 및 디폴트 통합 환경을 위한
BeanFactory를 확장할 수 있는 여러 가지BeanFactoryPostProcessor인스턴스를 추가한다. - 통합을 목적으로 특정 빈들을 개선하거나 변환, 래핑하기 위한 여러 가지
BeanPostProcessor인스턴스를 추가한다. - 메시징 어노테이션을 파싱하고 애플리케이션 컨텍스트에 관련 컴포넌트들을 등록하기 위한 어노테이션 프로세서들을 추가한다.
@IntegrationComponentScan 어노테이션 덕분에 클래스패스 스캔도 가능하다. 이 어노테이션이 담당하는 일은 스프링 프레임워크의 표준 어노테이션 @ComponentScan과 유사하지만, 표준 스프링 프레임워크 컴포넌트 스캔 메커니즘으로 해결할 수 없는 Spring Integration 전용 구성 요소들과 어노테이션들로 한정된다. 예시로 @MessagingGateway 어노테이션을 참고해라.
@EnablePublisher 어노테이션은 PublisherAnnotationBeanPostProcessor 빈을 등록하며, channel 속성 없이 제공한 @Publisher 어노테이션에 default-publisher-channel을 설정해준다. @EnablePublisher 어노테이션이 둘 이상 발견되는 경우엔 디폴트 채널에 모두 같은 값을 가지고 있어야 한다. 자세한 내용은 @Publisher 어노테이션을 이용한 어노테이션 기반 설정을 참고해라.
@GlobalChannelInterceptor 어노테이션은 글로벌 채널 인터셉션interception을 위한 ChannelInterceptor 빈들을 마킹하기 위해 도입됐다. 이 어노테이션은 XML 요소 <int:channel-interceptor>와 유사하다 (글로벌 채널 인터셉터 설정 참고). @GlobalChannelInterceptor 어노테이션은 클래스 레벨에 두거나 (스테레오타입 어노테이션 @Component와 함께), @Configuration 클래스 안에 있는 @Bean 메소드 위에 선언할 수 있다. 두 경우 모두 빈은 ChannelInterceptor를 구현해야 한다.
5.1 버전부터 동적으로 등록된 채널에도 글로벌 채널 인터셉터가 적용된다 (ex. beanFactory.initializeBean()으로 초기화하거나, 자바 DSL에서 IntegrationFlowContext를 사용해 초기화하는 빈들). 그전에는 애플리케이션 컨텍스트를 리프레시한 이후에 빈을 생성하는 경우엔 인터셉터가 적용되지 않았다.
@IntegrationConverter 어노테이션은 Converter나 GenericConverter, ConverterFactory 빈들을 integrationConversionService의 후보 컨버터로 마킹한다. 이 어노테이션은 XML 요소 <int:converter>와 유사하다 (페이로드 타입 변환 참고). @IntegrationConverter 어노테이션은 클래스 레벨에 두거나 (스테레오타입 어노테이션 @Component와 함께), @Configuration 클래스 안에 있는 @Bean 메소드 위에 선언할 수 있다.
메시징 어노테이션들에 대한 자세한 내용은 어노테이션 지원을 참고해라.
5.6. Programming Considerations
가능하다면 항상 POJOPlain Old Java Objects를 사용하는 것이 좋으며, 코드에 프레임워크를 노출하는 건 다른 선택지가 없을 때만 해야 한다. 자세한 내용은 POJO 메소드 실행을 참고해라.
어쩔 수 없이 어떠한 클래스에 프레임워크를 노출하게 된다면, 특히 애플리케이션 기동 시점과 관련해서 생각해봐야 할 몇 가지 주의 사항이 있다:
- 개발하는 컴포넌트가
ApplicationContextAware일 땐, 일반적으로setApplicationContext()메소드 안에선ApplicationContext를 사용하지 않는 게 좋다. 그대신 참조를 저장하고 , 이를 사용하는 일은 이후 다른 컨텍스트 수명 주기로 연기해라. - 개발하는 컴포넌트가
InitializingBean이거나 혹은@PostConstruct메소드를 사용한다면, 이런 초기화 메소드에서는 메시지를 전송하지 마라. 이런 메소드가 호출될 땐 애플리케이션 컨텍스트가 아직 초기화되지 않은 상태이며, 이때 메시지를 전송하면 실패할 가능성이 크다. 기동 중에 메시지를 전송해야 한다면ApplicationListener를 구현하고ContextRefreshedEvent를 기다려라. 아니면SmartLifecycle을 구현해서 빈을 후반 phase에 두고start()메소드에서 메시지를 전송해라.
5.6.1. Considerations When Using Packaged (for example, Shaded) Jars
Spring Integration은 스프링 프레임워크의 SpringFactories 메커니즘을 이용해 여러 가지 IntegrationConfigurationInitializer 클래스를 로드해서 특정 기능들을 부트스트랩한다. 여기에는 -core jar 뿐만 아니라 -http와 -jmx를 포함한 jar들도 포함된다. 이 프로세스에 대한 정보는 각 jar의 META-INF/spring.factories 파일에 저장된다.
Apache Maven Shade Plugin과 같은 잘 알려진 툴들을 이용해 애플리케이션과 모든 의존성을 하나의 jar로 리패키징하는 것을 선호하는 개발자들도 있다.
shade 플러그인은 기본적으로 shaded jar를 생성할 때 spring.factories 파일을 병합하지 않는다.
XML 설정에는 spring.factories 외에도 다른 META-INF 파일도 함께 사용한다 (spring.handlers, spring.schemas). 이런 파일들도 병합해줄 필요가 있다.
스프링 부트의 executable jar 메커니즘에선 이와는 다르게 접근하는데, jar를 중첩해서 클래스패스에 각
spring.factories파일을 그대로 보존한다. 따라서 스프링 부트 애플리케이션에서 디폴트 executable jar 포맷을 사용한다면 추가 설정은 필요하지 않다.
스프링 부트를 사용하지 않더라도 부트에서 제공하는 툴 기능을 이용해 위에서 언급한 파일들을 위한 transformer를 추가하는 식으로 shade 플러그인을 확장할 수 있다. 다음은 이 플러그인을 설정하는 방법을 보여주는 예시다:
Example 1. pom.xml
...
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<configuration>
<keepDependenciesWithProvidedScope>true</keepDependenciesWithProvidedScope>
<createDependencyReducedPom>true</createDependencyReducedPom>
</configuration>
<dependencies>
<dependency> <!-- (1) -->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${spring.boot.version}</version>
</dependency>
</dependencies>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers> <!-- (2) -->
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.handlers</resource>
</transformer>
<transformer
implementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer">
<resource>META-INF/spring.factories</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>META-INF/spring.schemas</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" />
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
...
(1) spring-boot-maven-plugin을 의존성으로 추가한다.
(2) transformer를 설정한다.
버전은 ${spring.boot.version} 프로퍼티를 추가해도 되고 직접 명시해도 된다.
5.7. Programming Tips and Tricks
이 섹션에선 Spring Integration을 최대한 활용하기 위한 몇 가지 방법을 소개한다.
5.7.1. XML Schemas
XML 설정을 사용할 때 의미 없는 스키마 유효성 검사 에러를 만나지 않으려면 STSSpring Tool Suite나, 스프링 IDE 플러그인이 깔린 Eclipse, IntelliJ IDEA같이 “스프링을 인식할 수 있는” IDE를 사용해야 한다. 이런 IDE들은 클래스패스에서 정확한 XML 스키마를 리졸브하는 방법을 알고 있다 (jar 안에 들어있는 META-INF/spring.schemas 파일을 사용해서). STS를 사용하거나 플러그인과 함께 Eclipse를 사용하는 경우 프로젝트에서 Spring Project Nature를 활성화해야 한다.
일부 레거시 모듈에서 (1.0 버전에 존재했던 모듈들) 인터넷 상으로 호스팅하는 스키마는 호환성 때문에 1.0 버전 스키마를 사용하고 있다. IDE에서 이런 스키마를 사용하는 경우 사실과는 다른 에러가 표시될 수 있다.
이런 온라인 스키마들엔 다음과 유사한 경고 메시지가 들어있다:
This schema is for the 1.0 version of Spring Integration Core. We cannot update it to the current schema because that will break any applications using 1.0.3 or lower. For subsequent versions, the unversioned schema is resolved from the classpath and obtained from the jar. Please refer to github:
영향받는 모듈은 다음과 같다
core(spring-integration.xsd)filehttpjmsmailsecuritystreamwsxml
5.7.2. Finding Class Names for Java and DSL Configuration
XML 설정과 Spring Integration 네임스페이스를 이용할 땐 XML 파서가 타겟 빈들이 어떻게 선언되고 어떻게 함께 연결되는지를 감춰준다. 자바 설정을 사용할 땐 타겟 엔드 유저 애플리케이션을 위한 프레임워크 API를 이해할 필요가 있다.
EIP 구현에 필요한 일급 객체first-class citizen들은 Message, Channel, Endpoint다 (이 챕터 앞부분에 있는 메인 컴포넌트들을 참고해라). 이 것들을 표현한 객체는 다음과 같다:
org.springframework.messaging.Message: 메시지 참고;org.springframework.messaging.MessageChannel: 메시지 채널 참고;org.springframework.integration.endpoint.AbstractEndpoint: Poller 참고.
앞의 두 가지는 간단해서 구현 방법이나, 설정법, 사용법을 쉽게 파악할 수 있을 거다. 마지막 클래스는 좀 더 살펴볼 가치가 있다.
AbstractEndpoint는 스프링 프레임워크 곳곳에서 다양한 구성 요소를 구현하는데 사용하고 있다. 주요 구현체는 다음과 같다:
EventDrivenConsumer.SubscribableChannel을 구독해서 메시지를 수신listen할 때 사용한다.PollingConsumer.PollableChannel에서 메시지를 폴링할 때 사용한다.
메시징 어노테이션이나 자바 DSL을 사용할 땐, 프레임워크가 자동으로 적절한 어노테이션과 BeanPostProcessor 구현체를 통해 이 컴포넌트들을 생성해준다. 따라서 어떤 컴포넌트가 필요할지는 고민하지 않아도 된다. 구성 요소들을 수동으로 빌드할 땐 ConsumerEndpointFactoryBean을 사용하는 게 좋은데, 이렇게 하면 세팅한 inputChannel 속성을 기반으로 어떤 AbstractEndpoint 컨슈머 구현체를 생성할지 쉽게 결정할 수 있다.
한편 ConsumerEndpointFactoryBean은 프레임워크의 또 다른 일급 객체first class citizen org.springframework.messaging.MessageHandler에게 메시지 처리를 위임한다. 이 인터페이스를 구현하는 목적은 엔드포인트가 채널에서 컨슘한 메시지를 처리하기 위함이다. Spring Integration에 있는 모든 EIP 구성 요소들은 MessageHandler의 구현체다 (ex. AggregatingMessageHandler, MessageTransformingHandler, AbstractMessageSplitter 등). 타겟 프로토콜 아웃바운드 어댑터 역시 MessageHandler의 구현체다 (FileWritingMessageHandler, HttpRequestExecutingMessageHandler, AbstractMqttMessageHandler 등). 자바 설정을 이용해 Spring Integration 애플리케이션을 개발할 땐 Spring Integration 모듈을 조사해서 @ServiceActivator 설정에 사용할 적당한 MessageHandler 구현체를 찾아봐야 한다. 예를 들어, XMPP 메시지를 전송하려면 (XMPP 지원 참고) 다음과 같은 설정을 작성해야 한다:
@Bean
@ServiceActivator(inputChannel = "input")
public MessageHandler sendChatMessageHandler(XMPPConnection xmppConnection) {
ChatMessageSendingMessageHandler handler = new ChatMessageSendingMessageHandler(xmppConnection);
DefaultXmppHeaderMapper xmppHeaderMapper = new DefaultXmppHeaderMapper();
xmppHeaderMapper.setRequestHeaderNames("*");
handler.setHeaderMapper(xmppHeaderMapper);
return handler;
}
이런 MessageHandler 구현체들은 메시지 플로우 상에서 아웃바운드와 처리 파트에 해당한다.
인바운드 메시지 플로우 측에는 polling과 listening 동작으로 나뉘는 자체 구성 요소들이 있다. listening (메시지 기반) 구성 요소들은 간단한 편으로, 보통은 메시지를 만들 준비가 된 타겟 클래스 구현체 하나만 있으면 된다. listening 구성 요소는 단방향one-way MessageProducerSupport 구현체이거나 (ex. AbstractMqttMessageDrivenChannelAdapter, ImapIdleChannelAdapter), request-reply MessagingGatewaySupport 구현체일 수 있다 (ex. AmqpInboundGateway, AbstractWebServiceInboundGateway).
폴링 인바운드 엔드포인트들은 파일 기반 프로토콜(ex. FTP), 데이터베이스(RDBMS나 NoSQL) 등을 포함해서, listener API를 제공하지 않거나 listening 방식으로 사용하지 않는 프로토콜을 위한 엔드포인트다.
이 인바운드 엔드포인트들은 주기적으로 폴링 태스크를 시작하는 poller 설정과, 타겟 프로토콜에서 데이터를 읽고 다운스트림 통합 플로우를 위한 메시지를 생성하는 메시지 소스 클래스로 구성된다. poller 설정을 위한 첫 번째 클래스는 SourcePollingChannelAdapter다. 이 클래스는 또 다른 AbstractEndpoint의 구현체지만, 특히 폴링을 이용할 때 통합 플로우를 시작할 수 있는 구현체다. 일반적으로 메시징 어노테이션이나 자바 DSL을 이용하면 이 클래스를 신경쓸 필요는 없다. 프레임워크에서 @InboundChannelAdapter 설정이나 자바 DSL 빌더 스펙을 기반으로 필요한 빈을 생성해준다.
타겟 애플리케이션을 개발할 땐 메시지 소스 컴포넌트가 더욱더 중요한데, 모두 MessageSource 인터페이스를 구현하고 있다 (ex. MongoDbMessageSource, AbstractTwitterMessageSource). 이 점을 기억해 두고, JDBC를 통해 RDBMS 테이블에서 데이터를 읽어올 땐 다음과 유사한 설정을 사용하면 된다:
@Bean
@InboundChannelAdapter(value = "fooChannel", poller = @Poller(fixedDelay="5000"))
public MessageSource<?> storedProc(DataSource dataSource) {
return new JdbcPollingChannelAdapter(dataSource, "SELECT * FROM foo where status = 0");
}
타겟 프로토콜에 필요한 모든 인바운드 및 아웃바운드 클래스들은 개별 Spring Integration 모듈에서 찾을 수 있다 (대부분은 각자의 패키지에 들어있다). spring-integration-websocket 어댑터들로 예를 들면:
o.s.i.websocket.inbound.WebSocketInboundChannelAdapter:MessageProducerSupport를 구현해서 소켓에서 프레임을 수신listen하고 채널에 메시지를 생성한다.o.s.i.websocket.outbound.WebSocketOutboundMessageHandler: 들어오는 메시지들을 적절한 프레임으로 변환하고 웹 소켓을 통해 전송하는 단방향one-wayAbstractMessageHandler구현체.
Spring Integration XML 설정에 익숙하다면, 4.3 버전부터 다음과 같이 XSD 요소 정의에 어댑터나 게이트웨이 관련 빈들을 선언하는 데 필요한 클래스 정보를 제공하고 있다:
<xsd:element name="outbound-async-gateway">
<xsd:annotation>
<xsd:documentation>
Configures a Consumer Endpoint for the 'o.s.i.amqp.outbound.AsyncAmqpOutboundGateway'
that will publish an AMQP Message to the provided Exchange and expect a reply Message.
The sending thread returns immediately; the reply is sent asynchronously; uses 'AsyncRabbitTemplate.sendAndReceive()'.
</xsd:documentation>
</xsd:annotation>
5.8. POJO Method invocation
코드 상에서 고려해야 할 점들을 설명하면서도 언급했지만, 다음 예제와 같은 POJO 프로그래밍 스타일을 권장한다:
@ServiceActivator
public String myService(String payload) { ... }
이 메소드는 프레임워크가 String 페이로드를 추출해서 실행해주며, 실행 결과를 플로우 상에 있는 다음 구성 요소로 보낼 메시지로 감싸준다 (기존 헤더들은 새 메시지로 복사된다). 사실, XML 설정을 사용하는 경우 아래 예시에서 확인할 수 있듯이 @ServiceActivator 어노테이션조차 필요하지 않다.
<int:service-activator ... ref="myPojo" method="myService" />
public String myService(String payload) { ... }
클래스 안에 있는 public 메소드들 중 어떤 메소드를 사용할지가 명확하다면 method 속성은 생략해도 된다.
다음과 같이 POJO 메소드에서 헤더 정보를 가져와 사용할 수도 있다:
@ServiceActivator
public String myService(@Payload String payload, @Header("foo") String fooHeader) { ... }
다음 예제처럼 메시지에 있는 프로퍼티를 역으로 참조하는 것도 가능하다:
@ServiceActivator
public String myService(@Payload("payload.foo") String foo, @Header("bar.baz") String barbaz) { ... }
다양한 POJO 메소드들을 실행할 수 있기 때문에, 5.0 버전 이전엔 SpELSpring Expression Language을 사용해 POJO 메소드를 호출했었다. SpEL의 연산 속도도 (interpreted 표현식조차) 일반적으로 메소드에서 수행하는 실제 작업과 비교하면 “충분히 빠르다”고 볼 수 있다. 하지만 5.0 버전부터는 가능하면 org.springframework.messaging.handler.invocation.InvocableHandlerMethod를 디폴트로 사용한다. 이 방법은 보통 interpreted SpEL보다 실행 속도가 빠르고, 다른 스프링 메시징 프로젝트들에서도 사용하는 방법이기도 하다. InvocableHandlerMethod는 스프링 MVC에서 컨트롤러 메소드를 실행하는 데 사용하는 기술과 유사하다. 하지만 여전히 항상 SpEL을 사용해 호출되는 메소드들도 있다. 예시로 앞에서 설명한 어노테이션을 선언하고 프로퍼티를 역참조하는 파라미터를 들 수 있다. SpEL에선 프로퍼티 경로를 탐색할 수 있기 때문이다.
InvocableHandlerMethod 인스턴스로는 동작하지 않는 다른 생각지 못한 코너 케이스가 존재할 수도 있다. 이와 같은 이유로 InvocableHandlerMethod 방식에 실패했을 땐 자동으로 SpEL로 폴백한다.
원한다면 다음 예제와 같이 UseSpelInvoker 어노테이션을 이용해 POJO 메소드에서 항상 SpEL을 사용하도록 설정할 수도 있다:
@UseSpelInvoker(compilerMode = "IMMEDIATE")
public void bar(String bar) { ... }
compilerMode 프로퍼티를 생략하면 컴파일러 모드는 시스템 프로퍼티 spring.expression.compiler.mode로 결정된다. SpEL 컴파일에 대한 자세한 내용은 SpEL compilation을 참고해라.
Next : Core Messaging
Core Messaging
스프링 인티그레이션의 핵심 메시징 API 소개
전체 목차는 여기에 있습니다.