스프링 클라우드 데이터 플로우 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
이 레시피에선 멀티 플랫폼 배포가 반드시 필요해진 상황을 분석해본다. 유스 케이스 설명부터 시작해서 Spring Cloud Data Flow에 설정하는 방법을 자세히 파헤쳐본다.
목차
Use Cases
- 어떤 유스 케이스에서는, 스트리밍과 배치 데이터 파이프라인을 고유 환경으로 격리해서 배포하고 싶을 수 있다. 예를 들어 메모리가 많이 필요한 예측 모델 트레이닝 루틴을 실행할 때가 그렇다. 이런 곳에선 보통 명확한 바운더리를 정해놓고, 이 바운더리 내에선 특정한 워크로드만 실행을 허용한다. 다른 말로 하면, 일반 애플리케이션이 고성능 컴퓨팅 전용 리소스 풀을 선점해서 가용성에 영향을 주는 것은 피하고 싶다는 거다. 프리미엄 비용을 내는 대신 사용량에 따른 과금pay-per-use 방식으로 머신을 실행할 땐 특히 더 중요하다.
- 위 유스 케이스와 유사하게, 애플리케이션을 메세지 브로커와 더 가까운 곳에서 실행해야 할 수도 있다 (즉, 비지니스 로직을 데이터가 있는 곳과 가까운 곳에서 실행한다). 이렇게 하면 I/O 지연 시간을 줄여 높은 처리량과 짧은 대기 시간이라는 SLAservice-level agreement를 충족할 수 있다. 다시 말해, 스트리밍 애플리케이션을 메세지 브로커가 실행 중인 VM에 배포하도록 타겟팅할 수 있는 배포 패턴을 적용orchestration하면 SLA에 도움이 되기도 한다.
- 간혹 스트리밍, 배치 데이터 파이프라인을 여러 환경에 배포하고 실행하는 배포 모델을 “단일” Spring Cloud Data Flow 인스턴스를 사용해 조율orchestration하기도 한다. 이 배포 패턴은 주로, 단일 SCDF 인스턴스가 중앙에서 데이터 파이프라인을 오케스트레이션, 모니터링, 관리할 수 있는 경계를 잘 정의해둔 배포 토폴로지를 구성할 때 사용한다.
위 시나리오를 위해선 Spring Cloud Data Flow가 스트리밍, 배치 애플리케이션을 플랫폼 설정별로 유연하게 배포할 수 있어야 한다. 다행히도 Spring Cloud Data Flow는 v2.0부터 멀티 플랫폼 배포를 지원한다. 덕분에 사용자는 플랫폼 계정을 원하는 수만큼 미리 선언해두고, 배포 시점에 정의해둔 계정을 사용해 바운더리를 구분할 수 있다.
이제 유스 케이스의 요구 사항을 이해했으므로, 쿠버네티스와 클라우드 파운드리에서 멀티 플랫폼 계정들을 설정하는 단계를 리뷰해보자.
Configuration
이 섹션에선 쿠버네티스와 클라우드 파운드리를 위한 설정을 설명한다.
Kubernetes
3개의 애플리케이션으로 구성된 스트림을 kafka-namespace에 배포하려 한다고 가정해보자. highmemory-namespace에서 배치 job을 기동하고 싶을 때도 마찬가지로 SCDF deployment 파일 안에 설정을 정의하면 된다.
스트리밍 데이터 파이프라인은 Skipper를 통해 관리하기 때문에, skipper-config-kafka.yaml을 다음과 같이 변경하면 된다:
apiVersion: v1
kind: ConfigMap
metadata:
name: skipper
labels:
app: skipper
data:
application.yaml: |-
spring:
cloud:
skipper:
server:
platform:
kubernetes:
accounts:
default:
namespace: default
environmentVariables: 'SPRING_CLOUD_STREAM_KAFKA_BINDER_BROKERS=${KAFKA_SERVICE_HOST}:${KAFKA_SERVICE_PORT},SPRING_CLOUD_STREAM_KAFKA_BINDER_ZK_NODES=${KAFKA_ZK_SERVICE_HOST}:${KAFKA_ZK_SERVICE_PORT}'
limits:
memory: 1024Mi
cpu: 500m
readinessProbeDelay: 120
livenessProbeDelay: 90
kafkazone:
namespace: kafka-namespace
environmentVariables: 'SPRING_CLOUD_STREAM_KAFKA_BINDER_BROKERS=${KAFKA_SERVICE_HOST}:${KAFKA_SERVICE_PORT},SPRING_CLOUD_STREAM_KAFKA_BINDER_ZK_NODES=${KAFKA_ZK_SERVICE_HOST}:${KAFKA_ZK_SERVICE_PORT}'
limits:
memory: 2048Mi
cpu: 500m
readinessProbeDelay: 180
livenessProbeDelay: 120
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/skipper
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"
브로커로 RabbitMQ를 사용한다면 이 파일 대신
skipper-config-rabbit.yaml을 변경해야 한다.
kafkazone이라는 플랫폼 계정을 추가한 것에 주목해라. 여기서는 배포하는 포드의 readiness, liveness 프로브를 커스텀하고, 동시에 디폴트 메모리를 2GB로 설정하고 있다.
배치 데이터 파이프라인은 server-config.yaml에 있는 설정을 다음과 같이 변경해야 한다:
apiVersion: v1
kind: ConfigMap
metadata:
name: scdf-server
labels:
app: scdf-server
data:
application.yaml: |-
management:
metrics:
export:
prometheus:
enabled: true
rsocket:
enabled: true
host: prometheus-proxy
port: 7001
spring:
cloud:
dataflow:
metrics:
dashboard:
url: 'https://grafana:3000'
task:
platform:
kubernetes:
accounts:
default:
namespace: default
limits:
memory: 1024Mi
highmemory:
namespace: highmemory-namespace
limits:
memory: 4096Mi
datasource:
url: jdbc:mysql://${MYSQL_SERVICE_HOST}:${MYSQL_SERVICE_PORT}/mysql
username: root
password: ${mysql-root-password}
driverClassName: org.mariadb.jdbc.Driver
testOnBorrow: true
validationQuery: "SELECT 1"
highmemory라는 플랫폼 계정을 추가한 것에 주목해라. 여기서는 배포하는 포드의 디폴트 메모리를 4GB로 설정하고 있다.
이 설정을 사용하면 SCDF에서 스트림을 배포할 때 플랫폼을 선택할 수 있는 옵션이 생긴다. 사용 가능한 플랫폼들을 나열하고 하나를 선택하면 된다:
dataflow:>stream platform-list
╔═════════╤══════════╤═══════════════════════════════════════════════════════════════════════════════════════╗
║ Name │ Type │ Description ║
╠═════════╪══════════╪═══════════════════════════════════════════════════════════════════════════════════════╣
║default │kubernetes│master url = [https://10.0.0.1:443/], namespace = [default], api version = [v1] ║
║kafkazone│kubernetes│master url = [https://10.0.0.1:443/], namespace = [kafka-namespace], api version = [v1]║
╚═════════╧══════════╧═══════════════════════════════════════════════════════════════════════════════════════╝
dataflow:>task platform-list
╔═════════════╤═════════════╤════════════════════════════════════════════════════════════════════════════════════════════╗
║Platform Name│Platform Type│ Description ║
╠═════════════╪═════════════╪════════════════════════════════════════════════════════════════════════════════════════════╣
║default │Kubernetes │master url = [https://10.0.0.1:443/], namespace = [default], api version = [v1] ║
║highmemory │Kubernetes │master url = [https://10.0.0.1:443/], namespace = [highmemory-namespace], api version = [v1]║
╚═════════════╧═════════════╧════════════════════════════════════════════════════════════════════════════════════════════╝
스트림을 생성한다.
dataflow:>stream create foo --definition "cardata | predict | cassandra"
Created new stream 'foo'
스트림을 배포한다.
dataflow:>stream deploy --name foo --platformName kafkazone
배포 내역을 검증한다.
kubectl get svc -n kafka-namespace
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka ClusterIP 10.0.7.155 <none> 9092/TCP 7m29s
kafka-zk ClusterIP 10.0.15.169 <none> 2181/TCP,2888/TCP,3888/TCP 7m29s
kubectl get pods -n kafka-namespace
NAME READY STATUS RESTARTS AGE
foo-cassandra-v1-5d79b8bdcd-94kw4 1/1 Running 0 63s
foo-cardata-v1-6cdc98fbd-cmrr2 1/1 Running 0 63s
foo-predict-v1-758dc44575-tcdkd 1/1 Running 0 63s
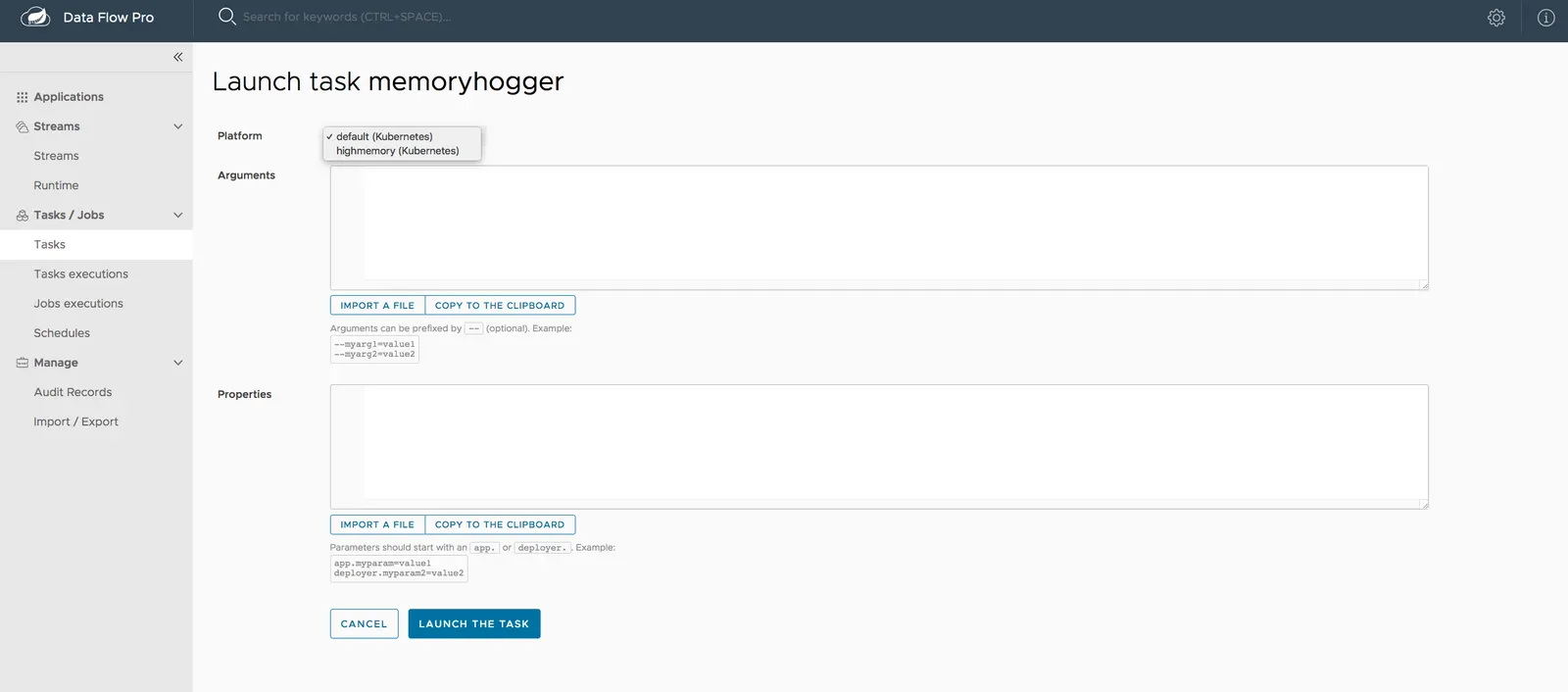
아니면 SCDF 대시보드에서 플랫폼 드롭다운을 이용해 태스크를 생성하고 실행해도 된다. 다음은 태스크를 기동하는 방법을 보여주는 이미지다:
Cloud Foundry
동일한 요구 사항으로 3개의 애플리케이션으로 구성된 스트림을 카프카 서비스가 실행 중인 org, space에 배포할 때와, 컴퓨팅 성능이 더 높은 org, space에 배치 job을 배포할 때는, 다음과 같이 클라우드 파운드리 전용 SCDF의 설정을 변경하면 된다.
스트리밍 데이터 파이프라인은 Skipper를 통해 관리하므로, Skipper의 manifest.yml에 카프카 org, space의 커넥션 credential을 추가해주면 된다.
applications:
- name: skipper-server
host: skipper-server
memory: 1G
disk_quota: 1G
instances: 1
timeout: 180
buildpack: java_buildpack
path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR>
env:
SPRING_APPLICATION_NAME: skipper-server
SPRING_PROFILES_ACTIVE: cloud
JBP_CONFIG_SPRING_AUTO_RECONFIGURATION: '{enabled: false}'
SPRING_APPLICATION_JSON: |-
{
"spring.cloud.skipper.server" : {
"platform.cloudfoundry.accounts": {
"default": {
"connection" : {
"url" : <cf-api-url>,
"domain" : <cf-apps-domain>,
"org" : <org>,
"space" : <space>,
"username": <email>,
"password" : <password>,
"skipSsValidation" : false
}
"deployment" : {
"deleteRoutes" : false,
"services" : "rabbitmq",
"enableRandomAppNamePrefix" : false,
"memory" : 2048
}
},
"kafkazone": {
"connection" : {
"url" : <cf-api-url>,
"domain" : <cf-apps-domain>,
"org" : kafka-org,
"space" : kafka-space,
"username": <email>,
"password" : <password>,
"skipSsValidation" : false
}
"deployment" : {
"deleteRoutes" : false,
"services" : "kafkacups",
"enableRandomAppNamePrefix" : false,
"memory" : 3072
}
}
}
}
}
services:
- <services>
kafkazone이라는 플랫폼 계정을 추가한 것에 주목해라. 여기서는 배포하는 애플리케이션의 디폴트 메모리를 3GB로 설정하고 있다.
배치 데이터 파이프라인에선 SCDF의 manifest.yml 설정을 다음과 같이 변경해야 한다:
applications:
- name: data-flow-server
host: data-flow-server
memory: 2G
disk_quota: 2G
instances: 1
path: { PATH TO SERVER UBER-JAR }
env:
SPRING_APPLICATION_NAME: data-flow-server
SPRING_PROFILES_ACTIVE: cloud
JBP_CONFIG_SPRING_AUTO_RECONFIGURATION: '{enabled: false}'
SPRING_CLOUD_SKIPPER_CLIENT_SERVER_URI: https://<skipper-host-name>/api
SPRING_APPLICATION_JSON: |-
{
"maven" : {
"remoteRepositories" : {
"repo1" : {
"url" : "https://repo.spring.io/libs-snapshot"
}
}
},
"spring.cloud.dataflow" : {
"task.platform.cloudfoundry.accounts" : {
"default" : {
"connection" : {
"url" : <cf-api-url>,
"domain" : <cf-apps-domain>,
"org" : <org>,
"space" : <space>,
"username" : <email>,
"password" : <password>,
"skipSsValidation" : true
}
"deployment" : {
"services" : "postgresSQL"
}
},
"highmemory" : {
"connection" : {
"url" : <cf-api-url>,
"domain" : <cf-apps-domain>,
"org" : highmemory-org,
"space" : highmemory-space,
"username" : <email>,
"password" : <password>,
"skipSsValidation" : true
}
"deployment" : {
"services" : "postgresSQL",
"memory" : 5120
}
}
}
}
}
services:
- postgresSQL
highmemory라는 플랫폼 계정을 추가한 것에 주목해라. 여기서는 배포하는 애플리케이션의 디폴트 메모리를 5GB로 설정하고 있다.
이 설정을 사용하면 SCDF에서 스트림을 배포할 때 플랫폼을 선택할 수 있는 옵션이 생긴다. 사용 가능한 플랫폼들을 나열하고 하나를 선택하면 된다:
dataflow:>stream platform-list
╔═════════╤════════════╤════════════════════════════════════════════════════════════════════════════╗
║ Name │ Type │ Description ║
╠═════════╪════════════╪════════════════════════════════════════════════════════════════════════════╣
║default │cloudfoundry│org = [scdf-%%], space = [space-%%%%%], url = [https://api.run.pivotal.io] ║
║kafkazone│cloudfoundry│org = [kafka-org], space = [kafka-space], url = [https://api.run.pivotal.io]║
╚═════════╧════════════╧════════════════════════════════════════════════════════════════════════════╝
dataflow:>task platform-list
╔═════════════╤═════════════╤══════════════════════════════════════════════════════════════════════════════════════╗
║Platform Name│Platform Type│ Description ║
╠═════════════╪═════════════╪══════════════════════════════════════════════════════════════════════════════════════╣
║default │Cloud Foundry│org = [scdf-%%], space = [space-%%%%%], url = [https://api.run.pivotal.io] ║
║highmemory │Cloud Foundry│org = [highmemory-org], space = [highmemory-space], url = [https://api.run.pivotal.io]║
╚═════════════╧═════════════╧══════════════════════════════════════════════════════════════════════════════════════╝
스트림을 생성한다.
dataflow:>stream create foo --definition "cardata | predict | cassandra"
Created new stream 'foo'
스트림을 배포한다.
dataflow:>stream deploy --name foo --platformName kafkazone
배포 내역을 검증한다.
cf apps
Getting apps in org kafka-org / space kafka-space as kafka@com.io...
OK
name requested state instances memory disk urls
j6wQUU3-foo-predict-v1 started 1/1 3G 1G j6wQUU3-foo-predict-v1.cfapps.io
j6wQUU3-foo-cardata-v1 started 1/1 3G 1G j6wQUU3-foo-cardata-v1.cfapps.io
j6wQUU3-foo-cassandra-v1 started 1/1 3G 1G j6wQUU3-foo-cassandra-v1.cfapps.io
아니면 SCDF 대시보드에서 플랫폼 드롭다운을 이용해 태스크를 생성하고 실행해도 된다.
Mixing Cloud Foundry and Kubernetes Deployments
간혹 특정 워크로드는 쿠버네티스에 배포하고 나머지는 클라우드 파운드리에 배포하는 배포 모델을 적용orchestration해야 할 때가 있다. 두 플랫폼 모두 런타임 관점에서 서로 다른 수준의 지원을 제공하며, 결국에는 다른 플랫폼에 유연하게 워크로드를 배포할 수 있다는 건 추가 이득이다.
Spring Cloud Data Flow를 클라우드 파운드리에서 실행하고 있다고 상상해보자. 여기서 설정 세팅만 추가해서 동일한 SCDF 인스턴스 내에 쿠버네티스 계정을 하나 이상 정의하고 준비하는 것도 가능하다. 이런 유연성 덕분에 스트리밍, 배치 데이터 파이프라인을 다양한 플랫폼에 배포하는 흥미진진한 배포 시나리오가 열렸다!
이번에도 클라우드 파운드리 환경을 가정해 보겠다. 아래 Skipper manifest.yml에는 default와 highmemory 플랫폼 계정 외에 gpuzone이라는 또 다른 계정이 보일 거다.
applications:
- name: skipper-server
host: skipper-server
memory: 1G
disk_quota: 1G
instances: 1
timeout: 180
buildpack: java_buildpack
path: <PATH TO THE DOWNLOADED SKIPPER SERVER UBER-JAR>
env:
SPRING_APPLICATION_NAME: skipper-server
SPRING_PROFILES_ACTIVE: cloud
JBP_CONFIG_SPRING_AUTO_RECONFIGURATION: '{enabled: false}'
SPRING_APPLICATION_JSON: |-
{
"spring.cloud.skipper.server" : {
"platform.cloudfoundry.accounts": {
"default": {
"connection" : {
"url" : <cf-api-url>,
"domain" : <cf-apps-domain>,
"org" : <org>,
"space" : <space>,
"username": <email>,
"password" : <password>,
"skipSsValidation" : false
}
"deployment" : {
"deleteRoutes" : false,
"services" : "rabbitmq",
"enableRandomAppNamePrefix" : false,
"memory" : 2048
}
},
"kafkazone": {
"connection" : {
"url" : <cf-api-url>,
"domain" : <cf-apps-domain>,
"org" : kafka-org,
"space" : kafka-space,
"username": <email>,
"password" : <password>,
"skipSsValidation" : false
}
"deployment" : {
"deleteRoutes" : false,
"services" : "kafkacups",
"enableRandomAppNamePrefix" : false,
"memory" : 3072
}
}
}
},
"platform.kubernetes.accounts": {
"gpuzone": {
"fabric8" : {
"masterUrl" : <k8s-master-api-url>,
"namespace" : "gpuzone-namespace",
"trustCerts" : "true"
}
}
}
}
services:
- <services>
여기선 gpuzone은 쿠버네티스에 있는 GPU VM 노드 풀을 타겟팅하고 있다. 이 간단한 설정을 선언해준 것만으로, 이제 이 SCDF 인스턴스는 스트리밍, 배치 데이터 파이프라인을 각기 다른 세 가지 컴퓨팅 환경으로 배포할 수 있다.
이 설정을 사용하면 스트리밍이나 배치 데이터 파이프라인을 배포할 때 세 가지 플랫폼 계정(default, highmemory, gpuzone)을 선택할 수 있는 옵션이 생긴다.
사용 가능한 플랫폼들을 나열해본다.
dataflow:>stream platform-list
╔═════════╤════════════╤═══════════════════════════════════════════════════════════════════════════════════════════╗
║ Name │ Type │ Description ║
╠═════════╪════════════╪═══════════════════════════════════════════════════════════════════════════════════════════╣
║default │cloudfoundry│org = [scdf-%%], space = [space-%%%%%], url = [https://api.run.pivotal.io] ║
║kafkazone│cloudfoundry│org = [kafka-org], space = [kafka-space], url = [https://api.run.pivotal.io] ║
║gpuzone │kubernetes │master url = [https://10.0.0.1:443/], namespace = [gpuzone-namespace], api version = [v1] ║
╚═════════╧════════════╧═══════════════════════════════════════════════════════════════════════════════════════════╝
스트림을 생성한다.
dataflow:>stream create foo --definition "cardata | predict | cassandra"
Created new stream 'foo'
스트림을 배포한다.
dataflow:>stream deploy --name foo --platformName gpuzone
쿠버네티스에 포드가 새로 떴는지 검증한다.
kubectl get pods -n gpuzone-namespace
NAME READY STATUS RESTARTS AGE
foo-cassandra-v1-aakhslff-94kw4 1/1 Running 0 73s
foo-cardata-v1-fdalsssdf2-cmrr2 1/1 Running 0 73s
foo-predict-v1-p1j35435-tcdkd 1/1 Running 0 73s
하지만 클라우드 파운드리엔 애플리케이션이 새로 배포되지 않았어야 한다. 이것도 함께 검증해보자.
cf apps
Getting apps in org scdf-%%% / space space-%%%%% as $$$$$@com.io...
OK
name requested state instances memory disk urls
sabby-skipper started 1/1 1G 1G sabby-skipper.....
sabby-test-dataflow-server started 1/1 1G 1G sabby-test-dataflow-server....
Next : Launching Apps Across Multiple Platforms
Launching Apps Across Multiple Platforms
태스크를 여러 가지 플랫폼에서 실행하고 예약하기
전체 목차는 여기에 있습니다.