스프링 클라우드 데이터 플로우 공식 레퍼런스를 한글로 번역한 문서입니다.
전체 목차는 여기에 있습니다.
이 레시피에선 SFTP 소스에서 파일을 수집하고, 파일 내용을 JDBC 데이터 저장소에 저장하는 Data Flow 파이프라인을 구축하는 방법을 단계별로 소개한다. 이 파이프라인은 SFTP 소스에서 새 파일을 감지할 때마다 태스크를 기동하도록 설계했다. 이때 태스크는 파일을 처리해 각 라인을 대문자로 변환하고 테이블에 삽입하는 스프링 배치 job이다.
스프링 배치 job file ingest는 CSV 텍스트 파일을 읽어와서 JdbcBatchItemWriter를 사용해 데이터베이스 테이블에 각 항목들을 저장한다. CSV 파일에 있는 각 라인은 first_name,last_name 형식을 따르고 있다. JdbcBatchItemWriter는 라인마다 INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)를 수행한다.
소스 코드와 샘플 데이터를 가지고 있는 프로젝트는 브라우저에서 다운받거나 커맨드라인에서 받을 수 있다:
wget https://github.com/spring-cloud/spring-cloud-dataflow-samples/blob/master/dataflow-website/recipes/file-ingest/file-to-jdbc/file-to-jdbc.zip?raw=true -O file-to-jdbc.zip
태스크 애플리케이션을 직접 빌드하고 싶지 않다면, 스프링 메이븐 레포지토리와 springcloud/ingest 도커 레포지토리에 올라가 있는 executable jar를 사용해도 된다.
이 파이프라인은 다음과 같이 미리 패키징해서 제공하는 Spring Cloud Stream 애플리케이션을 사용한다:
- sftp-dataflow-source는 폴링하고 있는 하나 이상의 SFTP 디렉토리에서 새 파일을 감지할 때마다 태스크 시작을 요청하도록 설정돼 있는 SFTP 소스다.
- dataflow-task-launcher-sink는 Data Flow 서버의 REST 클라이언트 역할을 담당하는 싱크로, Data Flow 태스크를 시작한다.
이 파이프라인은 지원하는 모든 Data Flow 플랫폼에서 실행할 수 있다. SFTP 소스는 태스크 시작 요청을 전송하기 전에 SFTP 서버에 있는 각 파일들을 로컬 디렉토리로 다운로드한다. 요청을 전송할 땐 태스크에서 사용할 커맨드라인 인자로 localFilePath를 설정한다. 클라우드 플랫폼에서 실행하려면, SFTP 소스 컨테이너와 태스크 컨테이너에서 사용할 수 있는 공유 디렉토리를 마운트해야 한다. 이 예제에선 NFS 마운트 디렉토리를 세팅한다. NFS 전용 환경과 컨테이너 설정은 플랫폼마다 다르며, 여기서는 Cloud Foundry v2.3+와 minikube를 중심으로 설명한다.
목차
- Prerequisites
- Deployment
- Limiting Concurrent Task Executions
- Avoiding Duplicate Processing
Prerequisites
이 섹션에선 배치 애플리케이션을 시작하기 전에 필요한 세팅과 설정들을 설명한다.
Data Flow Installation
먼저 원하는 플랫폼에 Spring Cloud Data Flow를 설치해놔야 한다:
참고: 쿠버네티스 환경을 설명할 땐 샘플 태스크 애플리케이션에 MySQL을 사용하도록 설정한다. Data Flow 서버도 MySQL 버전으로 구성해야 한다.
Using Data Flow
이 예제에선 Spring Cloud Data Flow 대시보드나 Spring Cloud Data Flow 쉘을 사용해서 애플리케이션을 등록하고 배포하는 방법을 알고 있다고 가정한다. Data Flow 사용법에 대한 자세한 안내가 필요하다면 Spring Cloud Data Flow를 이용한 스트림 처리와 Spring Cloud Data Flow를 이용해서 배치 애플리케이션을 등록하고 실행하기를 읽어보면 된다.
SFTP server
이 예제에선 SFTP 서버에 액세스해야 한다. 로컬 머신이나 minikube에서 실행할 땐, 호스트 머신을 SFTP 서버로 사용한다. 클라우드 파운드리와 쿠버네티스에선 보통 외부 SFTP 서버가 필요하다. SFTP 서버에서 /remote-files 디렉토리를 생성해라. 이 디렉토리에 파이프라인을 트리거할 파일을 저장할 거다.
NFS configuration
로컬에서 실행할 땐 NFS가 필요하지 않다.
Cloud Foundry NFS configuration
이 기능은 Pivotal Cloud Foundry의 NFS 볼륨 서비스에서 제공하는 기능이다.
이 예제를 실행하려면 다음과 같은 환경이 필요하다:
- NFS 볼륨 서비스가 활성화된 클라우드 파운드리 인스턴스 (v2.3+)
- 클라우드 파운드리 인스턴스에서 접근할 수 있는 NFS 서버
- 적절히 설정해둔
nfs서비스 인스턴스
참고: 이 예제에선 간단히 다음과 같은 공통 설정으로
nfs서비스를 생성하고, 바인딩할 모든 앱에 공통 마운트 포인트(/var/scdf)를 사용한다고 가정한다. 이런 파라미터들은 NFS 서비스를 애플리케이션에 바인딩할 때 배포 프로퍼티를 사용해서 설정할 수도 있다:cf create-service nfs Existing nfs -c '{"share":<nfs-host>/staging","uid":<uid>,"gid":<gid>, "mount":"/var/scdf"}'
Kubernetes NFS configuration
쿠버네티스는 persistent 볼륨을 설정하고 공유할 수 있는 다양한 옵션을 제공한다. 이 예제에서는 minikube를 사용하며, 호스트 머신을 NFS 서버로 사용한다. 아래 가이드는 OS/X에서 잘 동작하며, Linux 호스트에서도 유사할 거다.
먼저 minikube를 시작해야 한다. 여기 있는 명령어들은 minikube VM이 NFS에 접근할 수 있게 해주는 명령어다. minikube IP는 시작할 때마다 변경될 수 있으므로, 여기서 설명하는 설정들은 재시작할 때마다 세팅해줘야 한다.
공유 디렉토리 /staging을 노출한다.
sudo mkdir /staging
sudo chmod 777 /staging
sudo echo "/staging -alldirs -mapall="$(id -u)":"$(id -g)" $(minikube ip)" >> /etc/exports
sudo nfsd restart
NFS 마운트를 검증해보자:
showmount -e 127.0.0.1
Exports list on 127.0.0.1:
/staging 192.168.99.105
persistent 볼륨과 persistent 볼륨 클레임 리소스를 설정한다. 아래 있는 내용을 복사해서 nfs-config.yml 파일에 저장해라:
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-volume
spec:
capacity:
storage: 4Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: standard
nfs:
# The address 192.168.99.1 is the Minikube gateway to the host for VirtualBox. This way
# not the container IP will be visible by the NFS server on the host machine,
# but the IP address of the `minikube ip` command. You will need to
# grant access to the `minikube ip` IP address.
server: 192.168.99.1
path: '/staging'
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nfs-volume-claim
namespace: default
spec:
storageClassName: standard
accessModes:
- ReadWriteMany
resources:
requests:
storage: 4Gi
이제 이 리소스들을 생성한다:
kubectl apply -f nfs-config.yml
Deployment
이 섹션에선 스트림을 아래 환경들로 배포하는 방법을 설명한다:
Local
이 예제는 로컬 배포에선 카프카를 메세지 브로커로 사용한다. 리모트 파일과 로컬 파일을 저장할 디렉토리를 생성해라:
mkdir -p /tmp/remote-files /tmp/local-files
Register the Applications
샘플 프로젝트를 다운받아서 빌드했다면 file:// URL을 통해 애플리케이션을 등록할 수 있다. ex. file://<path-to-project>/target/ingest-1.0.0-SNAPSHOT.jar. 다운받지 않았다면 레포지토리에 올라가 있는 메이븐 jar를 사용하면 된다:
app register --name fileIngest --type task --uri maven://io.spring.cloud.dataflow.ingest:ingest:1.0.0.BUILD-SNAPSHOT
기본 제공하는 sftp 소스와 task-launcher 싱크 애플리케이션을 등록한다:
app register --name sftp --type source --uri maven://org.springframework.cloud.stream.app:sftp-dataflow-source-kafka:2.1.0.RELEASE
app register --name task-launcher --type sink --uri maven://org.springframework.cloud.stream.app:task-launcher-dataflow-sink-kafka:1.0.1.RELEASE
Create the Task
태스크를 생성하려면 아래 명령어를 실행해라:
task create fileIngestTask --definition fileIngest
Create and Deploy the Stream
스트림을 배포하려면 아래 명령어를 실행해라:
참고:
<user>과<pass>는 각자 알아서 변경해야 한다.username과password는 로컬(또는 원격) 사용자를 위한 credentail이다. 로컬 SFTP 서버를 사용하지 않는다면,host파라미터로 (필요하면port파라미터도) 호스트를 지정해라. 따로 정의하지 않았을 때host의 기본값은127.0.0.1,port의 기본값은22다.
stream create --name inboundSftp --definition "sftp --username=<user> --password=<pass> --allow-unknown-keys=true --task.launch.request.taskName=fileIngestTask --remote-dir=/tmp/remote-files/ --local-dir=/tmp/local-files/ | task-launcher" --deploy
dataflow-task-launcher-sink는
PollableMessageSource를 사용해 폴링하는데, 이 메세지 소스는 exponential backoff를 사용하는 다이나믹 트리거로 제어한다. 이 싱크는 기본적으로 입력 목적지를 1초 간격으로 폴링한다. 태스크 시작 요청이 없을 때는 폴링 주기를 최대 30초까지 두 배로 연장시킨다. 태스크 시작 요청이 있으면 트리거는 1초로 재설정된다. 스트림을 정의할 때 트리거에서 사용할task-launcher싱크 프로퍼티trigger.period와trigger.max-period를 설정해서 진행해도 된다.
Verify Stream deployment
배포할 스트림의 상태는 아래 예시와 같이 stream list로 확인할 수 있다:
dataflow:>stream list
╔═══════════╤════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╤════════════════════════════╗
║Stream Name│ Stream Definition │ Status ║
╠═══════════╪════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╪════════════════════════════╣
║inboundSftp│sftp --password='******' --remote-dir=/tmp/remote-files/ --local-dir=/tmp/local-files/ --task.launch.request.taskName=fileIngestTask│The stream has been ║
║ │--allow-unknown-keys=true --username=<user> | task-launcher │successfully deployed ║
╚═══════════╧════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╧════════════════════════════╝
Inspect the Application Logs
스트림이 배포에 실패했거나 어떤 이유든지 로그를 살펴보고 싶을 땐, runtime apps 명령어를 사용하면 inboundSftp 스트림으로 생성한 애플리케이션들의 로그가 저장되는 곳을 확인할 수 있다:
dataflow:>runtime apps
╔═══════════════════════════╤═══════════╤════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╗
║ App Id / Instance Id │Unit Status│ No. of Instances / Attributes ║
╠═══════════════════════════╪═══════════╪════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╣
║inboundSftp.sftp │ deployed │ 1 ║
║ │ │ guid = 23057 ║
║ │ │ pid = 71927 ║
║ │ │ port = 23057 ║
╟───────────────────────────┼───────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║inboundSftp.sftp-0 │ deployed │ stderr = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540821009913/inboundSftp.sftp/stderr_0.log ║
║ │ │ stdout = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540821009913/inboundSftp.sftp/stdout_0.log ║
║ │ │ url = http://192.168.64.1:23057 ║
║ │ │working.dir = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540821009913/inboundSftp.sftp ║
╟───────────────────────────┼───────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║inboundSftp.task-launcher │ deployed │ 1 ║
╟───────────────────────────┼───────────┼────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╢
║ │ │ guid = 60081 ║
║ │ │ pid = 71926 ║
║ │ │ port = 60081 ║
║inboundSftp.task-launcher-0│ deployed │ stderr = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540820991695/inboundSftp.task-launcher/stderr_0.log║
║ │ │ stdout = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540820991695/inboundSftp.task-launcher/stdout_0.log║
║ │ │ url = http://192.168.64.1:60081 ║
║ │ │working.dir = /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/spring-cloud-deployer-120915912946760306/inboundSftp-1540820991695/inboundSftp.task-launcher ║
╚═══════════════════════════╧═══════════╧════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╝
Copying a File into the Remote Directory
SFTP 서버가 있었다면 이 서버에 데이터를 업로드했을 거다. 여기서는 파일을 --remote-dir로 지정한 디렉토리에 복사하는 식으로 시뮬레이션해보겠다. 샘플 데이터는 샘플 프로젝트의 data/ 디렉토리에서 찾을 수 있다.
data/name-list.csv를 SFTP 소스가 모니터링하는 /tmp/remote-files 디렉토리에 복사해라. sftp 소스는 이 파일을 감지하면 --local-dir에 지정한 /tmp/local-files 디렉토리에 다운받고 태스크 시작 요청을 전송한다. 태스크 시작 요청에는 기동시킬 태스크 이름과 커맨드라인 인자로 사용할 로컬 파일 경로가 담겨있다. 스프링 배치는 커맨드라인 인자들을 각각 JobParameter에 바인딩한다. FileIngestTask job은 localFilePath라는 JobParameter에 지정한 파일을 처리한다. 한동안 요청이 없었기 때문에, 요청을 전송한 후 30초 내로 태스크가 기동될 거다 (앞에서 보여준 트리거 설정 관련 팁을 참고해라).
cp data/name-list.csv /tmp/remote-files
배치 job을 시작하면 SCDF 콘솔 로그에서 다음과 같은 문구를 확인할 수 있을 거다:
2018-10-26 16:47:24.879 INFO 86034 --- [nio-9393-exec-7] o.s.c.d.spi.local.LocalTaskLauncher : Command to be executed: /Library/Java/JavaVirtualMachines/jdk1.8.0_60.jdk/Contents/Home/jre/bin/java -jar <path-to>/batch/file-ingest/target/ingest-1.0.0.jar localFilePath=/tmp/local-files/name-list.csv --spring.cloud.task.executionid=1
2018-10-26 16:47:25.100 INFO 86034 --- [nio-9393-exec-7] o.s.c.d.spi.local.LocalTaskLauncher : launching task fileIngestTask-8852d94d-9dd8-4760-b0e4-90f75ee028de
Logs will be in /var/folders/hd/5yqz2v2d3sxd3n879f4sg4gr0000gn/T/fileIngestTask3100511340216074735/1540586844871/fileIngestTask-8852d94d-9dd8-4760-b0e4-90f75ee028de
Inspect Job Executions
데이터를 받아 배치 job이 실행되고 나면 실행 내역이 기록된다. Spring Cloud Data Flow 쉘에서 다음 명령어를 실행하면 job 실행 내역들을 조회할 수 있다:
dataflow:>job execution list
╔═══╤═══════╤═════════╤════════════════════════════╤═════════════════════╤══════════════════╗
║ID │Task ID│Job Name │ Start Time │Step Execution Count │Definition Status ║
╠═══╪═══════╪═════════╪════════════════════════════╪═════════════════════╪══════════════════╣
║1 │1 │ingestJob│Tue May 01 23:34:05 EDT 2018│1 │Created ║
╚═══╧═══════╧═════════╧════════════════════════════╧═════════════════════╧══════════════════╝
특정 job 실행 내역을 자세히 들여다볼 수도 있다:
dataflow:>job execution display --id 1
╔═══════════════════════════════════════╤══════════════════════════════╗
║ Key │ Value ║
╠═══════════════════════════════════════╪══════════════════════════════╣
║Job Execution Id │1 ║
║Task Execution Id │1 ║
║Task Instance Id │1 ║
║Job Name │ingestJob ║
║Create Time │Fri Oct 26 16:57:51 EDT 2018 ║
║Start Time │Fri Oct 26 16:57:51 EDT 2018 ║
║End Time │Fri Oct 26 16:57:53 EDT 2018 ║
║Running │false ║
║Stopping │false ║
║Step Execution Count │1 ║
║Execution Status │COMPLETED ║
║Exit Status │COMPLETED ║
║Exit Message │ ║
║Definition Status │Created ║
║Job Parameters │ ║
║-spring.cloud.task.executionid(STRING) │1 ║
║run.id(LONG) │1 ║
║localFilePath(STRING) │/tmp/local-files/name-list.csv║
╚═══════════════════════════════════════╧══════════════════════════════╝
Verify Data
배치 job이 실행되면 로컬 디렉토리(/tmp/local-files)에 있는 파일을 처리하고, 각 항목마다 이름을 대문자로 변환한 뒤 데이터베이스에 저장한다.
데이터를 점검해볼 땐 H2 데이터베이스를 지원하는 아무 데이터베이스 툴이나 이용하면 된다. 이 예시에선 DBeaver 데이터베이스 툴을 사용한다. 테이블을 조회해서 데이터를 올바르게 처리했는지 검증하면 된다.
DBeaver를 실행해서 데이터베이스 커넥션을 생성해라. 이땐 JDBC URL엔 jdbc:h2:tcp://localhost:19092/mem:dataflow를, username엔 sa를 입력하고, 비밀번호는 비워두면 된다. 연결되면 PUBLIC 스키마를 누르고 Tables를 누른 다음, PEOPLE 테이블을 더블 클릭한다. 테이블 데이터가 로드되면 Data 탭을 클릭해서 데이터를 조회해봐라.
Cloud Foundry
이 섹션에선 클라우드 파운드리 환경에 스프링 배치와 Spring Cloud Data Flow를 세팅하고, 배치 프로세스 예제를 생성하는 방법을 설명한다.
Prerequisites
클라우드 파운드리에서 이 예제를 실행하려면 다음과 같은 환경이 필요하다:
- 클라우드 파운드리 NFS 설정 섹션에서 설명했던 NFS 서버 세팅과, 액세스할 수 있는
nfs서비스 /remote-files디렉토리를 가지고 있는 외부 SFTP 서버mysql서비스 인스턴스rabbit서비스 인스턴스- 데이터를 조회할 수 있는 PivotalMySQLWeb이나 다른 데이터베이스 툴
Register the Applications
샘플 애플리케이션을 등록할 땐 아래 명령어를 사용해라:
app register --name fileIngest --type task --uri maven://io.spring.cloud.dataflow.ingest:ingest:1.0.0.BUILD-SNAPSHOT
그 다음 기본 제공하는 sftp 소스와 task-launcher 싱크 애플리케이션을 등록한다:
app register --name sftp --type source --uri maven://org.springframework.cloud.stream.app:sftp-dataflow-source-kafka:2.1.0.RELEASE
app register --name task-launcher --type sink --uri maven://org.springframework.cloud.stream.app:task-launcher-dataflow-sink-kafka:1.0.1.RELEASE
Create the Task
태스크를 생성하려면 아래 명령어를 실행해라:
task create fileIngestTask --definition fileIngest
Create the Stream
sftp 소스는 fileIngestTask의 실행을 요청하도록 설정한다. 시작 요청에선 배포 프로퍼티 task.launch.request.deployment-properties=deployer.*.cloudfoundry.services=nfs를 사용해서 nfs 서비스를 태스크 컨테이너에 바인딩한다.
참고: 아래 스트림 정의에서 보이는
<user>,<pass>,<host>,<data-flow-server-uri>는 각자 알아서 변경해야 한다.
stream create --name inboundSftp --definition "sftp --username=<user> --password=<pass> --host=<host> --allow-unknown-keys=true --remote-dir=/remote-files/ --local-dir=/var/scdf/shared-files/ --task.launch.request.taskName=fileIngestTask --task.launch.request.deployment-properties=deployer.*.cloudfoundry.services=nfs | task-launcher --spring.cloud.dataflow.client.server-uri=<data-flow-server-uri>"
dataflow-task-launcher-sink는
PollableMessageSource를 사용해 폴링하는데, 이 메세지 소스는 exponential backoff를 사용하는 다이나믹 트리거로 제어한다. 이 싱크는 기본적으로 입력 목적지를 1초 간격으로 폴링한다. 태스크 시작 요청이 없을 때는 폴링 주기를 최대 30초까지 두 배로 연장시킨다. 태스크 시작 요청이 있으면 트리거는 1초로 재설정된다. 스트림을 정의할 때 트리거에서 사용할task-launcher싱크 프로퍼티trigger.period와trigger.max-period를 설정해서 진행해도 된다.
Deploy the stream
스트림을 배포할 땐 반드시 아래 명령어로 sftp 포드도 설정해줘야 한다:
stream deploy inboundSftp --properties "deployer.sftp.cloudfoundry.services=nfs"
Verify Stream Deployment
배포한 스트림의 상태는 아래 예시와 같이 stream list로 확인할 수 있다:
dataflow:>stream list
╔═══════════╤═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╤═══════════════════╗
║Stream Name│ Stream Definition │ Status ║
╠═══════════╪═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╪═══════════════════╣
║inboundSftp│sftp --task.launch.request.deployment-properties='deployer.*.cloudfoundry.services=nfs' --sftp.factory.password='******' --sftp.local-dir=/var/scdf/shared-files/ │The stream has been║
║ │--sftp.factory.allow-unknown-keys=true --sftp.factory.username='******' --sftp.remote-dir=/remote-files/ --sftp.factory.host=<host> --task.launch.request.taskName=fileIngestTask | │successfully ║
║ │task-launcher --spring.cloud.dataflow.client.server-uri=<data-flow-server-uri │deployed ║
╚═══════════╧═══════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╧═══════════════════╝
Inspect the Application Logs
클라우드 파운드리 CLI를 사용해서 앱들을 조회해보자. source, sink 애플리케이션은 started 상태에 있어야 한다.
cf apps
Getting apps in org myorg / space myspace as someuser...
OK
name requested state instances memory disk urls
...
Ky7Uk6q-inboundSftp-sftp-v1 started 1/1 2G 1G Ky7Uk6q-inboundSftp-sftp-v1.apps.hayward.cf-app.com
Ky7Uk6q-inboundSftp-task-launcher-v1 started 1/1 2G 1G Ky7Uk6q-inboundSftp-task-launcher-v1.apps.hayward.cf-app.com
...
SFTP 커넥션 실패같은 이슈를 디버깅하고 SFTP 다운로드를 검증할 땐 sftp 소스의 로그 파일을 확인해보는 게 좋다. 로그를 조회하려면 아래 명령어를 실행해라:
cf logs Ky7Uk6q-inboundSftp-sftp-v1 --recent
data flow 커넥션 이슈를 디버깅하고 태스크 시작 요청을 검증할 땐 task-launcher 애플리케이션의 로그를 확인해보면 된다:
cf logs Ky7Uk6q-inboundSftp-task-launcher-v1 --recent
Copy a File into the Remote Directory
샘플 데이터는 샘플 프로젝트의 data/ 디렉토리에서 찾을 수 있다.
SFTP 서버에 연결하고 remote-files 디렉토리에 data/name-list.csv를 업로드해라.
sftp 소스는 이 파일을 감지하면 --local-dir에 지정한 /var/scdf/shared-files 디렉토리에 다운받는다. 여기선 nfs 서비스에 설정했던 공유 마운트 경로 /var/scdf를 사용한다. 파일이 다운로드되면 소스는 태스크 시작 요청을 전송한다. 태스크 시작 요청에는 기동시킬 태스크 이름과 커맨드라인 인자로 사용할 로컬 파일 경로가 담겨있다. 스프링 배치는 커맨드라인 인자들을 각각 JobParameter에 바인딩한다. FileIngestTask job은 localFilePath라는 JobParameter에 지정한 파일을 처리한다. 한동안 요청이 없었기 때문에, 요청을 전송한 후 30초 내로 태스크가 기동될 거다 (앞에서 보여준 트리거 설정 관련 팁을 참고해라).
Inspect Job Executions
job 실행 내역들을 확인해보려면 아래 명령어를 사용해라 (실행 결과도 함께 표기했다):
dataflow:>job execution list
╔═══╤═══════╤═════════╤════════════════════════════╤═════════════════════╤══════════════════╗
║ID │Task ID│Job Name │ Start Time │Step Execution Count │Definition Status ║
╠═══╪═══════╪═════════╪════════════════════════════╪═════════════════════╪══════════════════╣
║1 │1 │ingestJob│Tue Jun 11 15:56:27 EDT 2019│1 │Created ║
╚═══╧═══════╧═════════╧════════════════════════════╧═════════════════════╧══════════════════╝
특정 job 실행 내역을 자세히 들여다볼 수도 있다:
dataflow:>job execution display --id 1
╔═══════════════════════════════════════╤════════════════════════════════════╗
║ Key │ Value ║
╠═══════════════════════════════════════╪════════════════════════════════════╣
║Job Execution Id │6 ║
║Task Execution Id │6 ║
║Task Instance Id │6 ║
║Job Name │ingestJob ║
║Create Time │Thu Jun 13 17:06:28 EDT 2019 ║
║Start Time │Thu Jun 13 17:06:29 EDT 2019 ║
║End Time │Thu Jun 13 17:06:57 EDT 2019 ║
║Running │false ║
║Stopping │false ║
║Step Execution Count │1 ║
║Execution Status │COMPLETED ║
║Exit Status │COMPLETED ║
║Exit Message │ ║
║Definition Status │Created ║
║Job Parameters │ ║
║-spring.cloud.task.executionid(STRING) │1 ║
║run.id(LONG) │1 ║
║localFilePath(STRING) │/var/scdf/shared-files/name-list.csv║
╚═══════════════════════════════════════╧════════════════════════════════════╝
Verify Data
배치 job이 실행되면 로컬 디렉토리(/var/scdf/shared-files)에 있는 파일을 처리하고, 각 항목마다 이름을 대문자로 변환한 뒤 데이터베이스에 저장한다.
데이터를 점검해볼 땐 PivotalMySQLWeb을 사용하면 된다.
Kubernetes
이 섹션에선 쿠버네티스 환경에 스프링 배치와 Spring Cloud Data Flow를 세팅하고, 배치 프로세스 예제를 생성하는 방법을 설명한다.
Prerequisites
이 예제에선 Minikube에 Data Flow를 카프카, MySQL과 함께 설치했다고 가정한다. 설치할 때는 헬름 차트를 이용하는 걸 권장한다. 아래 명령어로 시작하면 된다:
helm install --name my-release --set kafka.enabled=true,rabbitmq.enabled=false,server.service.type=NodePort stable/spring-cloud-data-flow
쿠버네티스에서 이 예제를 실행하려면, 쿠버네티스 NFS 설정 섹션에서 설명한대로 NFS 서버를 세팅하고 그에 따라 persistent volume과 persistent volume claim을 생성해야 한다. /remote-files 디렉토리를 가지고 있는 외부 SFTP 서버도 하나 필요하다.
Register the Applications
샘플 프로젝트를 다운받았다면 도커 이미지를 빌드하고 Minikube 레지스트리에 게시하면 된다:
eval $(minikube docker-env)
./mvnw clean package docker:build -Pkubernetes
다운받지 않았다면, 빌드 단계는 생략하고 도커허브에 올라가 있는 이미지를 받아오면 된다:
app register --name fileIngest --type task --uri docker://springcloud/ingest
기본 제공하는 sftp 소스와 task-launcher 싱크 애플리케이션을 등록한다:
app register --name sftp --type source --uri docker://springcloudstream/sftp-dataflow-source-kafka:2.1.0.RELEASE --metadata-uri maven://org.springframework.cloud.stream.app:sftp-dataflow-source-kafka:jar:metadata:2.1.0.RELEASE
app register --name task-launcher --type sink --uri docker://springcloudstream/task-launcher-dataflow-sink-kafka:1.0.1.RELEASE --metadata-uri maven://org.springframework.cloud.stream.app:task-launcher-dataflow-sink-kafka:jar:metadata:1.0.1.RELEASE
Create the Task
태스크를 생성하려면 아래 명령어를 실행해라:
task create fileIngestTask --definition fileIngest
Create the Stream
sftp 소스는 fileIngestTask의 실행을 요청하도록 설정한다. 시작 요청에선 배포 프로퍼티 deployer.*.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs-volume-claim'}}]과 deployer.*.kubernetes.volumeMounts=[{'mountPath':'/staging/shared-files','name':'staging'}]을 사용해서 NFS 공유 디렉토리를 태스크 포드에 바인딩한다.
참고: 아래 스트림 정의에서 보이는
<user>,<pass>,<data-flow-server-uri>는 각자 알아서 변경해야 한다. 여기서 사용한<host>값은 VirtualBox의 디폴트 Minikube 게이트웨이다.
<data-flow-server-uri>를 확인하려면, 서비스 이름을 찾아 minikube service 명령어를 실행하면 된다:
kubectl get svc
...
my-release-data-flow-server NodePort 10.97.74.123 <none> 80:30826/TCP
minikube service my-release-data-flow-server --url
http://192.168.99.105:30826
stream create inboundSftp --definition "sftp --host=192.168.99.1 --username=<user> --password=<pass> --allow-unknown-keys=true --remote-dir=/remote-files --local-dir=/staging/shared-files --task.launch.request.taskName=fileIngestTask --task.launch.request.deployment-properties=deployer.*.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs-volume-claim'}}],deployer.*.kubernetes.volumeMounts=[{'mountPath':'/staging/shared-files','name':'staging'}] | task-launcher --spring.cloud.dataflow.client.server-uri=<dataflow-uri>"
dataflow-task-launcher-sink는
PollableMessageSource를 사용해 폴링하는데, 이 메세지 소스는 exponential backoff를 사용하는 다이나믹 트리거로 제어한다. 이 싱크는 기본적으로 입력 목적지를 1초 간격으로 폴링한다. 태스크 시작 요청이 없을 때는 폴링 주기를 최대 30초까지 두 배로 연장시킨다. 태스크 시작 요청이 있으면 트리거는 1초로 재설정된다. 스트림을 정의할 때 트리거에서 사용할task-launcher싱크 프로퍼티trigger.period와trigger.max-period를 설정해서 진행해도 된다.
Deploy the Stream
스트림을 배포할 땐 반드시 sftp 소스를 위한 볼륨 마운트도 설정해줘야 한다:
stream deploy inboundSftp --properties "deployer.sftp.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs-volume-claim'}}],deployer.sftp.kubernetes.volumeMounts=[{'mountPath':'/staging/shared-files','name':'staging'}]"
Verify Stream Deployment
배포한 스트림의 상태는 아래 예시와 같이 stream list로 확인할 수 있다:
dataflow:>stream list
╔═══════════╤═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╤════════════╗
║Stream Name│ Stream Definition │ Status ║
╠═══════════╪═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╪════════════╣
║inboundSftp│sftp │The stream ║
║ │--task.launch.request.deployment-properties="deployer.*.kubernetes.volumes=[{'name':'staging','persistentVolumeClaim':{'claimName':'nfs-volume-claim'}}],deployer.*.kubernetes.volumeMounts=[{'mountPath':'/staging/shared-files','name':'staging'}]"│has been ║
║ │--sftp.factory.password='******' --sftp.local-dir=/staging/shared-files --sftp.factory.allow-unknown-keys=true --sftp.factory.username='******' --sftp.remote-dir=/remote-files --sftp.factory.host=192.168.99.1 │successfully║
║ │--task.launch.request.taskName=fileIngestTask | task-launcher --spring.cloud.dataflow.client.server-uri=http://192.168.99.105:30826 │deployed ║
╚═══════════╧═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╧════════════╝
Inspect the Application Logs
kubectl을 사용해서 앱들을 조회해보자. source, sink 애플리케이션은 started 상태에 있어야 한다.
kubectl get pods
NAME READY STATUS RESTARTS AGE
...
inboundsftp-sftp-v12-6d55d469bd-t8znd 1/1 Running 0 6m24s
inboundsftp-task-launcher-v12-555d4785c5-zjr6b 1/1 Running 0 6m24s
...
SFTP 커넥션 실패같은 이슈를 디버깅하고 SFTP 다운로드를 검증할 땐 sftp 소스의 로그 파일을 확인해보는 게 좋다.
kubectl logs inboundsftp-sftp-v12-6d55d469bd-t8znd
data flow 커넥션 이슈를 디버깅하고 태스크 시작 요청을 검증할 땐 task-launcher 애플리케이션의 로그를 확인해보면 된다:
kubectl logs inboundsftp-task-launcher-v12-555d4785c5-zjr6b
Copy a File into the Remote Directory
샘플 데이터는 샘플 프로젝트의 data/ 디렉토리에서 찾을 수 있다.
SFTP 서버에 연결하고 remote-files 디렉토리에 data/name-list.csv를 업로드해라.
sftp 소스는 이 파일을 감지하면 --local-dir에 지정한 /staging/shared-files 디렉토리에 다운받는다. 여기선 nfs 서비스에 설정했던 공유 마운트 경로 /staging을 사용한다. 파일이 다운로드되면 소스는 태스크 시작 요청을 전송한다. 태스크 시작 요청에는 기동시킬 태스크 이름과 커맨드라인 인자로 사용할 로컬 파일 경로가 담겨있다. 스프링 배치는 커맨드라인 인자들을 각각 JobParameter에 바인딩한다. FileIngestTask job은 localFilePath라는 JobParameter에 지정한 파일을 처리한다. 한동안 요청이 없었기 때문에, 요청을 전송한 후 30초 내로 태스크가 기동될 거다 (앞에서 보여준 트리거 설정 관련 팁을 참고해라).
Inspect Job Executions
job 실행 내역들을 확인해보려면 아래 명령어를 사용해라 (실행 결과도 함께 표기했다):
dataflow:>job execution list
╔═══╤═══════╤═════════╤════════════════════════════╤═════════════════════╤══════════════════╗
║ID │Task ID│Job Name │ Start Time │Step Execution Count │Definition Status ║
╠═══╪═══════╪═════════╪════════════════════════════╪═════════════════════╪══════════════════╣
║1 │1 │ingestJob│Thu Jun 13 08:39:59 EDT 2019│1 │Created ║
╚═══╧═══════╧═════════╧════════════════════════════╧═════════════════════╧══════════════════╝
특정 job 실행 내역을 자세히 들여다볼 수도 있다:
dataflow:>job execution display --id 1
╔═══════════════════════════════════════════╤═══════════════════════════════════╗
║ Key │ Value ║
╠═══════════════════════════════════════════╪═══════════════════════════════════╣
║Job Execution Id │1 ║
║Task Execution Id │424 ║
║Task Instance Id │1 ║
║Job Name │ingestJob ║
║Create Time │Thu Jun 13 08:39:59 EDT 2019 ║
║Start Time │Thu Jun 13 08:39:59 EDT 2019 ║
║End Time │Thu Jun 13 08:40:07 EDT 2019 ║
║Running │false ║
║Stopping │false ║
║Step Execution Count │1 ║
║Execution Status │COMPLETED ║
║Exit Status │COMPLETED ║
║Exit Message │ ║
║Definition Status │Created ║
║Job Parameters │ ║
║-spring.cloud.task.executionid(STRING) │424 ║
║run.id(LONG) │1 ║
║-spring.datasource.username(STRING) │****** ║
║-spring.cloud.task.name(STRING) │fileIngestTask ║
║-spring.datasource.password(STRING) │****** ║
║-spring.datasource.driverClassName(STRING) │org.mariadb.jdbc.Driver ║
║localFilePath(STRING) │/staging/shared-files/name-list.csv║
║-spring.datasource.url(STRING) │****** ║
╚═══════════════════════════════════════════╧═══════════════════════════════════╝
Verify Data
배치 job이 실행되면 로컬 디렉토리(/staging/shared-files)에 있는 파일을 처리하고, 각 항목마다 이름을 대문자로 변환한 뒤 데이터베이스에 저장한다.
mysql 컨테이너에서 쉘을 열고 people 테이블에 질의를 날려보자:
kubectl get pods
...
my-release-mysql-56f988dd6c-qlm8q 1/1 Running
...
kubectl exec -it my-release-mysql-56f988dd6c-qlm8q -- /bin/bash
# mysql -u root -p$MYSQL_ROOT_PASSWORD
mysql> select * from dataflow.people;
+-----------+------------+-----------+
| person_id | first_name | last_name |
+-----------+------------+-----------+
| 1 | AARON | AABERG |
| 2 | AARON | AABY |
| 3 | ABBEY | AADLAND |
| 4 | ABBIE | AAGAARD |
| 5 | ABBY | AAKRE |
| 6 | ABDUL | AALAND |
| 7 | ABE | AALBERS |
| 8 | ABEL | AALDERINK |
| 9 | ABIGAIL | AALUND |
| 10 | ABRAHAM | AAMODT |
| ... |
+-----------+------------+-----------+
Limiting Concurrent Task Executions
이 레시피에선 아이템이 5000개 이상 들어있는 단일 파일을 처리한다. 원격 디렉토리에 100개의 파일을 저장하면 어떻게 될까? sftp 소스는 이 파일도 즉시 처리해서 태스크 시작 요청을 100번 전송한다. Dataflow 서버는 태스크를 비동기로 실행하기 때문에 런타임 플랫폼의 리소스 가용량을 넘어가 버릴 수도 있다. 예를 들어서 Data Flow 서버를 로컬 머신에서 실행한다면, 태스크를 실행할 때마다 JVM을 새로 생성한다. 클라우드 파운드리에선 각 태스크마다 새 컨테이너 인스턴스를, 쿠버네티스에선 새 포드를 생성한다.
다행히도 Spring Cloud Data Flow는 동시에 실행하는 태스크 수를 제한할 수 있는 설정을 제공한다.
같은 샘플로 동작 방식을 확인해보자.
Lower the Maximum Concurrent Task Executions
샘플 프로젝트는 data/spilt 디렉토리에 20개의 파일이 들어 있다. 태스크 실행이 실제로 제한되는지 확인해보기 위해, 최대 동시 태스크 수를 3으로 설정해보자.
로컬 서버에서 태스크를 실행하려면 서버를 재시작하고 아래 커맨드라인 인자를 추가해라: spring.cloud.dataflow.task.platform.local.accounts[default].maximum-concurrent-tasks=3.
클라우드 파운드리 환경에서 실행한다면 아래 명령어를 실행해라:
cf set-env <dataflow-server> SPRING_CLOUD_DATAFLOW_TASK_PLATFORM_CLOUDFOUNDRY_ACCOUNTS[DEFAULT]_DEPLOYMENT_MAXIMUMCONCURRENTTASKS 3
쿠버네티스 환경에서 실행한다면 아래 명령어를 실행해서 Data Flow 서버 configmap을 수정해라:
kubectl edit configmap my-release-data-flow-server
다음과 같이 maximum-concurrent-tasks 프로퍼티를 추가하면 된다:
apiVersion: v1
data:
application.yaml: |-
spring:
cloud:
dataflow:
task:
platform:
kubernetes:
accounts:
default:
maximum-concurrent-tasks: 3
limits:
memory: 1024Mi
cpu: 500m
configmap을 수정한 다음엔 Data Flow 서버를 강제로 재시작하도록 포드를 삭제해라. 이제 재시작될 때까지 기다리면 된다.
Verify that the Maximum Concurrent Task Executions is Enforced
task launcher 싱크는 입력 목적지를 폴링한다. 폴링 주기는 태스크 시작 요청이 있는지에 따라 조절하는데, 사실 Data Flow 서버의 tasks/executions/current REST 엔드포인트에서 알아낸 현재 실행 중인 태스크 수에 따라서도 조절한다. 싱크에선 이 엔드포인트에서 태스크 실행 정보를 가져온 뒤, 태스크 플랫폼에서 실행 중인 태스크 수가 제한치에 도달하면, 폴링을 잠시 중단하고 새 요청을 보내지 않는다. 복원력resilience을 위해 약간의 성능을 희생하므로, 태스크 시작 요청을 만드는 시점과 요청을 실행하는 시점 사이에 1-30초 정도 지연lag이 생긴다. DLQdead letter queue가 발생했을 때는 서버가 요청을 처리할 수 없을 정도로 바쁘거나 응답을 받을 수 없는 상황이기 때문에, 절대 태스크 시작 요청을 전송하지 않다. exponential backoff도 태스크 시작 요청이 없을 땐 이 앱이 서버에 과도하게 질의를 보내지 않도록 막아준다.
Monitor the Task Executions
tail 명령어를 통해 task-launcher 컨테이너 로그를 확인해봐라.
현재 Data Flow 서버의 태스크 실행 정보를 모니터링해봐도 된다:
watch curl <dataflow-server-url>/tasks/executions/current
Every 2.0s: curl http://192.168.99.105:30826/tasks/executions/current
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0100 92 0 92 0 0 1202 0 --:--:-- --:--:-- --:--:
-- 1210
[{"name":"default","type":"Kubernetes","maximumTaskExecutions":3,"runningExecutionCount":0}]
Run the Sample with Multiple Files
샘플 스트림을 배포했다면, data/spilt에 들어있는 20개의 파일을 /remote-files 파일에 업로드해보자. task-launcher 로그에서 exponential backoff가 잘 동작하고 있는 것을 확인할 수 있다:
2019-06-14 15:00:48.247 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling period reset to 1000 ms.
2019-06-14 15:00:49.265 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:00:50.433 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:00:51.686 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:00:52.929 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:00:52.929 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 2 seconds.
2019-06-14 15:00:55.008 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:00:55.008 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 4 seconds.
2019-06-14 15:00:59.039 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:00:59.040 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 8 seconds.
2019-06-14 15:01:07.104 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:01:07.104 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 16 seconds.
2019-06-14 15:01:23.127 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling resumed
2019-06-14 15:01:23.128 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:01:23.232 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling period reset to 1000 ms.
2019-06-14 15:01:24.277 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:01:25.483 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:01:26.743 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:01:28.035 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Launching Task fileIngestTask on platform default
2019-06-14 15:01:29.324 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:01:29.325 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 2 seconds.
2019-06-14 15:01:31.435 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:01:31.436 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 4 seconds.
2019-06-14 15:01:35.531 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:01:35.532 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 8 seconds.
2019-06-14 15:01:43.615 WARN 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : The data Flow task platform default has reached its concurrent task execution limit: (3)
2019-06-14 15:01:43.615 INFO 1 --- [pool-2-thread-1] o.s.c.s.a.t.l.d.s.LaunchRequestConsumer : Polling paused- increasing polling period to 16 seconds.
Avoiding Duplicate Processing
sftp 소스는 이미 처리했던 파일은 다시 처리하지 않는다. 런타임에 메세지에서 콘텐츠를 추출하고, 메타데이터 저장소를 이용해 파일들을 추적한다. 기본적으론 인메모리 메타데이터 저장소를 사용하지만, 프로덕션 배포에 활용할 수 있는 영구 저장소에도 연결할 수 있다. 따라서 디폴트 인메모리 저장소를 사용할 땐, 스트림을 재배포하거나 sftp 소스를 재시작하게되면, 이 상태는 손실되고 같은 파일들을 재처리하게 된다.
스프링을 이용하면, 가능한 persistent 메타데이터 저장소 중 하나를 자동 설정해서 중복 처리를 방지할 수 있다.
이 예제에선 이미 JDBC 데이터베이스를 사용하고 있으므로 JDBC 메타데이터 저장소를 자동 설정해본다.
Configure and Build the SFTP Source
JDBC 저장소를 세팅하려면 sftp-dataflow 소스에 몇 가지 JDBC 의존성을 추가해야 한다.
스트림 앱 스타터 sftp를 클론받고, SFTP 디렉토리로 이동해라. 아래 있는 명령어를 <binder>는 각자 설정에 맞게 kafka나 rabbit로 바꾸고 실행해라:
./mvnw clean install -DskipTests -PgenerateApps
cd apps/sftp-dataflow-source-<binder>
pom.xml에 다음과 같은 의존성들을 추가해라:
<dependency>
<groupId>org.springframework.integration</groupId>
<artifactId>spring-integration-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
쿠버네티스에서 실행할 땐 H2 대신 mariadb 드라이버를 사용한다:
<dependency>
<groupId>org.mariadb.jdbc</groupId>
<artifactId>mariadb-java-client</artifactId>
<version>2.3.0</version>
</dependency>
로컬 서버에서 인메모리 H2 데이터베이스를 사용한다면, src/main/resources/application.properties에서 JDBC URL을 Data Flow 서버의 데이터베이스로 설정해라:
spring.datasource.url=jdbc:h2:tcp://localhost:19092/mem:dataflow
쿠버네티스 환경에서 실행한다면, 아래 예시에 보이는 것처럼 데이터 소스를 mysql 서비스의 내부 IP를 사용하도록 설정해라:
spring.datasource.url=jdbc:mysql://10.98.214.235:3306/dataflow
클라우드 파운드리나 쿠버네티스에선 src/main/resources/application.properties에 아래 프로퍼티를 추가해라:
spring.integration.jdbc.initialize-schema=always
이제 sftp 소스를 빌드하고 Data Flow에 등록하면 된다.
Run the Sample App
원하는 플랫폼의 샘플 실행 가이드에 따라 Copy file... 단계까지 완료해라.
메인 실습을 이미 완료해봤다면, 데이터를 초기 상태로 복원하고 스트림을 재배포해라:
- 로컬, 원격 데이터 디렉토리를 비운다.
- 데이터베이스에서 SQL 명령어
DROP TABLE PEOPLE;을 실행한다. - 스트림의 배포를 취소undeploy하고, 업데이트한
sftp소스를 실행하도록 다시 배포한다.
클라우드 파운드리에서 실행한다면, 아래 예시처럼 배포 프로퍼티를 이용해 sftp를 mysql 서비스에 바인딩해라:
dataflow>stream deploy inboundSftp --properties "deployer.sftp.cloudfoundry.services=nfs,mysql"
Copy a File into the Remote Directory
이번엔 작은 파일 하나만 사용해보자. 샘플 프로젝트의 data/split 디렉토리엔 data/name-list.csv를 20개의 파일로 분할해서 저장해놨다. 여기 있는 names_aa.csv 파일을 업로드해라.
Inspect the Database
앞에서 설명했던대로 데이터베이스 툴을 사용해서 INT_METADATA_STORE 테이블에 들어있는 데이터를 조회해보자. 다음과 같은 결과가 보일 거다:
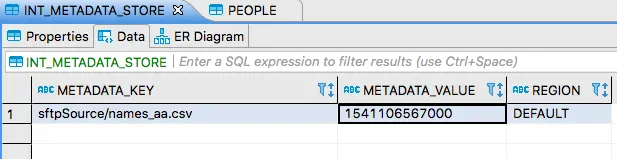
단일 키-값 쌍 저장된 것을 볼 수 있는데, 이 키로 파일 이름을 식별한다 (sftpSource/ 프리픽스는 sftp 소스 앱의 네임스페이스다). 값에는 메세지를 받은 시간을 나타내는 타임스탬프를 저장한다. 메타데이터 저장소는 이렇게 이미 처리를 완료한 파일들을 추적한다. 덕분에 매 폴링 사이클마다 원격 디렉토리에서 같은 파일은 가져오지 않고, 새로 추가된 파일이나 업데이트된 파일만 처리한다.
PEOPLE 테이블엔 유니크 제약 조건이 없기 때문에, 배치 job에서 같은 파일을 여러 번 처리하면 테이블 row에 중복이 생긴다. 여기서는 영구 메타데이터 저장소를 설정했으므로, 컨테이너를 재시작해도 중복 처리를 방지할 수 있다. 스트림을 배포 취소undeploy 후 재배포하거나, sftp 소스를 재시작하면 바로 확인해볼 수 있다.
PEOPLE 테이블을 조회하면 다음과 같은 결과가 보일 거다:
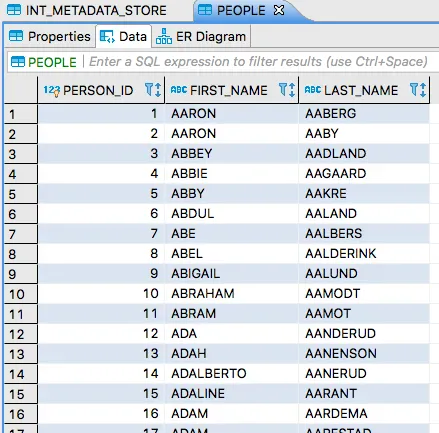
이제 SFTP 서버에 같은 파일을 업로드해보자. SFTP 서버에 로그인했다면 다음과 같이 타임스탬프를 업데이트할 수 있다:
touch /remote-files/names_aa.csv
타임스탬프를 업데이트하면 이 파일은 다시 처리되고, PEOPLE 테이블엔 중복 데이터가 생긴다. ORDER BY FIRST_NAME을 적용하면 다음과 같은 결과가 보일 거다:
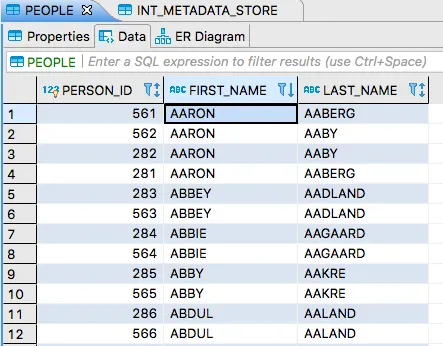
원격 디렉토리에 다른 파일을 하나 더 업로드하면, 이 파일도 처리되고, 메타데이터 저장소엔 또 다른 항목이 보일 거다.
Next : Functional Applications
Functional Applications
functional 기능 관련 레시피 모음집
전체 목차는 여기에 있습니다.