스프링 클라우드 데이터 플로우 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
배치 개발자 가이드에선 전형적인 싱글 스레드 스프링 배치 애플리케이션을 만드는 방법을 보여줬다. 대부분의 배치 애플리케이션엔 싱글 스레드로도 충분하지만, 배치 job에 있는 특정 step에서 필요한 작업을 수행하는 데 상당한 시간이 소요되는 경우가 간혹 있다. 스프링 배치에는 배치 Job이 Step을 나눠 실행해서, 각 파티션이 작업의 일부를 처리하도록 만들 수 있는 솔루션이 있다. 간단히 말해, 파티셔닝을 이용해 대규모 배치 애플리케이션을 여러 인스턴스로 동시에 실행할 수 있다. 파티셔닝의 목적은 오랫동안 실행되는 배치 job을 처리하는 데 들어가는 시간을 줄이는 거다. 파티셔닝이 가능한 프로세스는 입력 파일을 분할할 수 있는 프로세스, 혹은 메인 데이터베이스 테이블이 분할돼 있어서 애플리케이션이 다른 데이터 셋을 바라보고 실행할 수 있는 프로세스다.
그러면 step을 세 개 이용하는 job을 하나 생각해보자:
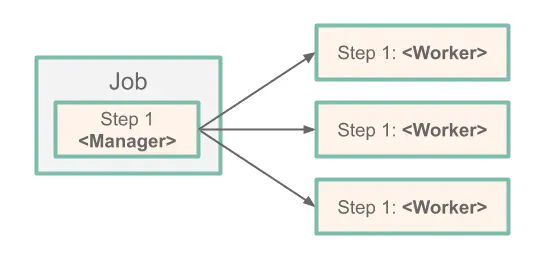
왼편에 있는 Job은 일련의 Step 인스턴스들로 실행된다. 이 경우 하나의 step(Step 1)을 가지는데, 이 step은 파티션에 대한 Manager다. 이 Manager Step은 각 worker에게 작업을 할당하고 실행시키는 일을 담당한다. 이때 worker는 특정 프로파일을 활성화해서 시작되는 또 다른 스프링 배치 애플리케이션 인스턴스다. 이 다이어그램에 있는 worker들은 실제로 플랫폼에 배포된 스프링 배치 애플리케이션의 복사본이다. JobRepository에 있는 스프링 배치 메타데이터 덕분에, Job을 실행할 때마다 각 worker는 딱 한 번씩만 실행된다.
목차
Building our own Batch Application with Partitioning
이번에 다룰 샘플 애플리케이션에선, 단일 step을 가지는 배치 job을 만들고, 이 step을 파티셔닝해서 각 파티션에선 해당 파티션 번호를 출력해본다.
전체 프로젝트는 Spring Cloud Task 샘플 레포지토리에서 확인할 수 있다.
Initializr
배치 애플리케이션을 생성하려면, Spring Initializr 사이트를 방문하고 다음과 같이 프로젝트를 생성해야 한다:
- Spring Initializr site에 접속해라.
- 스프링 부트는 최신 릴리즈를 선택한다.
- 그룹명은
io.spring.cloud, 아티팩트명은partition을 사용해서 새 메이븐 프로젝트를 생성한다. - Dependencies 텍스트 박스에
task를 입력해서 Cloud Task 의존성을 선택한다. - Dependencies 텍스트 박스에
jdbc를 입력해서 JDBC 의존성을 선택한다. - Dependencies 텍스트 박스에
h2를 입력해서H2 의존성을 선택한다.- H2는 단위 테스트에 사용한다.
- Dependencies 텍스트 박스에
mysql을 입력해서 mysql 의존성을 선택한다 (다른 데이터베이스도 괜찮다).- MySQL을 런타임 데이터베이스로 사용한다.
- Dependencies 텍스트 박스에
batch를 입력해서 배치를 선택한다. - Generate Project 버튼을 클릭한다.
partition.zip파일을 다운받고, 압출을 풀고, 즐겨 사용하는 IDE에서 프로젝트를 임포트한다.
Spring Initializr 사이트는 프로젝트의 상세 설정들을 URL 파라미터로 처리하기 때문에, 다음과 같이 진행해도 된다:
- Spring Initializr 링크를 클릭해서 미리 세팅돼 있는 partition.zip을 다운로드한다.
- partition.zip 파일을 다운받고, 압축을 풀고, 프로젝트를 즐겨 사용하는 IDE로 임포트한다.
Setting up MySql
-
사용할 수 있는 MySQL 인스턴스가 없다면, 아래 가이드에 따라 이 예제에서 사용할 MySQL 도커 이미지를 실행하면 된다:
a. MySQL 도커 이미지를 가져온다:
docker pull mysql:5.7.25b. MySql을 실행한다:
docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=password \ -e MYSQL_DATABASE=task -d mysql:5.7.25
Building The Application
애플리케이션을 개발하려면:
-
원하는 IDE에서
io.spring.cloud.partition.configuration패키지를 만들어라. -
원하는 IDE를 사용해서 pom.xml에 아래 의존성을 추가해라.
<dependency> <groupId>org.springframework.batch</groupId> <artifactId>spring-batch-integration</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-deployer-local</artifactId> <version>2.0.2.BUILD-SNAPSHOT</version> </dependency> -
파티션
Job에 필요한 빈들을 구성하는 자바 설정을 작성해라. 여기서는 아래 내용과 같은JobConfiguration클래스를 생성한다 (io.spring.cloud.partition.configuration안에).@Configuration public class JobConfiguration { private static final int GRID_SIZE = 4; @Autowired public JobBuilderFactory jobBuilderFactory; @Autowired public StepBuilderFactory stepBuilderFactory; @Autowired public DataSource dataSource; @Autowired public JobRepository jobRepository; @Autowired private ConfigurableApplicationContext context; @Autowired private DelegatingResourceLoader resourceLoader; @Autowired private Environment environment; @Bean // (1) public PartitionHandler partitionHandler(TaskLauncher taskLauncher, JobExplorer jobExplorer) throws Exception { Resource resource = this.resourceLoader .getResource("maven://io.spring.cloud:partition:0.0.1-SNAPSHOT"); DeployerPartitionHandler partitionHandler = new DeployerPartitionHandler(taskLauncher, jobExplorer, resource, "workerStep"); List<String> commandLineArgs = new ArrayList<>(3); commandLineArgs.add("--spring.profiles.active=worker"); commandLineArgs.add("--spring.cloud.task.initialize.enable=false"); commandLineArgs.add("--spring.batch.initializer.enabled=false"); partitionHandler .setCommandLineArgsProvider(new PassThroughCommandLineArgsProvider(commandLineArgs)); partitionHandler .setEnvironmentVariablesProvider(new SimpleEnvironmentVariablesProvider(this.environment)); partitionHandler.setMaxWorkers(1); partitionHandler.setApplicationName("PartitionedBatchJobTask"); return partitionHandler; } @Bean // (2) @Profile("!worker") public Job partitionedJob(PartitionHandler partitionHandler) throws Exception { Random random = new Random(); return this.jobBuilderFactory.get("partitionedJob" + random.nextInt()) .start(step1(partitionHandler)) .build(); } @Bean // (3) public Step step1(PartitionHandler partitionHandler) throws Exception { return this.stepBuilderFactory.get("step1") .partitioner(workerStep().getName(), partitioner()) .step(workerStep()) .partitionHandler(partitionHandler) .build(); } @Bean // (4) public Partitioner partitioner() { return new Partitioner() { @Override public Map<String, ExecutionContext> partition(int gridSize) { Map<String, ExecutionContext> partitions = new HashMap<>(gridSize); for (int i = 0; i < GRID_SIZE; i++) { ExecutionContext context1 = new ExecutionContext(); context1.put("partitionNumber", i); partitions.put("partition" + i, context1); } return partitions; } }; } @Bean // (5) @Profile("worker") public DeployerStepExecutionHandler stepExecutionHandler(JobExplorer jobExplorer) { return new DeployerStepExecutionHandler(this.context, jobExplorer, this.jobRepository); } @Bean // (6) public Step workerStep() { return this.stepBuilderFactory.get("workerStep") .tasklet(workerTasklet(null)) .build(); } @Bean // (7) @StepScope public Tasklet workerTasklet( final @Value("#{stepExecutionContext['partitionNumber']}") Integer partitionNumber) { return new Tasklet() { @Override public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { System.out.println("This tasklet ran partition: " + partitionNumber); return RepeatStatus.FINISHED; } }; } }(1)
PartitionHandler는Step을 어떻게 분할할지를 알고 있는 컴포넌트다. 리모트 Step들에게StepExecution요청을 전송한다.
(2)Job은 배치 처리를 관리한다.
(3) 이Step은 매니저가 worker step들을 시작할 때 사용하는 step이다.
(4)Partitioner는 step을 새로 실행할 때 사용할 입력 파라미터로 execution 컨텍스트를 생성한다.
(5)DeployerStepExecutionHandler는 Spring Cloud Deployer를 사용해 클라우드 플랫폼에서 worker step 실행을 시작한다.
(6) worker들은 이Step을 사용해서Tasklet을 실행한다.
(7) 파티셔닝된 작업 셋으로 비즈니스 로직(이 예시에선 파티션 번호를 출력하는 일)을 실행하는Tasklet. -
이제 다음과 같이
PartitionApplication클래스에@EnableTask와@EnableBatchProcessing어노테이션을 추가해주면 된다:@SpringBootApplication @EnableTask // (1) @EnableBatchProcessing // (2) public class PartitionApplication { public static void main(String[] args) { SpringApplication.run(PartitionApplication.class, args); } }(1)
@EnableTask어노테이션은 태스크의 시작/종료 시간과 종료 코드같은 태스크 실행에 관한 정보를 저장하는TaskRepository를 설정한다.
(2)@EnableBatchProcessing어노테이션은 스프링 배치 기능들을 활성화하고, 배치 job 세팅을 위한 기본 설정을 제공한다.
Deployment
이 섹션에선 배치 애플리케이션을 배포하는 방법을 다룬다.
Local
여기서는 배치 애플리케이션을 로컬 컴퓨터에 배포하는 방법을 설명한다.
-
이제 프로젝트를 만들어봤으므로, 다음 단계를 진행할 수 있다. 커맨드라인에서 디렉토리를 프로젝트 위치로 변경한 다음 메이븐 명령어
./mvnw clean install -DskipTests를 실행해 프로젝트를 빌드해라. -
이제 배치 애플리케이션을 시작하는 데 필요한 설정들로 애플리케이션을 실행해주면 된다.
배치 애플리케이션의 실행 환경을 설정하려면, 환경 변수에 아래 프로퍼티들을 추가해라:
export spring_datasource_url=jdbc:mysql://localhost:3306/task?useSSL\=false # (1) export spring_datasource_username=root # (2) export spring_datasource_password=password # (3) export spring_datasource_driverClassName=com.mysql.jdbc.Driver # (4) export spring_batch_initializeSchema=always # (5) java -jar target/partition-0.0.1-SNAPSHOT.jar(1) URL을 데이터베이스 인스턴스로 설정해라. 이 예제에선 로컬 시스템의 3306 포트에 있는 MySQL
task데이터베이스에 연결한다.
(2)spring.datasource.username: MySQL 데이터베이스에서 사용할 user name. 이 예제에선root를 사용한다.
(3)spring.datasource.password: MySQL 데이터베이스에서 사용할 password. 이 예제에선password를 사용한다.
(4)spring.datasource.driverClassName: MySQL 데이터베이스에 연결하는 데 사용할 드라이버. 이 예제에선com.mysql.jdbc.Driver를 사용한다.
(5)spring.batch.initializeSchema: 데이터베이스를 스프링 배치에 필요한 테이블들로 초기화한다. 이 예제에선 항상(always) 이 작업을 수행한다고 명시하고 있다. 테이블이 이미 존재할 때는 덮어쓰진 않는다.
Cleanup
도커 인스턴스에서 실행 중인 MySQL 컨테이너를 중지하고 제거하려면 다음 명령어를 실행해라:
docker stop mysql
docker rm mysql
Next : Task and Batch Monitoring with Prometheus and InfluxDB
Task and Batch Monitoring with Prometheus and InfluxDB
태스크 정의를 구성하는 애플리케이션들의 메트릭을 수집하고 모니터링하기
전체 목차는 여기에 있습니다.