스프링 클라우드 데이터 플로우 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
이 문서에선 Data Flow 아키텍처의 핵심 개념들을 설명한다:
- Data Flow를 구성하는 서버들.
- 이 서버들로 스트림과 배치 job에 배포할 수 있는 애플리케이션 타입들.
- 배포된 애플리케이션들의 마이크로서비스 아키텍처와 DSL을 통해 이를 정의하는 방법.
- 애플리케이션을 배포할 수 있는 플랫폼들.
아래 내용은 별도 섹션에서 안내한다:
- 서버를 안전하게 보호하는 방법, 그리고 서버와 상호 작용할 수 있는 툴.
- 스트리밍 데이터 파이프라인 런타임 모니터링.
- 스트림, 배치 데이터 파이프라인을 개발할 때 사용할 수 있는 스프링 프로젝트들.
목차
- Server Components
- Application Types
- Prebuilt Applications
- Microservice Architectural Style
- Platforms
Server Components
Data Flow는 두 가지 핵심 서버로 구성된다:
- Data Flow 서버
- Skipper 서버
Data Flow에 접근할 땐 주요 엔트리 포인트로 Data Flow 서버의 RESTful API를 통한다. 웹 대시보드는 이 Data Flow 서버에서 서빙한다. Data Flow 서버와 Data Flow 쉘 애플리케이션이 통신할 때도 모두 이 웹 API를 사용한다.
이 서버들은 여러 가지 플랫폼에서 실행할 수 있다 (클라우드 파운드리, 쿠버네티스 혹은 로컬 시스템). 각 서버는 자신의 상태를 관계형 데이터베이스에 저장한다.
다음은 아키텍처와 커뮤니케이션 경로를 고수준으로 표현한 이미지다:
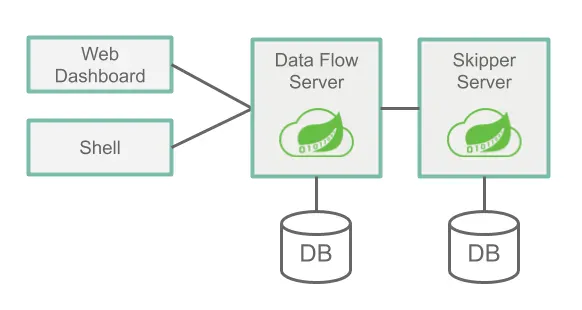
Data Flow Server
Data Flow 서버가 담당하는 일은 다음과 같다:
- DSLDomain-Specific Language 기반 스트림, 배치 job 정의 파싱.
- 스트림, 태스크, 배치 job 정의를 검증하고 저장persist.
- jar나 도커 이미지같은 아티팩트를 DSL에서 사용할 이름에 등록.
- 배치 job을 하나 이상의 플랫폼에 배포.
- job 스케줄링을 플랫폼에 위임.
- 태스크와 배치 job의 상세 실행 내역 질의.
- 스트림에 메세징 입출력을 구성하는 설정 프로퍼티를 추가하고, 배포 프로퍼티(초기 인스턴스 수, 메모리 요구 사항, 데이터 파티셔닝 등)를 전달.
- 스트림 배포를 Skipper에 위임.
- 감사Auditing 작업 (스트림 생성, 배포, 배포 취소undeployment 및 배치 생성, 실행, 삭제).
- 스트림, 배치 job을 위한 DSL 탭 자동 완성 기능 제공.
Skipper Server
Skipper Flow 서버가 담당하는 일은 다음과 같다:
- 스트림을 하나 이상의 플랫폼에 배포.
- 하나 이상의 플랫폼에서 스트림을 업그레이드 및 롤백. 상태 기계state machine 기반 blue/green 업데이트 전략을 사용한다.
- 각 스트림의 매니페스트 파일(어떤 애플리케이션이 배포되었는지에 대한 최종 정보를 가지고 있음) 히스토리를 저장.
Database
Data Flow 서버와 Skipper 서버를 사용하려면 RDBMS가 설치돼 있어야 한다. 이 서버들은 기본적으론 임베디드 H2 데이터베이스를 사용한다. 외부 데이터베이스를 사용하려면 서버 설정을 수정해주면 된다. 데이터베이스는 H2, HSQLDB, MySQL, Oracle, Postgresql, DB2, SqlServer를 지원한다. 필요한 스키마들은 각 서버가 시작할 때 자동으로 생성된다.
Security
Data Flow와 Skipper Server executable jar는 관련 REST 엔드포인트들을 안전하게 보호할 땐 OAuth 2.0 인증을 사용한다. 접근이 필요할 땐 기본 인증이나 OAuth2 액세스 토큰을 사용하면 된다. OAuth provider의 경우 LDAP을 포괄적으로 지원하는 CloudFoundry UAAUser Account and Authentication 서버를 권장한다. 요구사항에 맞게 보안 기능을 설정하고 싶다면, 자세한 방법은 레퍼런스 가이드 문서에 있는 시큐리티 섹션을 참고해라.
기본적으로 REST 엔드포인트(administration, management, health)에 접근할 땐 대시보드 UI와 마찬가지로 인증이 필요하지 않다.
Application Types
애플리케이션은 가지고 있는 특성에 따라 두 가지로 분리할 수 있다:
- Long-lived 애플리케이션. long-lived 애플리케이션에는 두 가지 타입이 있다:
- 단일 입력이나 출력(또는 둘 다)을 통해 무한한 양의 데이터를 컨슘consume하거나 생산 produce하는 메세지 기반 애플리케이션.
- 두 번째 타입은 입출력을 여러 개 가질 수 있는 메세지 기반 애플리케이션이다. 메세지 처리 미들웨어를 전혀 사용하지 않는 애플리케이션일 수도 있다.
- 유한한 데이터 셋을 처리한 뒤 종료되는 short-lived 애플리케이션. short-lived 애플리케이션엔 두 가지 변형이 있다:
- 첫 번째는 코드를 실행해 Data Flow 데이터베이스에 실행 상태를 기록하는 태스크다. 원한다면 Spring Cloud Task 프레임워크를 사용할 수 있으며, 꼭 자바 애플리케이션일 필요는 없다. 하지만 이 애플리케이션은 Data Flow의 데이터베이스에 실행 상태를 기록해야 한다.
- 두 번째는 첫 번째 케이스를 확장한 것으로, 스프링 배치 프레임워크를 기반으로 배치 처리를 수행한다.
보통은 long-lived 애플리케이션은 Spring Cloud Stream 프레임워크를 기반으로, short-lived 애플리케이션은 Spring Cloud Task나 Spring Batch 프레임워크를 기반으로 작성하는 게 일반적이다. 이 문서에는 데이터 파이프라인을 개발하면서 이 프레임워크들을 사용하는 방법을 보여주는 가이드가 많이 있다. 물론 스프링을 사용하지 않고도 long-lived와 short-lived 애플리케이션을 작성할 수 있다. 다른 프로그래밍 언어로도 가능하다.
애플리케이션은 런타임 환경에 따라 두 가지 방법으로 패키징할 수 있다:
- 메이븐 레포지토리나, 파일 위치, 또는 HTTP를 통해 접근할 수 있는 스프링 부트 uber-jar.
- 도커 레지스트리에서 호스팅하는 도커 이미지.
Long-lived Applications
Long-lived 애플리케이션은 끊임없이 실행돼야 한다. 애플리케이션이 중단되면 플랫폼이 해당 애플리케이션을 다시 시작해줄 거다.
Spring Cloud Stream 프레임워크가 제공하는 프로그래밍 모델을 사용하면, 공통 메세지 시스템에 연결되는 메세지 기반 마이크로서비스 애플리케이션을 쉽게 작성할 수 있다. 핵심 비즈니스 로직을 특정한 미들웨어에 구애받지 않고 작성할 수 있다. 사용할 미들웨어는 Spring Cloud Stream Binder 라이브러리를 애플리케이션 의존성으로 추가하는 식으로 결정한다. 아래에 있는 메세지 처리 미들웨어 제품들에 대한 바인딩 라이브러리가 준비되어 있다:
Data Flow 서버는 long-lived 애플리케이션을 배포하는 일은 Skipper 서버에 위임한다.
Streams with Sources, Processors, and Sinks
Spring Cloud Stream은 메세지 교환 패턴, 즉 애플리케이션의 입출력이 무엇인지를 코드로 캡슐화하는 바인딩 인터페이스 개념을 정의하고 있다. Spring Cloud Stream은 일반적인 메세지 교환에서 담당하는 역할들에 상응하는 몇 가지 바인딩 인터페이스를 제공한다:
Source: 목적지에 메세지를 전송하는 메세지 프로듀서.Sink: 목적지에서 메세지를 읽는 메세지 컨슈머.Processor: 소스와 싱크의 결합. 프로세서는 목적지에서 메세지를 컨슘하고 다른 목적지로 전송할 메세지를 생성한다.
이 세 가지 타입의 애플리케이션을 등록할 땐 source, processor, sink를 사용함으로써 해당 애플리케이션의 type을 표현한다.
아래 예시는 http 소스와 (HTTP 요청을 받아 HTTP 페이로드를 목적지로 전송하는 애플리케이션), log 싱크를 (목적지에서 전달받은 메세지를 컨슘하고 로깅하는 애플리케이션) 등록하기 위한 쉘 구문을 보여준다:
dataflow:>app register --name http --type source --uri maven://org.springframework.cloud.stream.app:http-source-rabbit:1.2.0.RELEASE
Successfully registered application 'source:http'
dataflow:>app register --name log --type sink --uri maven://org.springframework.cloud.stream.app:log-sink-rabbit:1.1.0.RELEASE
Successfully registered application 'sink:log'
이제 파이프와 필터 구문을 사용하는 Stream Pipeline DSL을 통해 Data Flow에 등록된 http와 log로 스트림 정의를 생성할 수 있다:
dataflow:>stream create --name httpStream --definition "http | log"
http | log에 있는 파이프 기호는 소스 출력을 싱크 입력으로 연결한다는 것을 나타낸다. Data Flow는 스트림을 배포할 때 적절한 프로퍼티를 설정해서 source가 메세징 미들웨어를 통해 sink와 통신할 수 있도록 한다.
Streams with Multiple Inputs and Outputs
소스, 싱크, 프로세서에는 모두 단일 출력 또는 단일 입력이 있거나, 단일 입출력을 하나씩 가진다. 때문에 Data Flow는 출력 목적지를 입력 목적지에 페어링하는 애플리케이션 프로퍼티를 설정할 수 있다. 하지만 메세지 처리 애플리케이션에선 입력이나 출력 목적지가 둘 이상 존재하기도 한다. Spring Cloud Stream은 이럴 땐 커스텀 바인딩 인터페이스를 정의하는 식으로 이를 지원한다.
입력이 여러 개 있는 애플리케이션을 포함하는 스트림을 정의하려면, 애플리케이션을 source나 sink, processor 타입 대신 app 타입을 사용해 등록해야만 한다. 이런 스트림 정의에는 단일 파이프 기호(|)를 이중 파이프 기호(||)로 대신하는 Stream Application DSL을 사용한다. ||는 애플리케이션 간에 암묵적인 연결이 없는 “병렬”을 의미한다고 생각해봐라.
다음은 가상의 orderStream을 사용하는 예시다:
dataflow:> stream create --definition "orderGeneratorApp || baristaApp || hotDrinkDeliveryApp || coldDrinkDeliveryApp" --name orderStream
| 기호를 사용해 스트림을 정의할 땐 항상 하나의 입력이 하나의 출력과 쌍을 이루기 때문에, Data Flow는 스트림에 있는 각 애플리케이션을 DSL 안에서 인접해 있는 애플리케이션과 통신하도록 설정할 수 있다. || 기호를 사용할 때는 반드시 여러 가지 출력과 입력 목적지를 함께 페어링하는 설정 프로퍼티를 제공해야 한다.
메세징 미들웨어를 사용하지 않는 애플리케이션을 배포하고 Stream Application DSL을 이용하면 단일 애플리케이션으로도 스트림을 생성할 수 있다.
이러한 예시들은 long-lived 애플리케이션 타입에 대한 전반적인 이해를 돕는다. 이어지는 가이드 문서에선 long-lived 애플리케이션을 개발하고, 테스트하고, 등록하는 방법과 배포하는 방법에 대해 자세히 설명한다.
다음에 나오는 주요 섹션에선 배포된 스트림의 런타임 아키텍처에 대해 논한다.
Short-lived Applications
Short-lived 애플리케이션은 일정 시간 동안 (보통 몇 분에서 몇 시간 정도) 실행된 후 종료한다. 이런 애플리케이션들은 일정을 기반으로 실행하거나 (예를 들어 평일 오전 6시마다), 이벤트에 대한 반응으로 실행시킬 수 있다 (예를 들어 FTP 서버에 파일 추가되면).
Spring Cloud Task 프레임워크를 사용하면 short-lived 애플리케이션의 라이프사이클 이벤트를 기록하는 (시작 시간, 종료 시간, 종료 코드 등) short-lived 마이크로서비스를 개발할 수 있다.
태스크 애플리케이션을 Data Flow에 등록할 땐 task라는 이름으로 애플리케이션 타입을 표현한다.
다음은 timestamp 태스크(현재 시간을 출력하고 종료하는 애플리케이션)를 등록하기 위한 쉘 구문을 보여주는 예시다:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:2.1.0.RELEASE
태스크 정의는 다음 예제와 같이 태스크의 이름을 참조해서 생성한다:
dataflow:> task create tsTask --definition "timestamp"
스프링 개발자가 short-lived 애플리케이션을 작성할 때는 아마도 스프링 배치 프레임워크를 가장 먼저 떠올릴 거다. 스프링 배치는 Spring Cloud Task보다 훨씬 풍부한 기능 셋을 제공하며, 대용량 데이터를 처리할 때 권장하곤 한다. 수 많은 CSV 파일을 읽어 데이터의 모든 row를 각각 변환하고, 변환된 모든 row를 데이터베이스에 쓰는 유스 케이스가 있을 수 있다. 스프링 배치는 자체 데이터베이스 스키마와 함께 스프링 배치 job 실행에 관한 훨씬 더 풍부한 정보 셋을 제공한다. Spring Cloud Task 애플리케이션에서 스프링 배치 job을 정의해서 Spring Cloud Task를 스프링 배치와 통합하면, Spring Cloud Task와 스프링 배치 실행 테이블 간의 링크가 만들어진다.
스프링 배치를 사용하는 태스크는 앞에서 본 것과 같은 방식으로 등록하고 생성한다.
지정 플랫폼에서 태스크를 실행시키는 건 Spring Cloud Data Flow 서버다.
Composed Tasks
Spring Cloud Data Flow를 이용하면 태스크 애플리케이션을 그래프의 각 노드로 표현하는 유향 그래프directed graph를 생성할 수 있다.
이땐 composed 태스크를 위한 전용 Composed Task DSLDomain Specific Language을 사용한다. Composed Task DSL에는 전반적인 플로우를 결정하는 몇 가지 기호가 있다. 자세런 내용은 레퍼런스 가이드에서 다루고 있다. 다음은 조건부 실행conditional execution을 위해 이중 앰퍼샌드 기호(&&)를 사용하는 방법을 보여주는 예시다:
dataflow:> task create simpleComposedTask --definition "task1 && task2"
이 DSL 표현식(task1 && task2)은 task1이 성공적으로 실행을 마친 경우에만 task2를 실행한다는 것을 의미한다. 이 태스크들의 그래프는 Composed Task Runner라는 태스크 애플리케이션을 통해 실행된다.
이어지는 가이드 문서에선 short-lived 애플리케이션을 개발하고, 테스트하고, 등록하는 방법과 배포하는 방법에 대해 자세히 설명한다.
Application Metadata
Long-lived 애플리케이션과 short-lived 애플리케이션은 지원하는 설정 프로퍼티에 대한 메타데이터를 제공할 수 있다. 이 메타데이터는 쉘과 UI 툴에서 데이터 파이프라인을 구축할 때 상황에 맞는 도움말과 코드 자동 완성을 제공하는데 활용된다. 애플리케이션 메타데이터를 생성하고 사용하는 방법은 이 상세 가이드에서 자세히 알아볼 수 있다.
Prebuilt Applications
미리 빌드해서 제공하는 다양한 애플리케이션을 이용하면 흔히 쓰는 데이터 소스와 싱크와 통합해 빠르게 개발을 시작할 수 있다. 예를 들어 데이터를 Cassandra에 쓰는 cassandra 싱크와 Groovy 스크립트를 사용해 들어오는 데이터를 변환하는 groovy-transform 프로세서를 활용할 수 있다.
이런 애플리케이션들을 Spring Cloud Data Flow에 등록하는 방법은 설치 가이드에서 설명하고 있다.
미리 빌드된 애플리케이션들에 관한 자세한 정보는 Applications 가이드에서 확인할 수 있다.
Microservice Architectural Style
Data Flow, Skipper 서버가 스트림과 composed 배치 job을 플랫폼에 배포할 땐, 각각을 자체 프로세스에서 실행되는 마이크로서비스 애플리케이션으로 배포한다. 각 마이크로 서비스 애플리케이션은 독립적으로 확장scale up하거나 축소할scale down 수 있으며, 각 애플리케이션마다 고유한 라이플사이클 버전을 갖는다. Skipper를 통하면 스트림에 있는 각 애플리케이션들을 런타임에 독립적으로 업그레이드하거나 롤백할 수 있다.
Spring Cloud Stream과 Spring Cloud Task를 사용하면 각 마이크로서비스 애플리케이션은 스프링 부트를 기반 라이브러리로 사용해 빌드한다. 이렇게 하면 health 체크, 보안, 로그 설정, 모니터링, management 기능은 물론 executable JAR 패키징과 같은 모든 마이크로서비스 애플리케이션 기능을 이용할 수 있다.
이런 마이크로서비스 애플리케이션에서 중요한 건, 직접 java -jar을 사용해 적당한 설정 프로퍼티를 전달해서 실행할 수 있는 “단순한 앱”이라는 점이다. 데이터 처리를 위한 나만의 마이크로서비스 애플리케이션을 생성하는 것은 그외 다른 스프링 부트 애플리케이션을 만드는 것과 크게 다르지 않다. 스프링 Initializr 웹 사이트를 이용해 스트림 기반이나 태스크 기반 마이크로서비스의 기본적인 구조를 잡고 시작할 수 있다.
Data Flow, Skipper 서버는 각 애플리케이션에 적절한 애플리케이션 프로퍼티를 넘겨주는 일도 담당하지만, 타겟 플랫폼의 인프라를 준비하는 역할도 담당하고 있다. 예를 들어 클라우드 파운드리에선 지정한 서비스를 해당 애플리케이션에 바인딩해줄 거다. 쿠버네티스에선 deployment와 service 리소스를 생성할 거다.
Data Flow 서버는 필요한 입출력 토픽들, 파티션, 메트릭 기능을 세팅해주므로, 타겟 런타임에 관련된 여러 애플리케이션을 배포하는 일을 단순하게 만들어준다. 물론, Data Flow나 Skipper를 전혀 사용하지 않고 각 마이크로서비스 애플리케이션을 수동으로 배포해도 된다. 이 방식은 대규모 애플리케이션보단 소규모 배포로 시작할 때 좀더 적절하며, 더 많은 애플리케이션을 개발하면서 Data Flow가 주는 편리함과 일관성을 조금씩 이용하는 방향으로 넘어갈 수 있을 거다. 스트림, 태스크 기반 마이크로서비스를 수동으로 배포해보면 Data Flow 서버가 자동 애플리케이션 구성과 플랫폼 타겟팅을 어떻게 도와주고 있는지 이해할 수 있기 때문에, Data Flow를 익히기 좋은 연습 단계라고 볼 수 있다. 스트림과 배치 개발자 가이드에선 수동으로도 배포해 볼 거다.
Comparison to Other Architectures
Spring Cloud Data Flow가 가지고 있는 아키텍처 스타일은 다른 스트림, 배치 처리 플랫폼과는 다르다. 예를 들어 Apache Spark, Apache Flink, Google Cloud Dataflow에선 전용 컴퓨팅 엔진 클러스터에서 애플리케이션을 실행한다. 컴퓨팅 엔진 덕분에 이런 플랫폼들은 Spring Cloud Data Flow에 비해 복잡한 계산을 수행할 수 있는 환경을 받쳐주지만, 데이터 중심data-centric 애플리케이션을 만든다고 해서 이런 실행 환경이 무조건 필요한 건 아닌데도 복잡성을 더하게 된다. 그렇다고해서 Spring Cloud Data Flow를 사용하면 실시간으로 데이터를 계산해낼 수 없다는 의미도 아니다. 예를 들어 개발하는 애플리케이션에서 Kafka Streams API의 time-sliding-window와 moving-average 기능을 사용할 수도 있고, 참조 데이터 셋에 수신한 메세지를 조인할 수도 있다.
Spring Cloud Data Flow의 아키텍처는 많은 것들을 런타임에 흔히 쓰는 플랫폼으로 위임할 수 있다는 장점이 있다. Data Flow가 가진 기능 셋(복원력resilience과 확장성scalability)을 활용할 수 있을 뿐더러, 해당 플랫폼을 다른 목적으로도 사용하고 있었다면 그 플랫폼에 관해 알고 있는 지식도 그대로 활용할 수 있다. 다른 end-user/web 애플리케이션을 배포할 때 사용하고 있는 기술들을 그대로 적용할 수 있기 때문에, 데이터 중심data-centric 애플리케이션을 만들고 관리하기 위해 또 다른 지식을 익힐 필요가 없다.
Streams
다음은 간단한 스트림 하나의 런타임 아키텍처를 나타낸 이미지다:
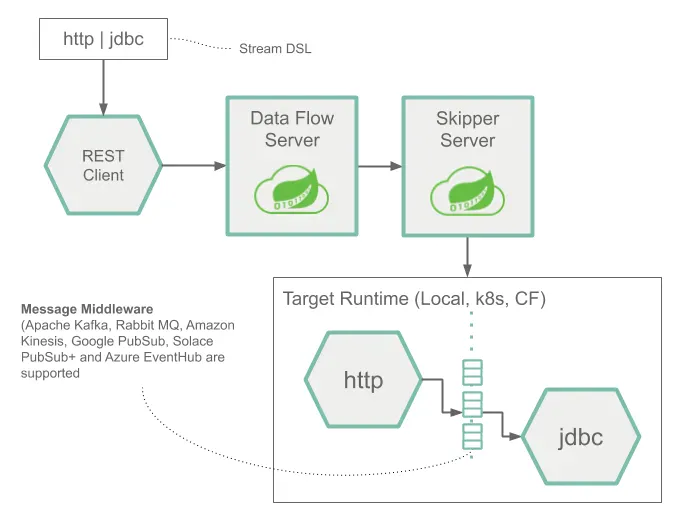
이 스트림 DSL은 POST를 통해 Data Flow 서버로 전송된다. DSL에 있는 애플리케이션 이름에 매핑된 메이븐과 도커 아티팩트에 따라, http 소스와 jdbc 싱크 애플리케이션이 Skipper에 의해 타겟 플랫폼에 배포된다. HTTP 애플리케이션에 게시된 데이터는 데이터베이스에 저장된다.
http소스와jdbc싱크 애플리케이션은 지정한 플랫폼에서 실행되며, Data Flow나 Skipper 서버와는 연결되지 않는다.
다음은 입출력을 여러 개 가질 수 있는 애플리케이션들로 구성된 스트림의 런타임 아키텍처를 나타낸 이미지다:
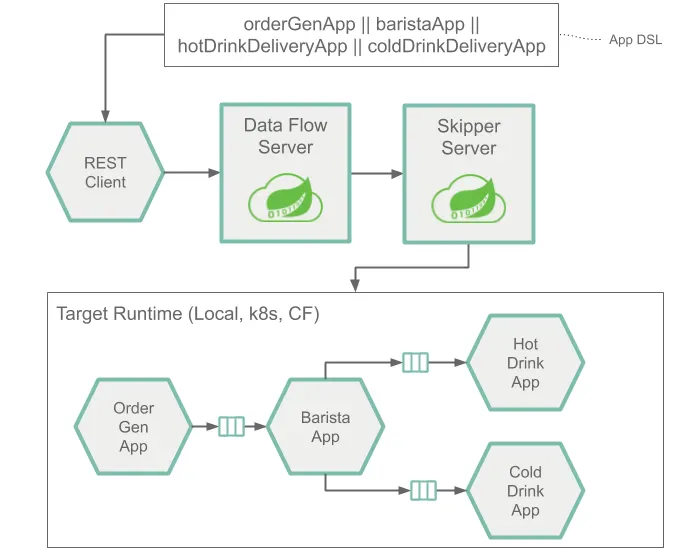
구조적으론 Source나 Sink, Processor 애플리케이션들을 사용할 때와 동일하다. 이 아키텍처를 정의하는 Stream Application DSL은 단일 파이프(|) 기호 대신 이중 파이프 기호(||)를 사용한다. 이런 류의 스트림을 배포할 때는 메세징 시스템을 사용해서 각각의 애플리케이션들이 어떻게 다른 애플리케이션에 연결하는지를 나타내는 정보를 추가로 제공해야 한다.
Tasks and Batch Jobs
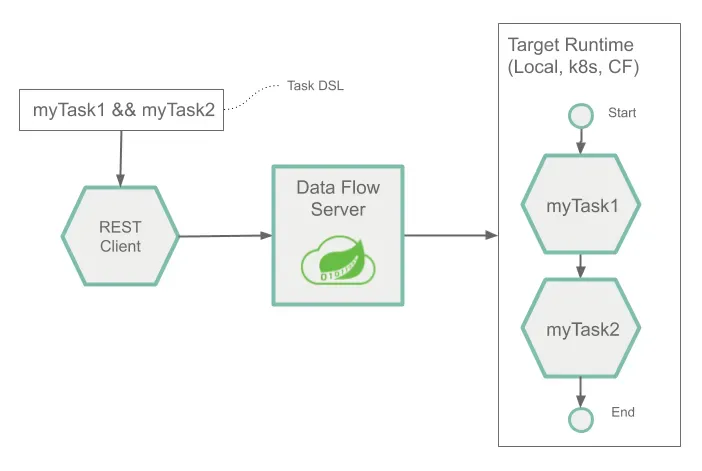
다음은 한 가지 태스크와 스프링 배치 job의 런타임 아키텍처를 나타낸 이미지다:
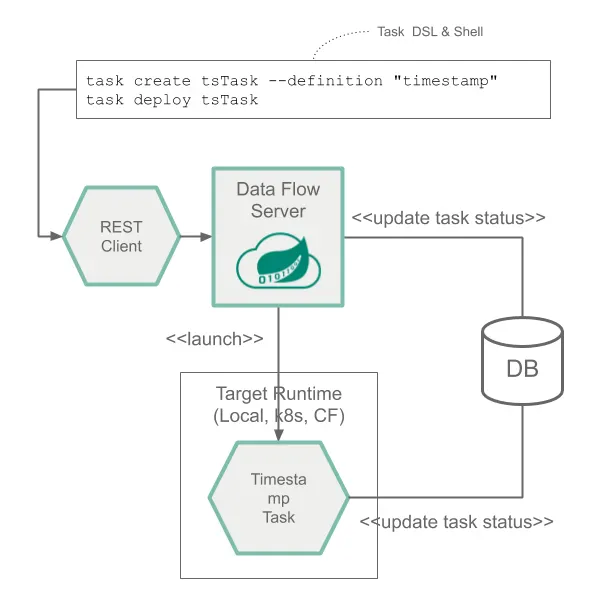
Composed Tasks
다음은 composed 태스크의 런타임 아키텍처를 나타낸 이미지다:
Platforms
Spring Cloud Data Flow 서버와 Skipper 서버는 클라우드 파운드리와 쿠버네티스, 로컬 머신에 배포할 수 있다.
이 서버들로 배포할 애플리케이션도 여러 가지 플랫폼에 배포할 수 있다:
- Local: 로컬 머신이나 클라우드 파운드리, 쿠버네티스에 배포할 수 있다.
- Cloud Foundry: 클라우드 파운드리나 쿠버네티스에 배포할 수 있다.
- Kubernetes: 클라우드 파운드리나 쿠버네티스에 배포할 수 있다.
보통은 애플리케이션을 배포하는 플랫폼과 동일한 플랫폼에 Data Flow, Skipper 서버를 설치하는 게 가장 일반적인 아키텍처다. 여러 가지 클라우드 파운드리 org, space, foundation과 여러 가지 쿠버네티스 클러스터에 배포하는 것도 가능하다.
다른 플랫폼, 즉 HashiCorp Nomad, Red Hat OpenShift, Apache Mesos에 배포할 수 있게 해주는 커뮤니티 구현체들도 존재한다.
로컬 서버는 프로덕션 수준으로는 스프링 배치 어드민 프로젝트를 대신해서 태스크를 배포하는 용도로만 지원하고 있다. 프로덕션 스트림 배포 용도로는 지원하지 않는다.
Next :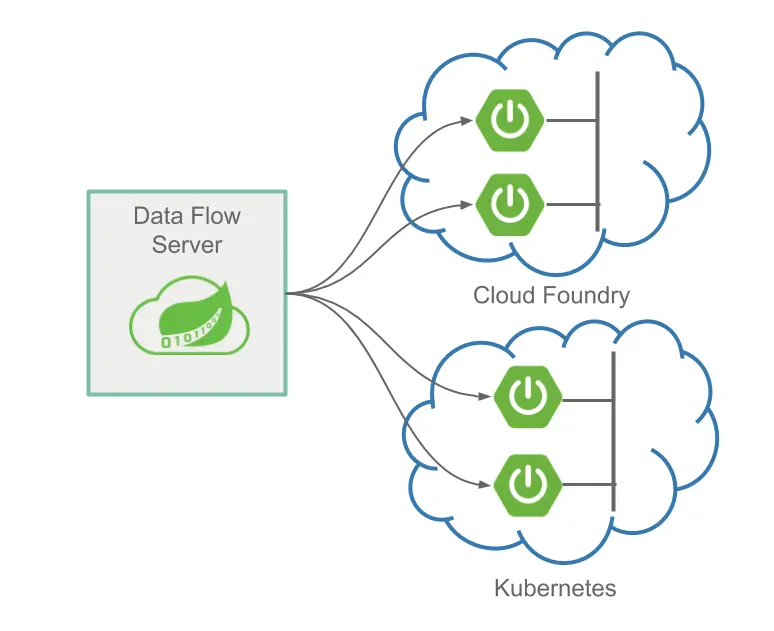 Stream Processing
Stream Processing
스트림 처리를 위한 프레임워크 Spring Cloud Stream 소개
전체 목차는 여기에 있습니다.